vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
논문 정보
- Date: 2024-01-03
- Reviewer: hyowon Cho
- Property: LLM, Library
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
어느 순간 대규모 언어모델을 사용하는 것은 거의 필수처럼 여겨지고 있다. 우리는 일반적으로 Huggingface Transformers 라이브러리를 이용해, 해당 라이브러리에 있는 LLM을 serving해 사용한다. 하지만 실제로 LLM을 사용하는 것은 심지어 매우 좋은 gpu에서도 굉장히 느리다.
오늘은 fast LLM inference와 serving을 위한 새로운 open-source library, vLLM을 소개한다. 이 라이브러리는 6월 20일 공개된 따끈따끈한 라이브러리이고, UC Berkeley에서 Vicuna를 위해 개발되었다. 이 라이브러리를 사용하면 모델 아키텍쳐의 변화 없이도 HuggingFace Transformers보다 24배나 높은 throughput을 얻을 수 있다.
Beyond State-of-the-art Performance
LLM 라이브러리로는 HuggingFace의 Transformers(HF)와 Text Generation Inference(TGI)가 있다. vLLM과 이 둘의 처리 속도를 비교해보자.
연구진은 두 가지 설정에서 처리 속도를 평가한다: NVIDIA A10G GPU에서 LLaMA-7B와 NVIDIA A100 GPU (40GB)에서 LLaMA-13B 동작.
Transformers는 분당 1자리수 정도의 요청만 처리할 수 있지만, vLLM은 100개 이상의 요청을 처리한다. vLLM은 실제로 Transformers의 24배 처리 속도를 향상하고 있으며, TGI와 비교해도 2.5배의 속도 개선을 보인다.
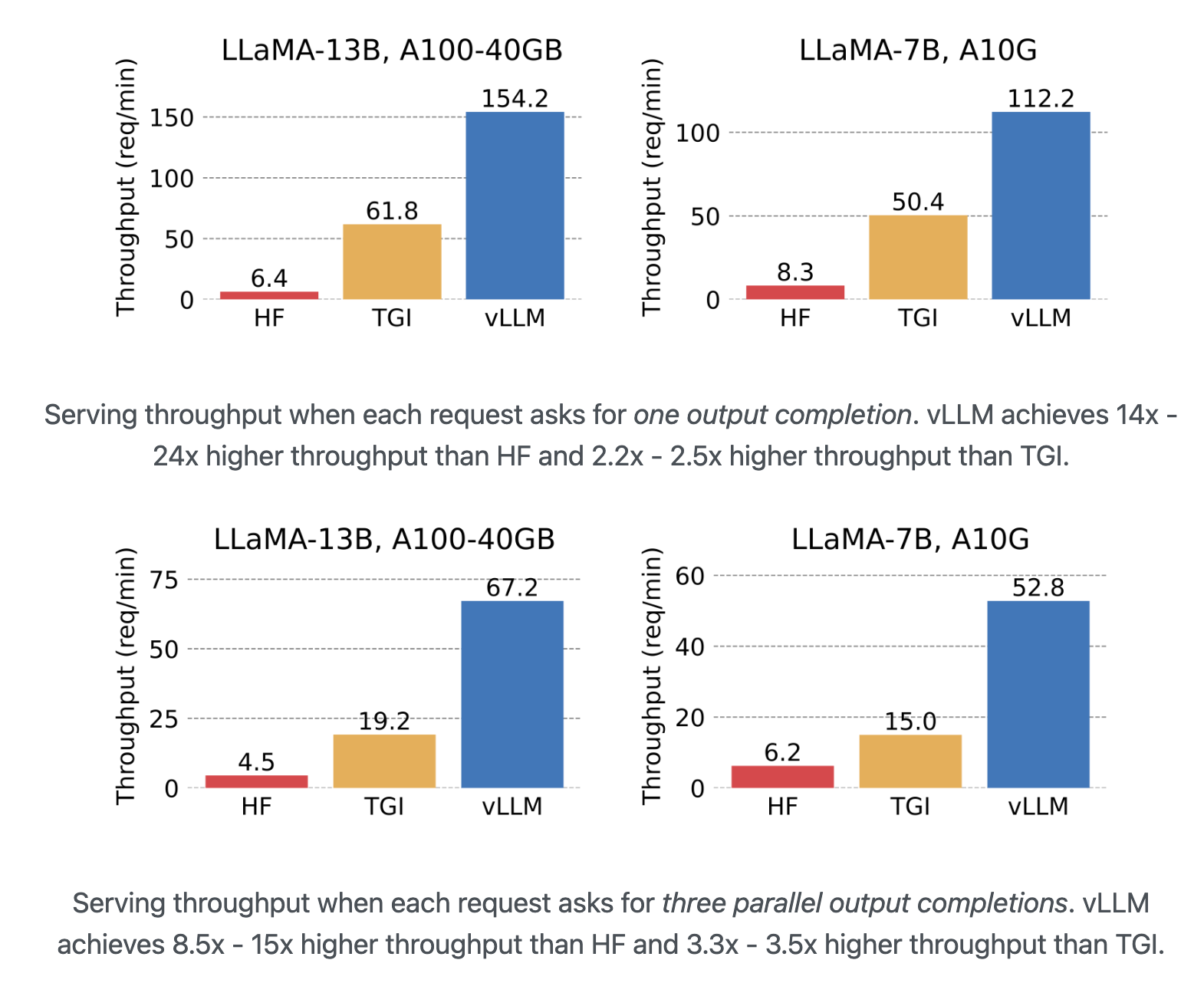
병렬 출력의 테스트에서도 Transformers의 15배, TGI의 3.5배의 속도 개선을 보인다.
The Secret Sauce: PagedAttention
이러한 처리 속도의 향상을 달성할 수 있었던 것은, 대규모 언어 모델의 처리 과정에서 메모리 병목현상을 발견했기 때문이다.
autoregressive decoding 과정에서 LLM의 모든 입력 토큰은 어텐션 key와 value 텐서를 생성하며, 이러한 텐서는 다음 토큰을 생성하기 위해 GPU 메모리에 유지된다. 이 캐시된 key와 value 텐서는 일반적으로 KV 캐시라고 불린다. KV 캐시는 다음과 같은 특징을 가지고 있다.
-
크기가 매우 크다: LLaMA-13B의 단일 시퀀스에 대해 최대 1.7GB의 공간을 차지한다.
-
동적이다: KV캐시의 사이즈는 문장의 길이에 의지한다. 하지만, 대규모 언어 모델이 얼마나 문장을 출력할지 예측할 수 없기 때문에, 메모리의 효율적인 관리가 어렵다. 기존 시스템에서는 fragmentation과 over-reservation으로 인해 메모리의 60%에서 80%가 낭비된다.
이 문제를 해결하기 위해 연구진은 OS의 가상 메모리와 페이징 구조를 참고하여 어텐션 계산시 효율적으로 메모리를 취급할 수 있는 구조인 PagedAttention을 개발한다.
기존의 어텐션 알고리즘과 달리 PagedAttention은 연속적인 key와 value들을 연속하지 않은 메모리 공간에 저장할 수 있도록 한다. 즉, 각 입력 토큰을 일정 길이로 분할 취급하여 연속된 KV 캐시를 불연속 메모리 공간에 저장한다.
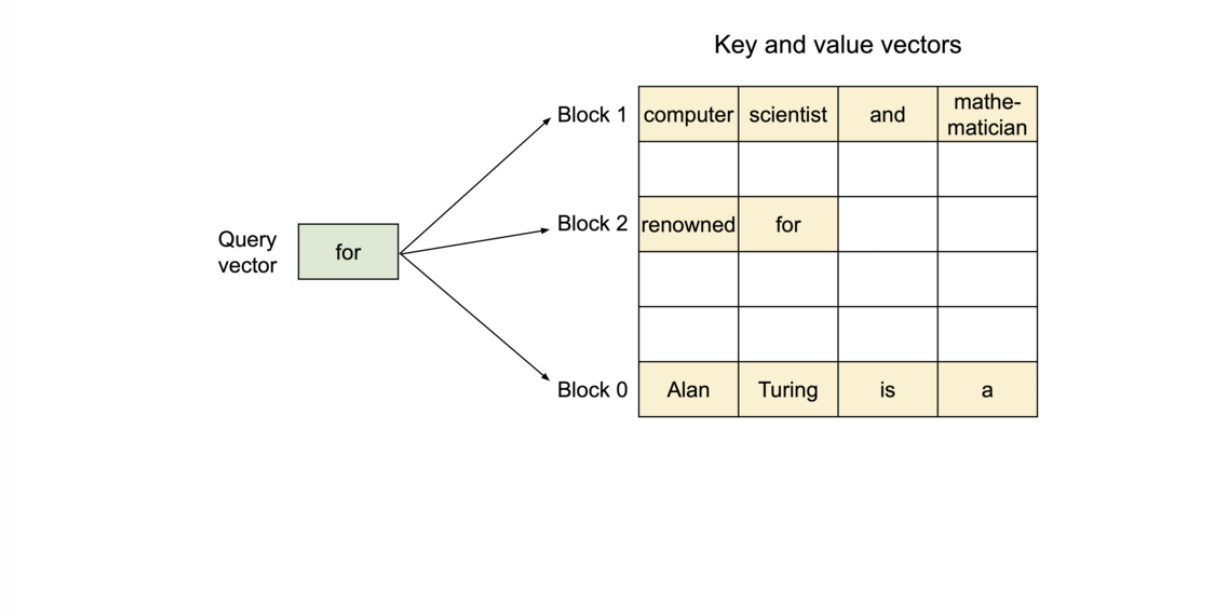
구체적으로, PagedAttention은 각 시퀀스의 KV 캐시를 블록으로 나누고, 각 블록은 고정된 수의 토큰에 대한 key와 value들을 가진다. 어텐션 연산 중에 PagedAttention 커널은 이러한 블록을 효율적으로 식별하고 가져온다.
블록 테이블을 이용하는 것으로, 물리 메모리상에서는 완전 멀어진 장소에 있는 블록들을 마치 연속된 것처럼 취급할 수 있다.
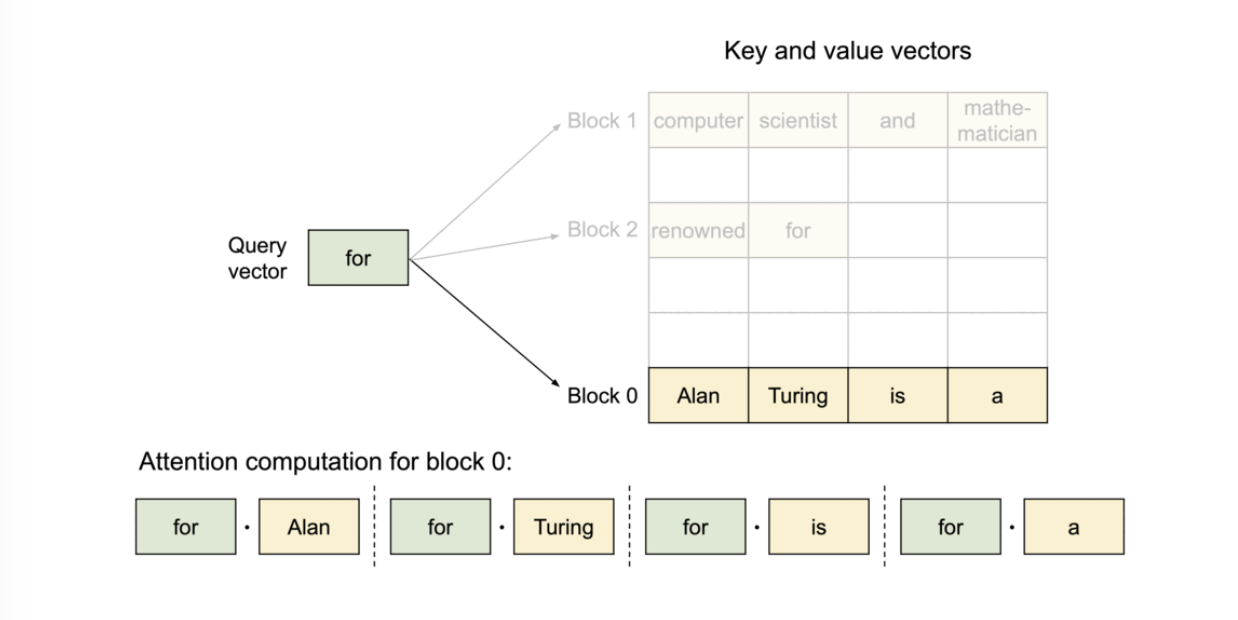
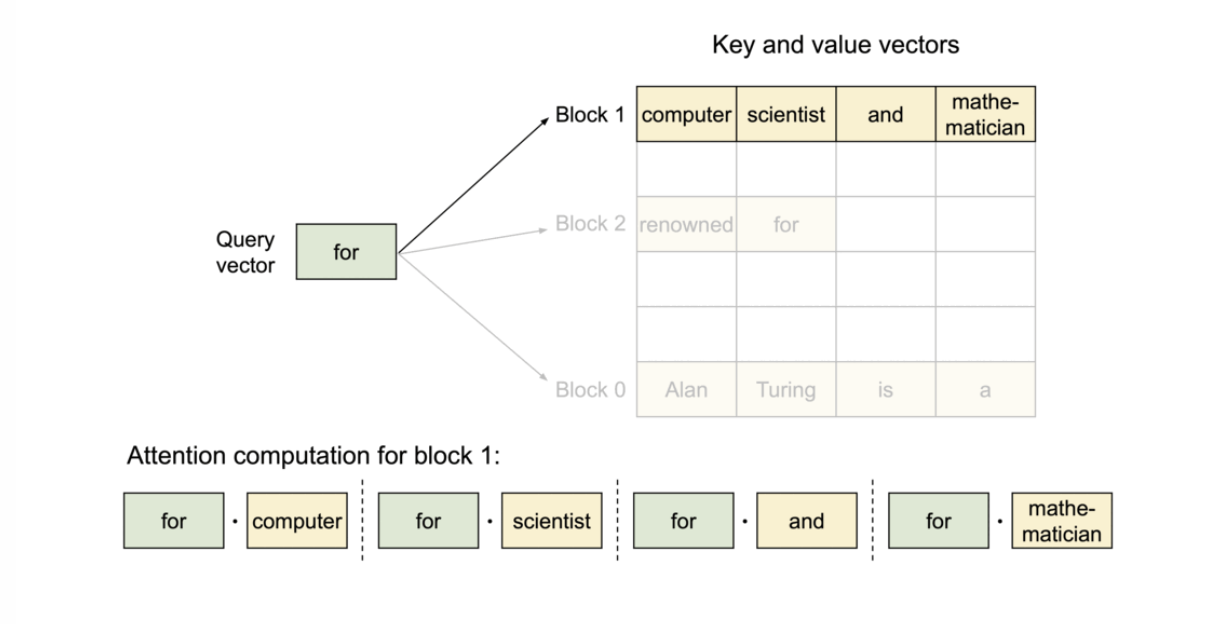
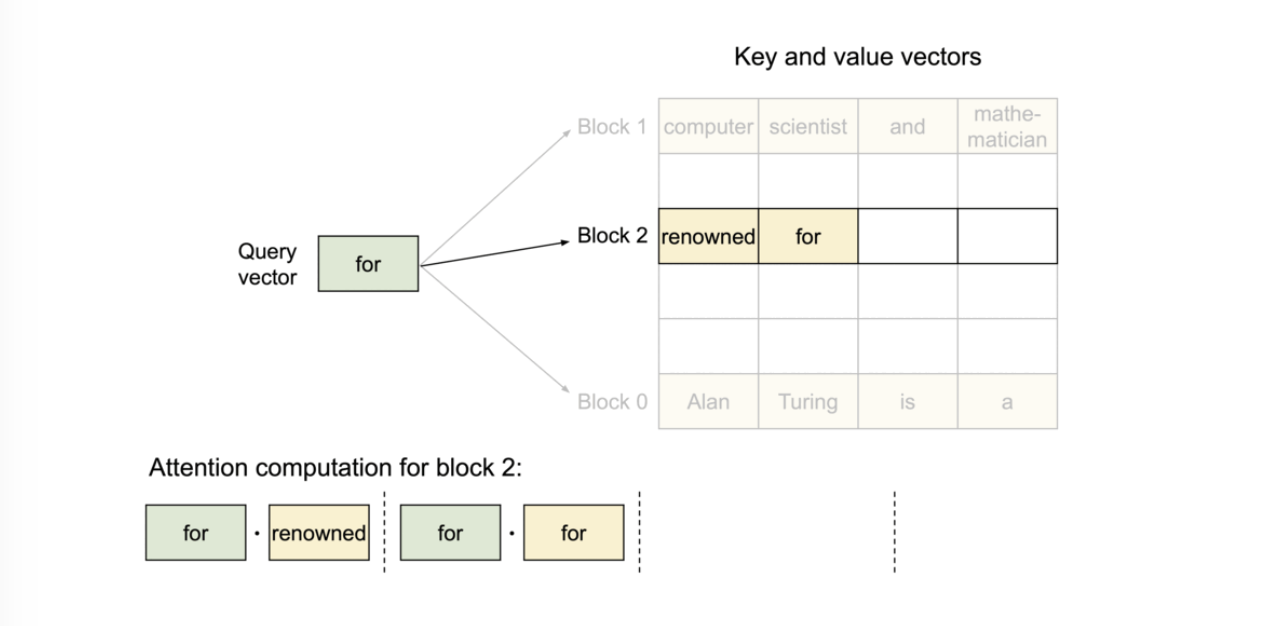
block은 메모리에서 연속적이지 않아도 되기 때문에, 우리는 OS의 가상 메모리와 유사한 유연한 방식으로 키와 값을 관리할 수 있다. 시퀀스의 연속된 logical block은 블록 테이블을 통해 비연속적인 physical block에 매핑된다. 새로운 토큰이 생성될 때마다 physical block이 요구에 따라 할당된다.
Example generation process for a request with PagedAttention.
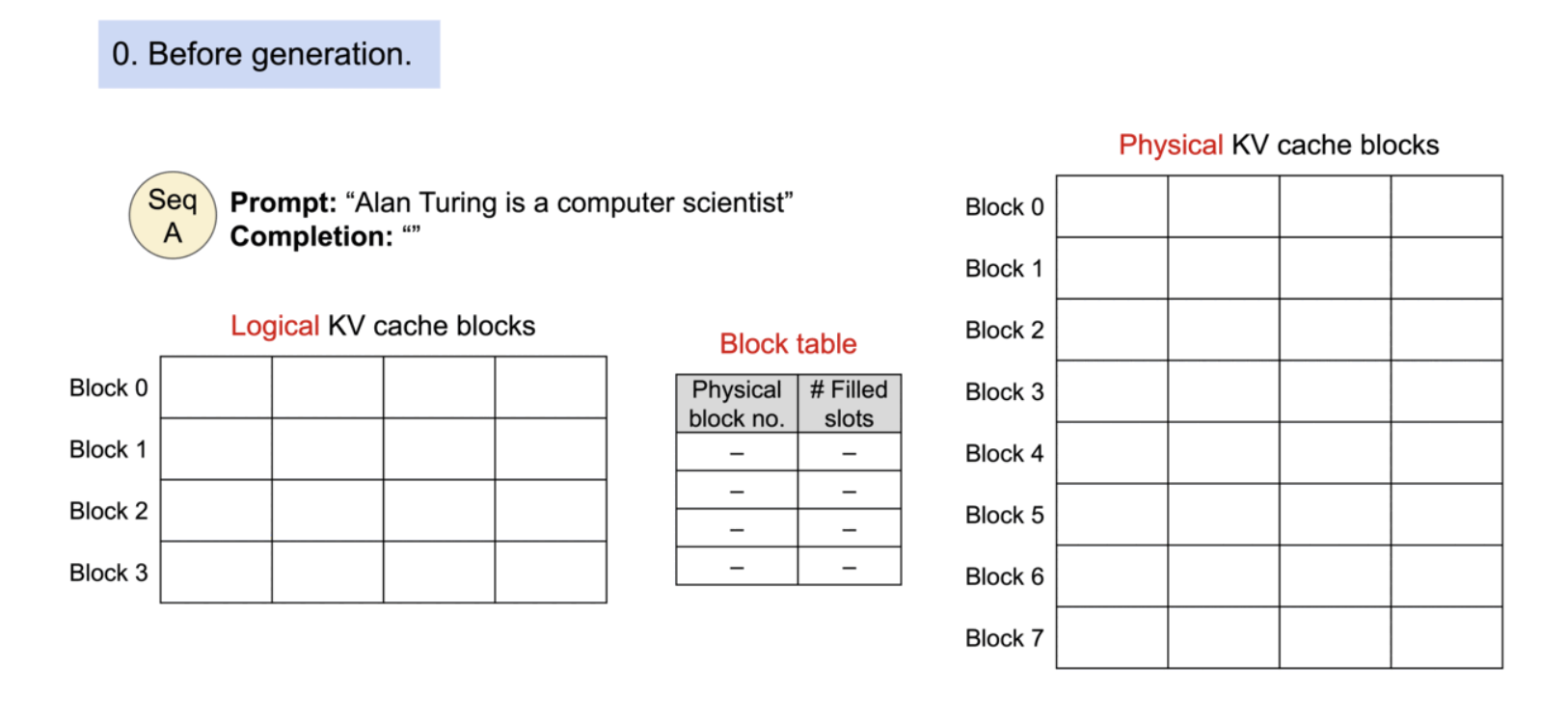
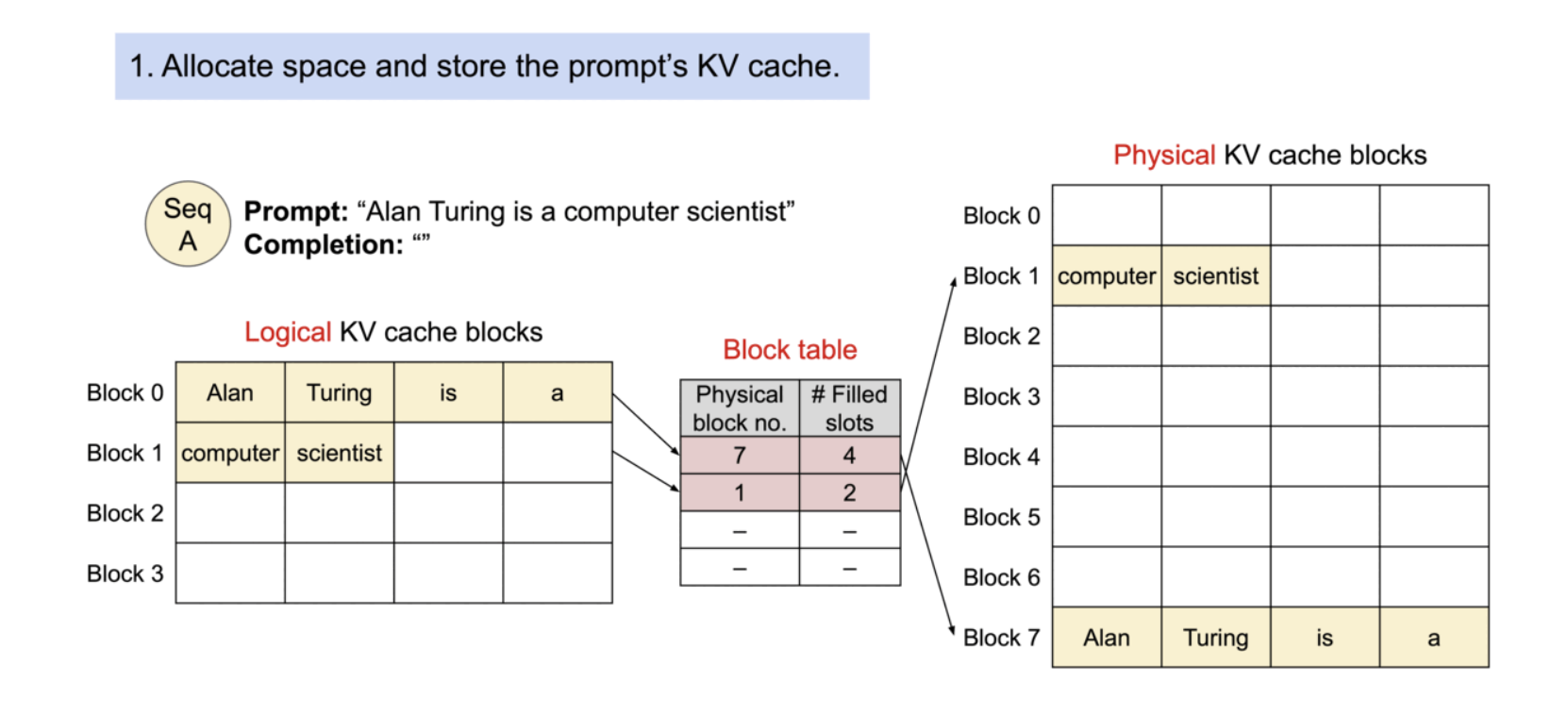
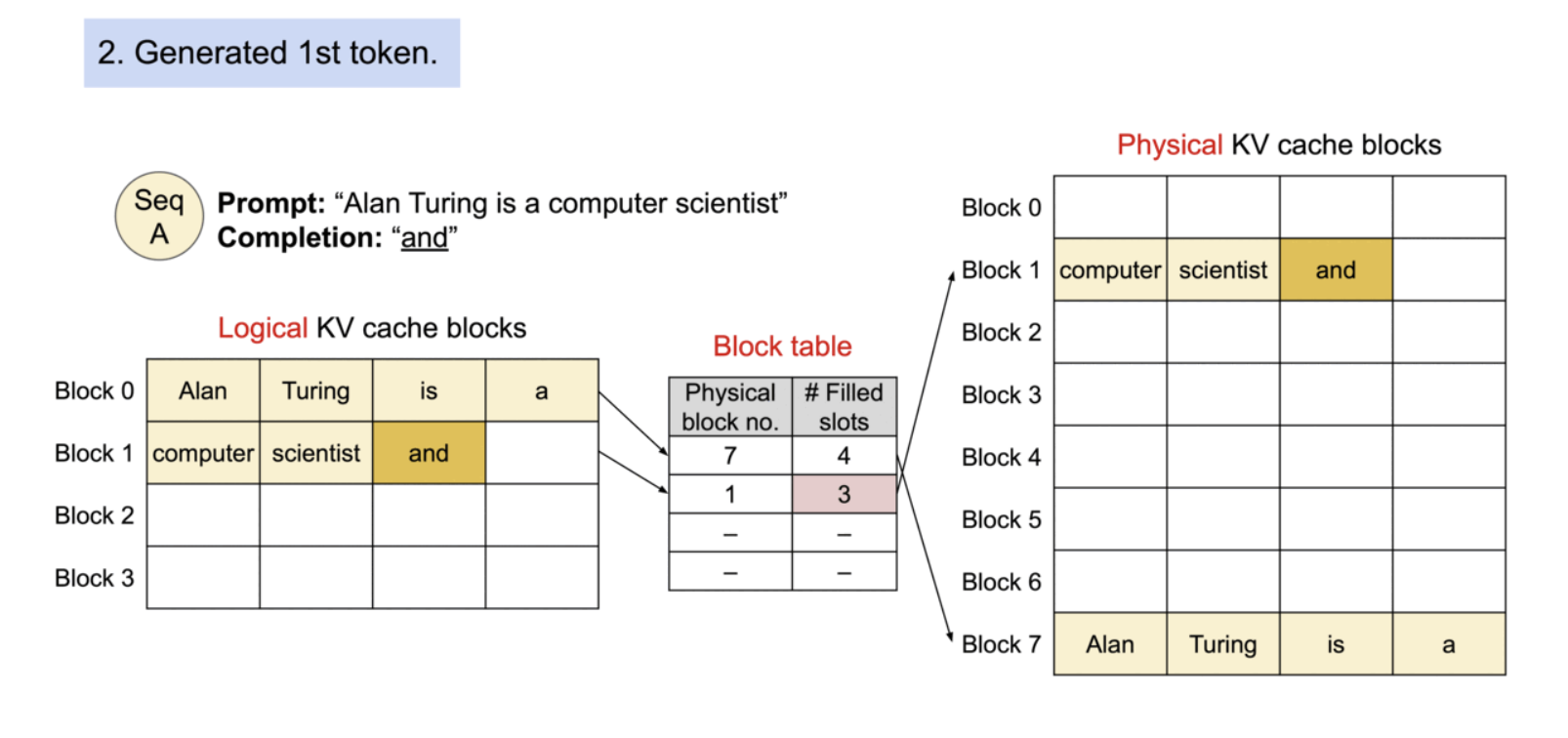
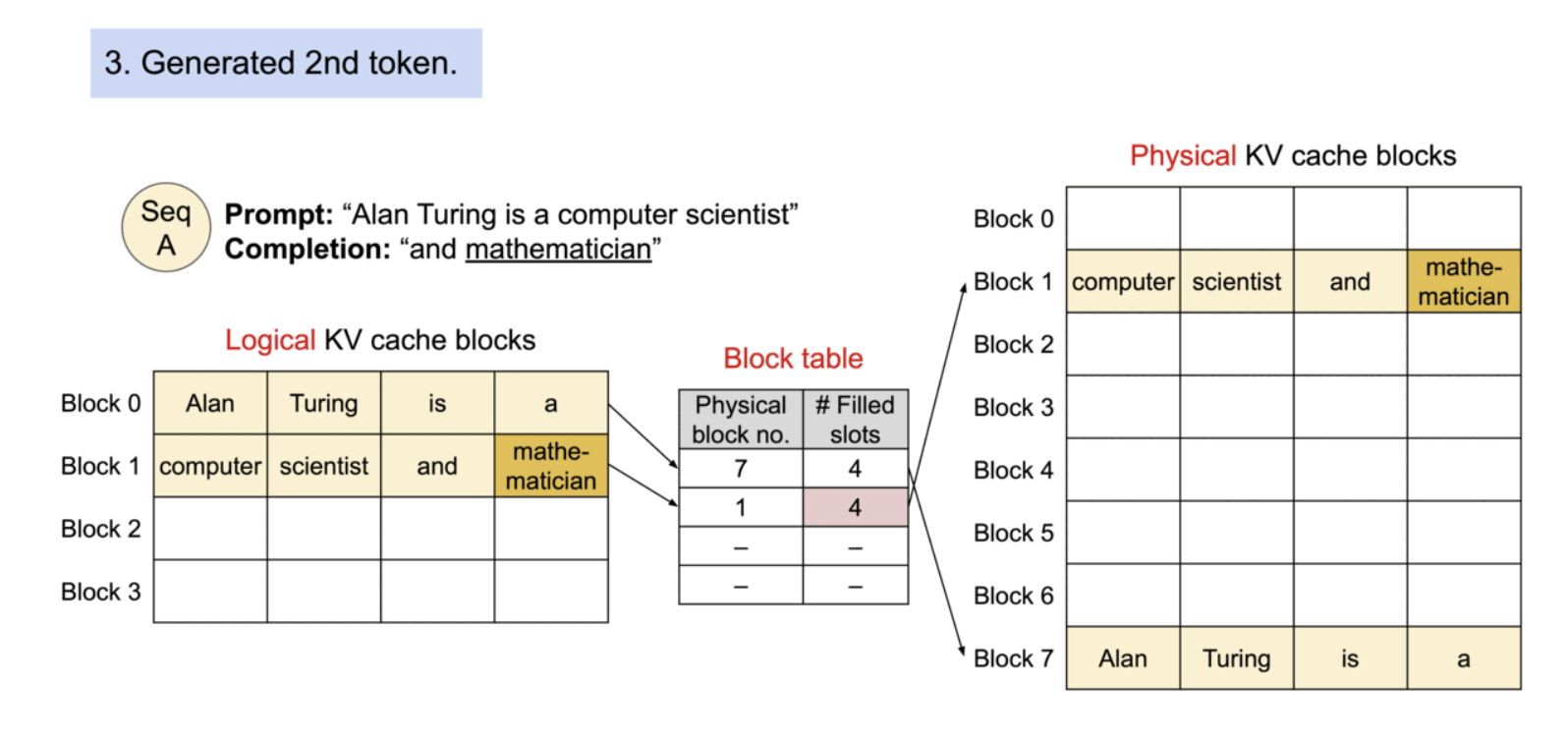

필요에 따라 새로운 메모리 블록이 할당되는 과정. PagedAttention에서는 메모리 낭비가 시퀀스의 마지막 블록에서만 발생. 이렇게 함으로써 점유 후 낭비되는 메모리의 양을 1블록 이내에 담을 수 있다. 실제로 이는 거의 최적의 메모리 사용률을 보장하여 약 4% 미만의 낭비만 발생한다.
메모리 효율이 향상되어 동시에 많은 요청을 일괄 처리할 수 있어, GPU의 사용 효율이 향상되고 처리 속도의 개선으로 이어진 것이다.
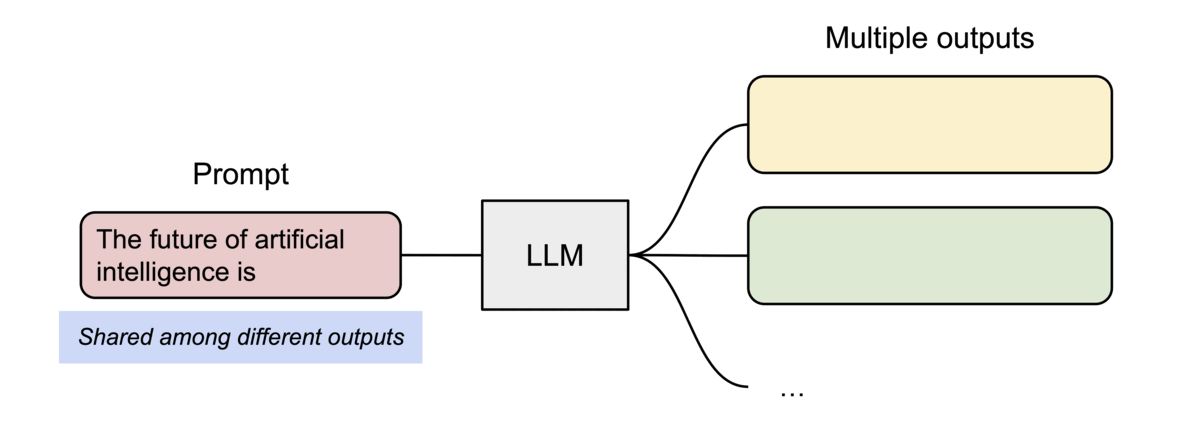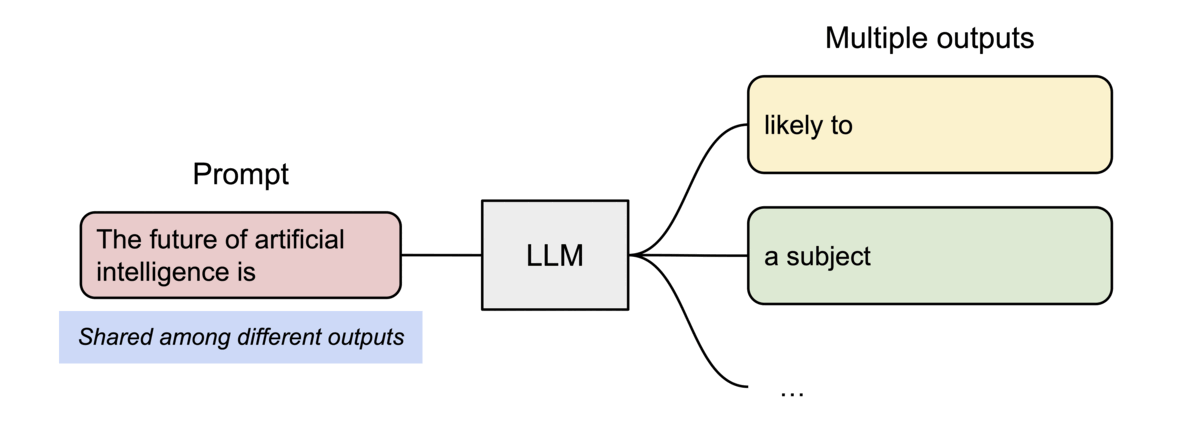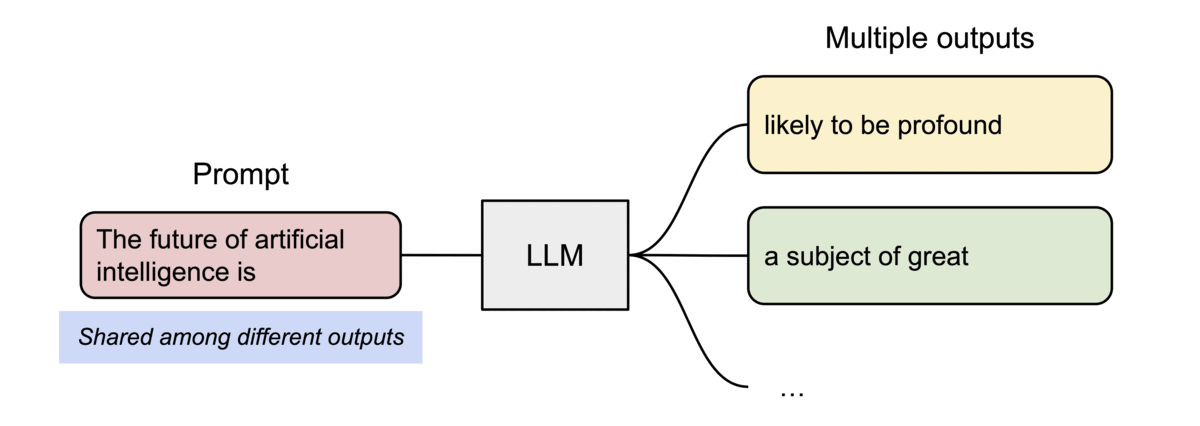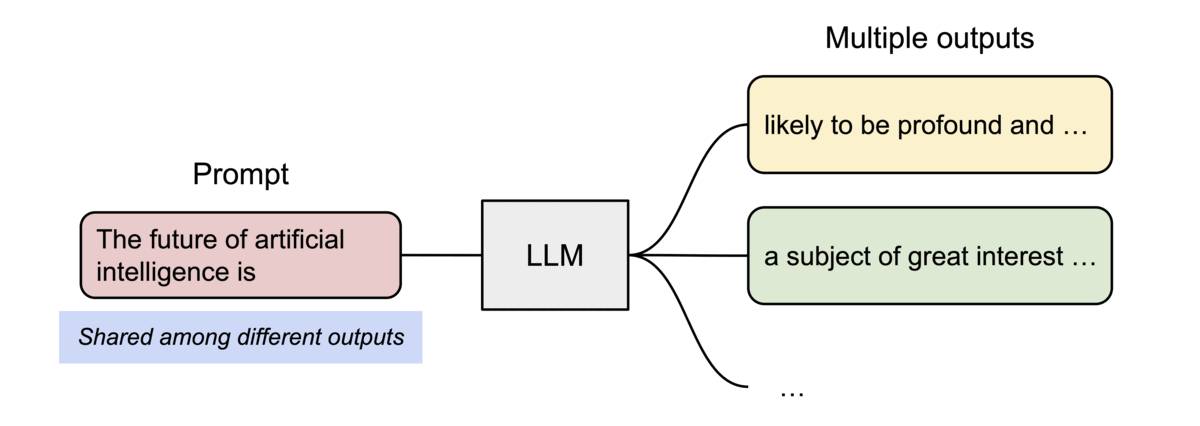
PagedAttention의 또 다른 주요한 이점은 효율적인 메모리 공유이다. 예를 들어, 병렬 샘플링에서는 동일한 프롬프트로부터 여러 개의 출력 시퀀스가 생성되는데, 이 경우, 프롬프트에 대한 연산과 메모리는 출력 시퀀스들 사이에서 공유될 수 있다. 즉, PagedAttention을 사용하면 여러 출력을 동시에 처리할 때 메모리 효율성을 높일 수 있다.
구체적으로는, 프로세스가 physical page를 공유하는 것과 유사하게, PagedAttention에서는 메모리 블록 단위로 공통되는 부분의 참조를 같은 physical block으로 하는 것으로, 같은 내용을 중복해서 여러 번 메모리에 보존해 버리는 문제를 해소하고 있다. 또, 생성 시에는 피참조의 수를 확인해, 복수의 참조가 있는 경우에는 새로운 블록에 내용을 카피해 기입을 실시하는 것으로 트러블을 막을 수 있도록 한다.
- Copy-on-Write
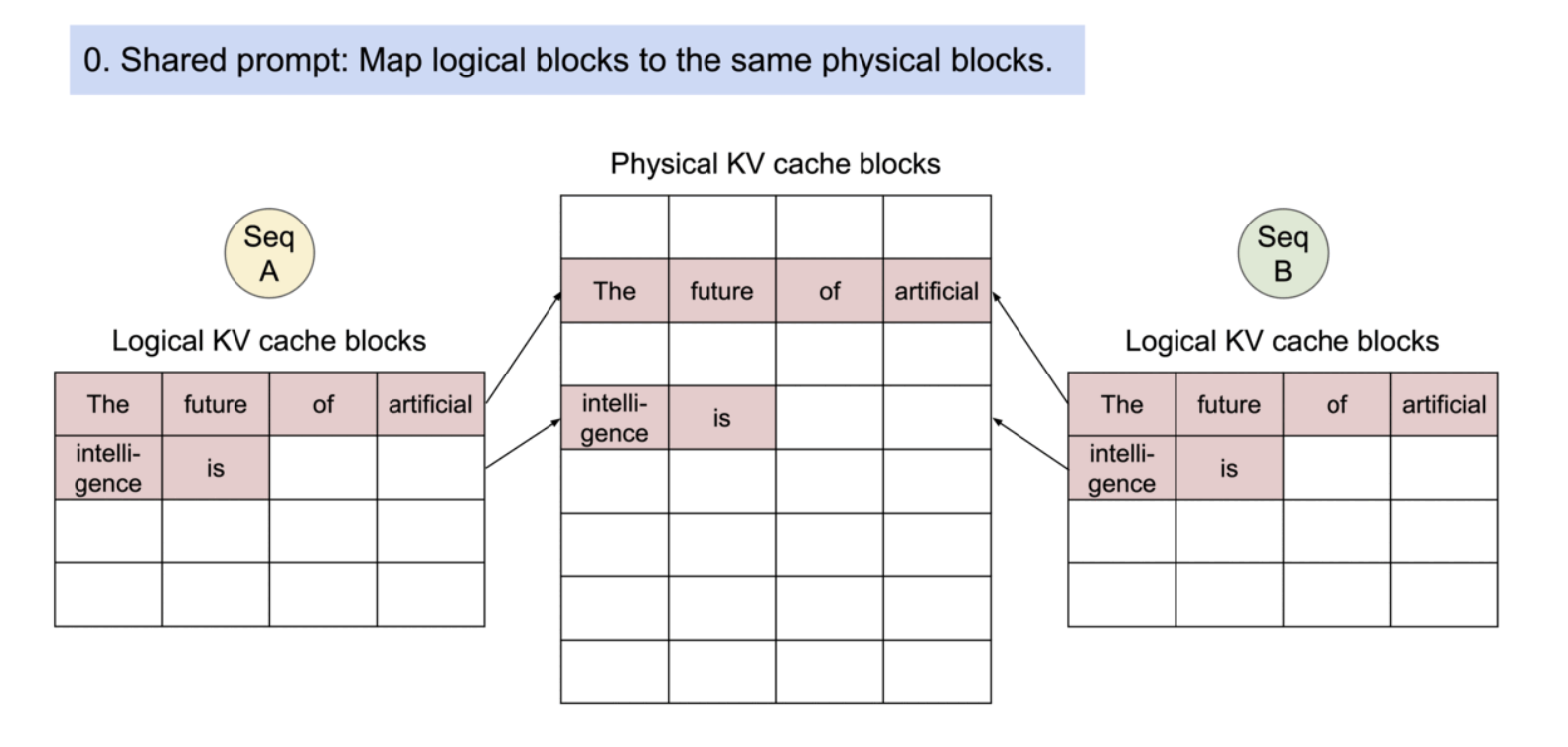
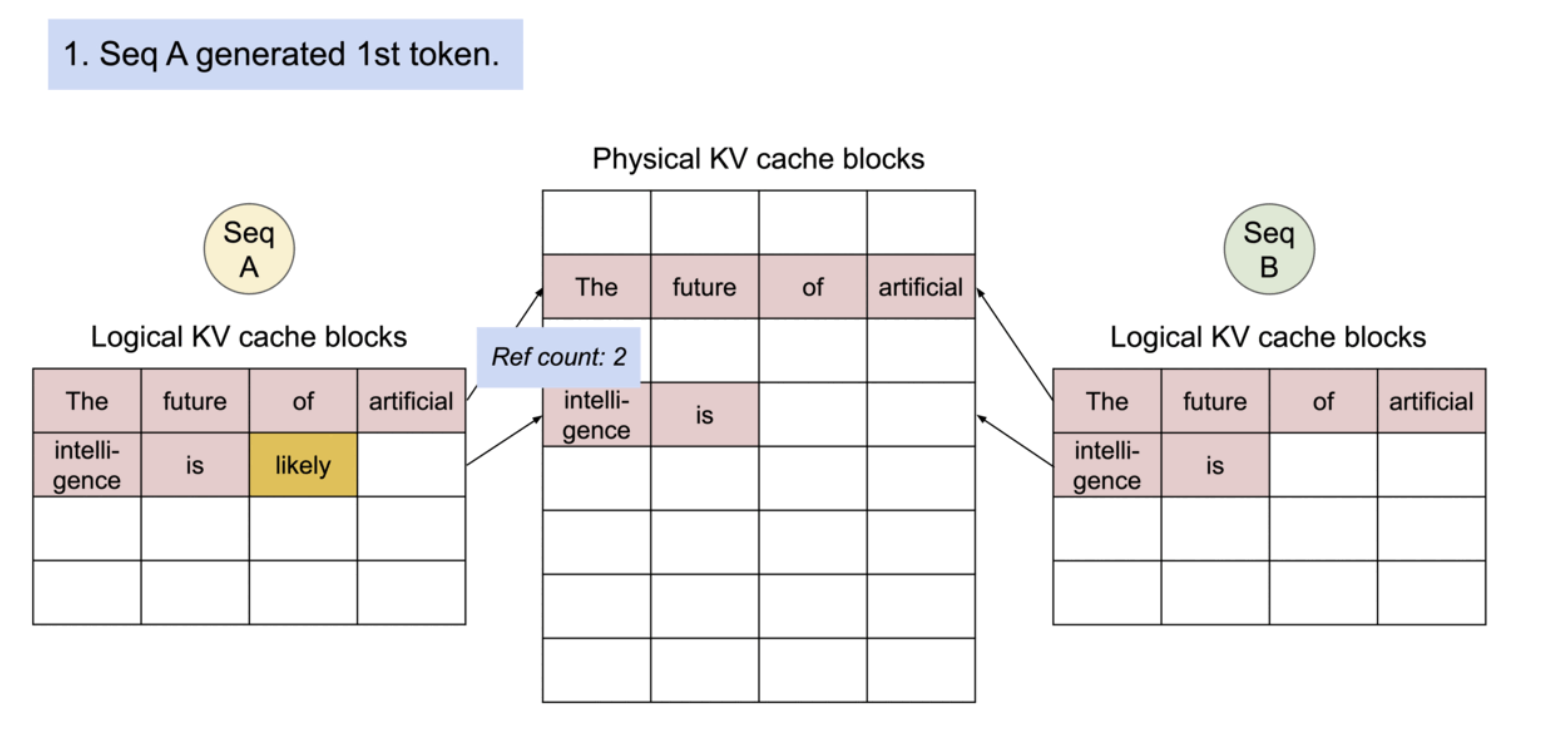
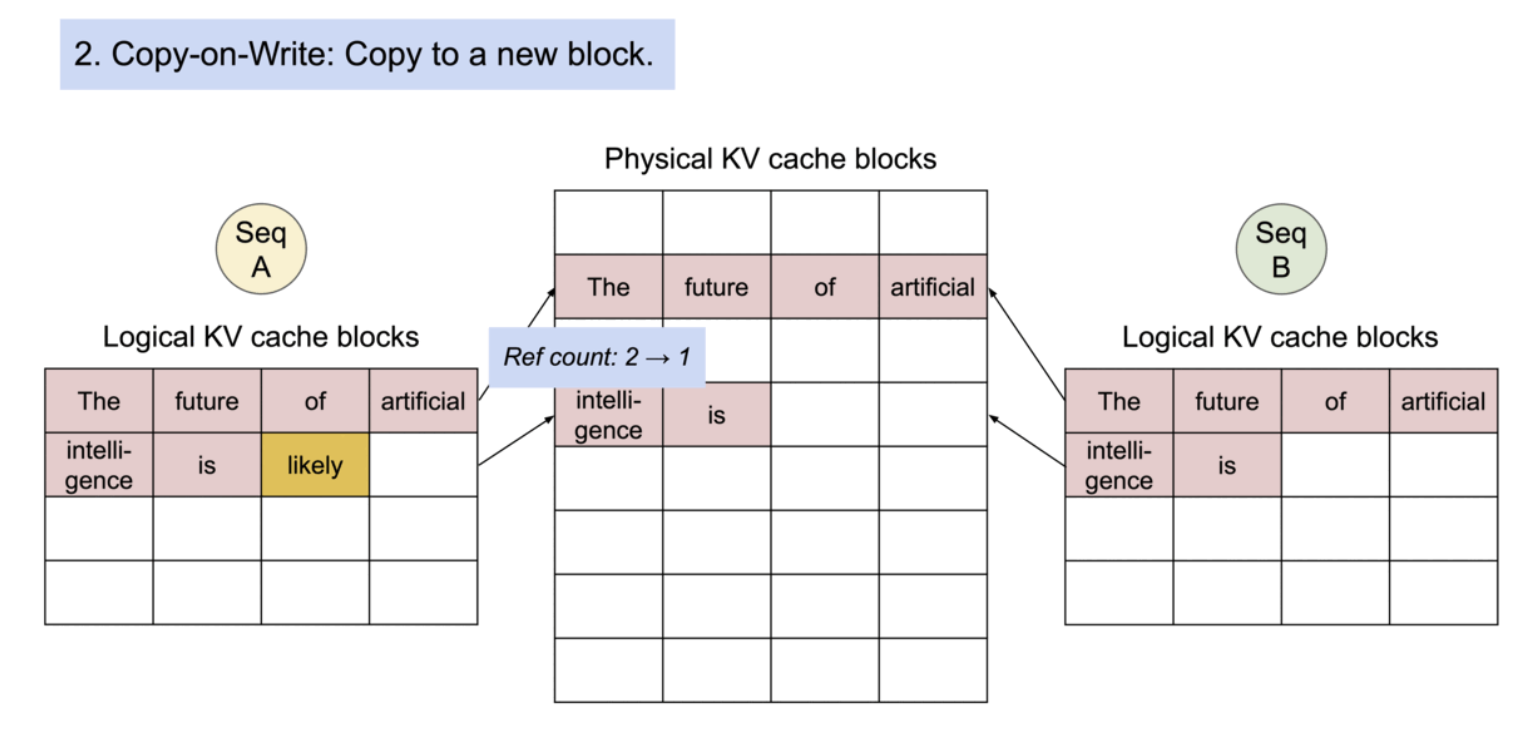
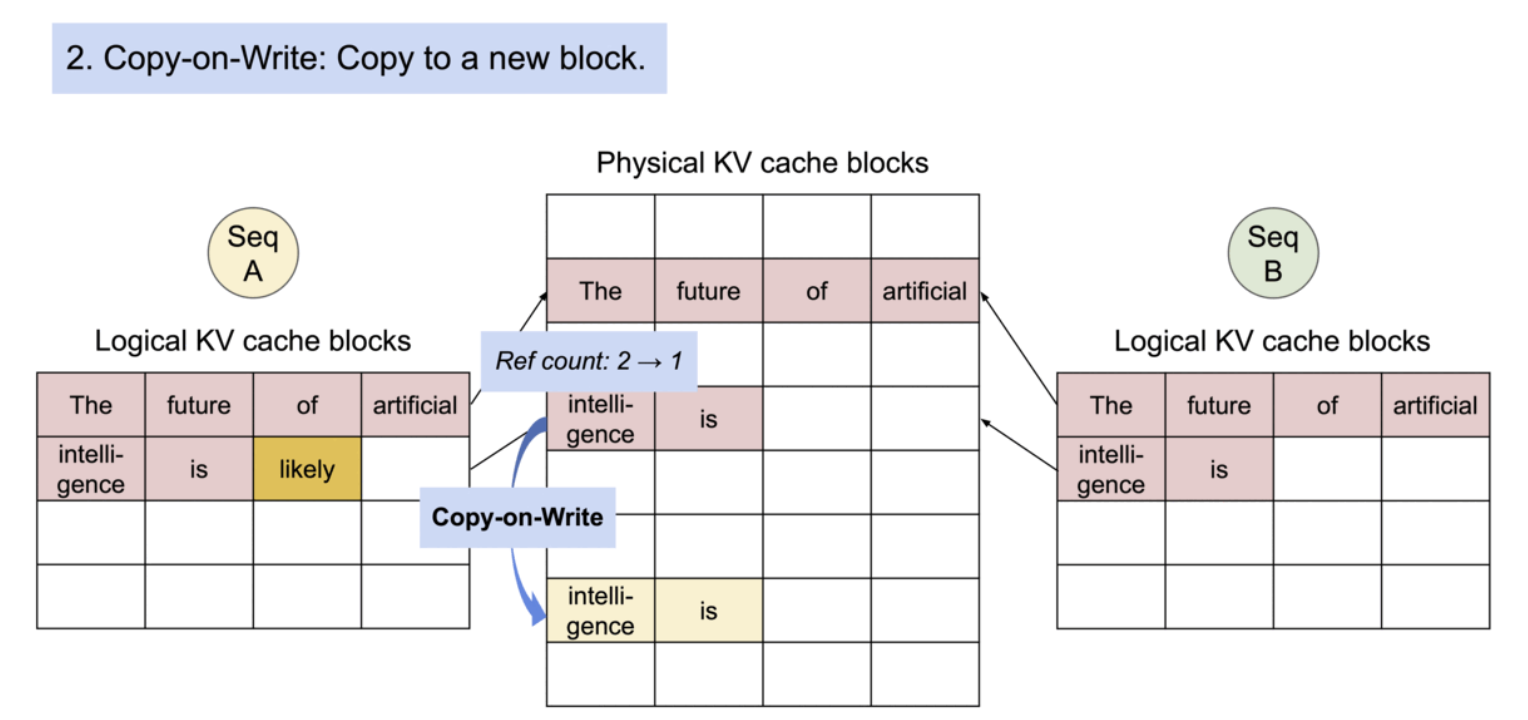
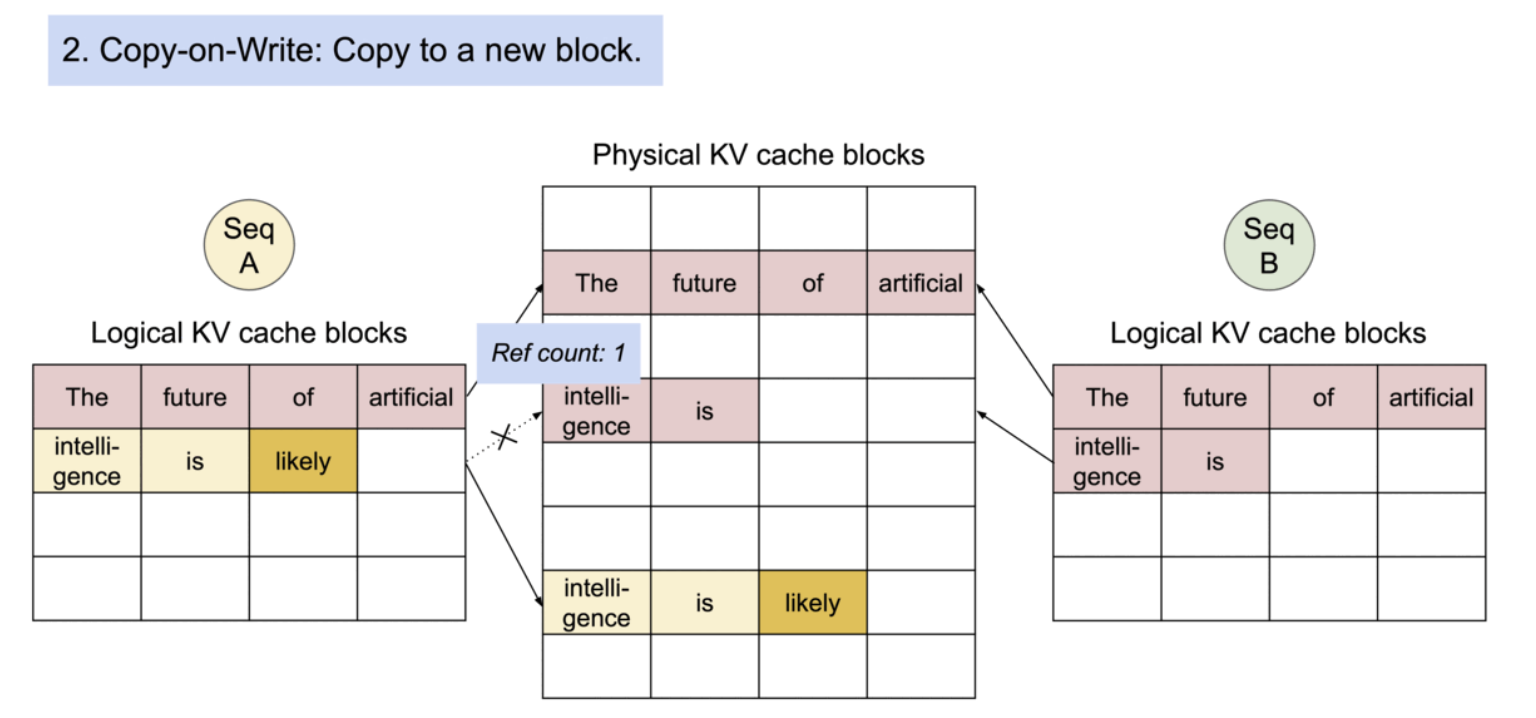
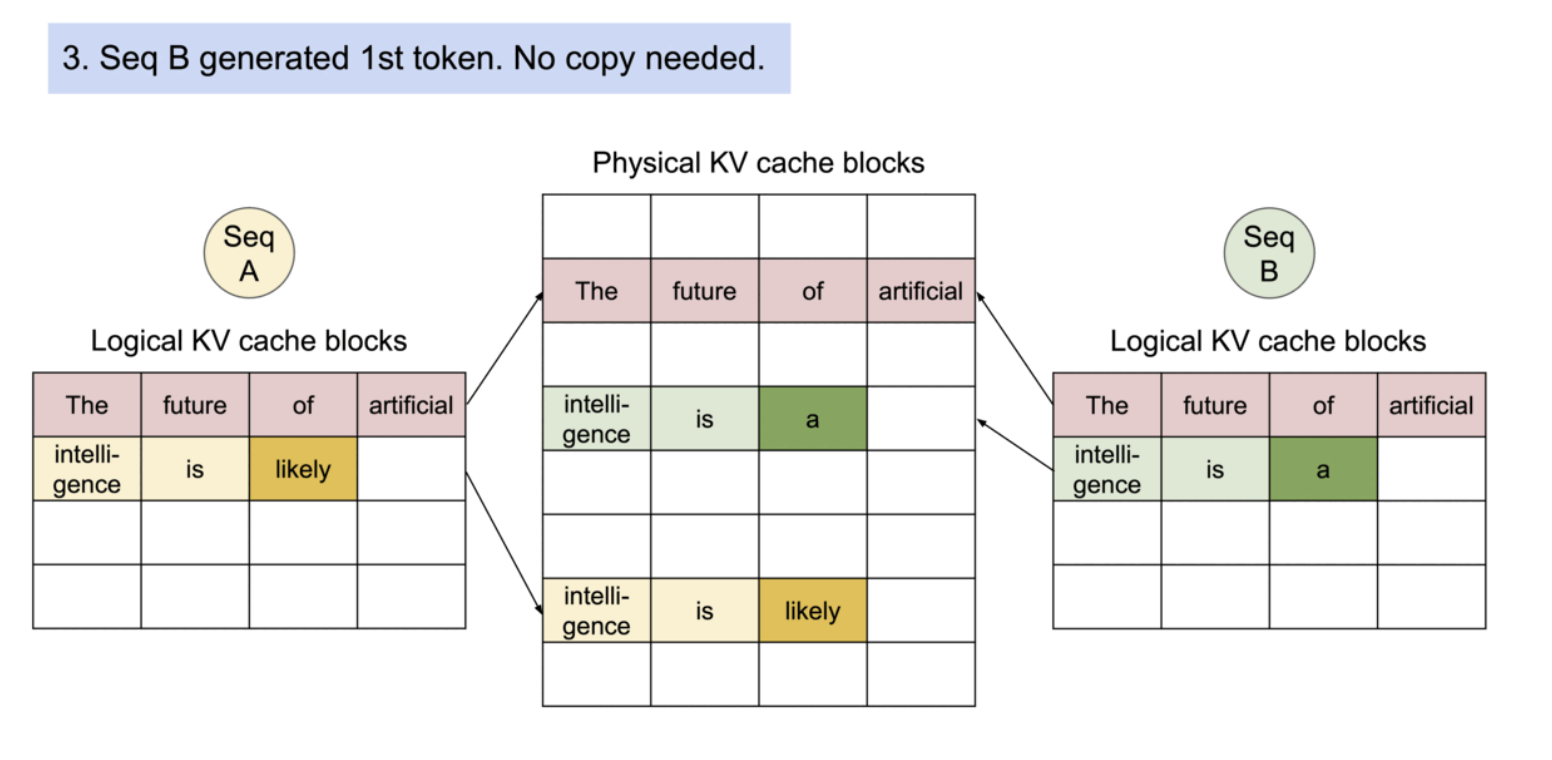
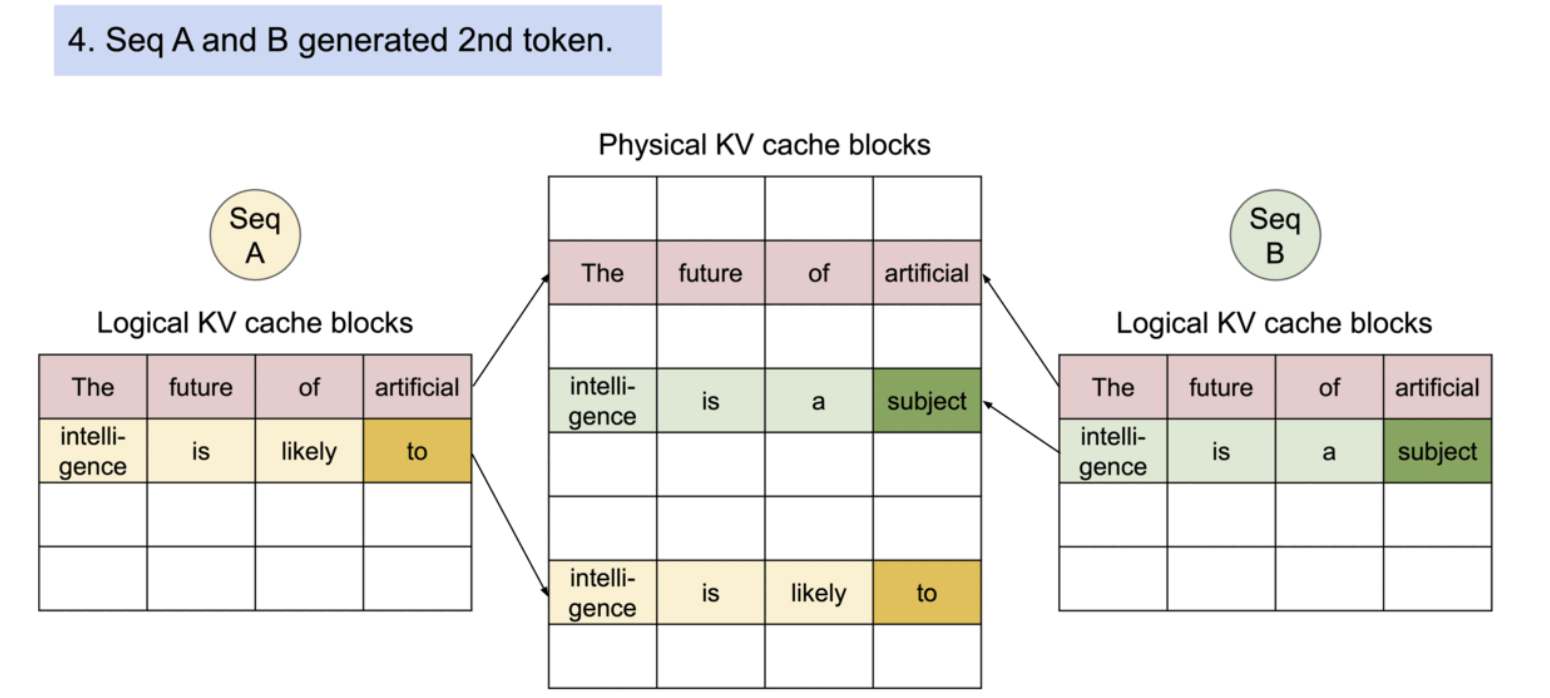
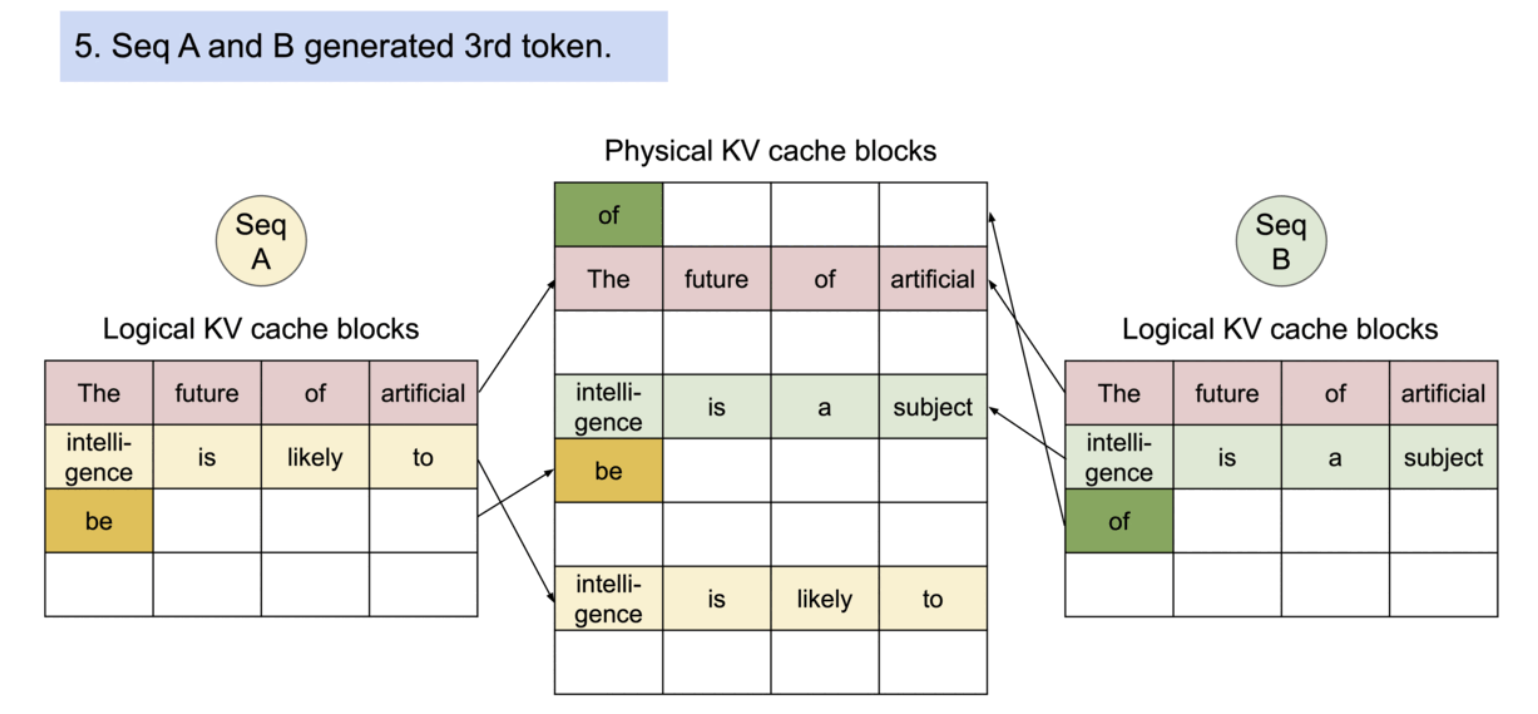
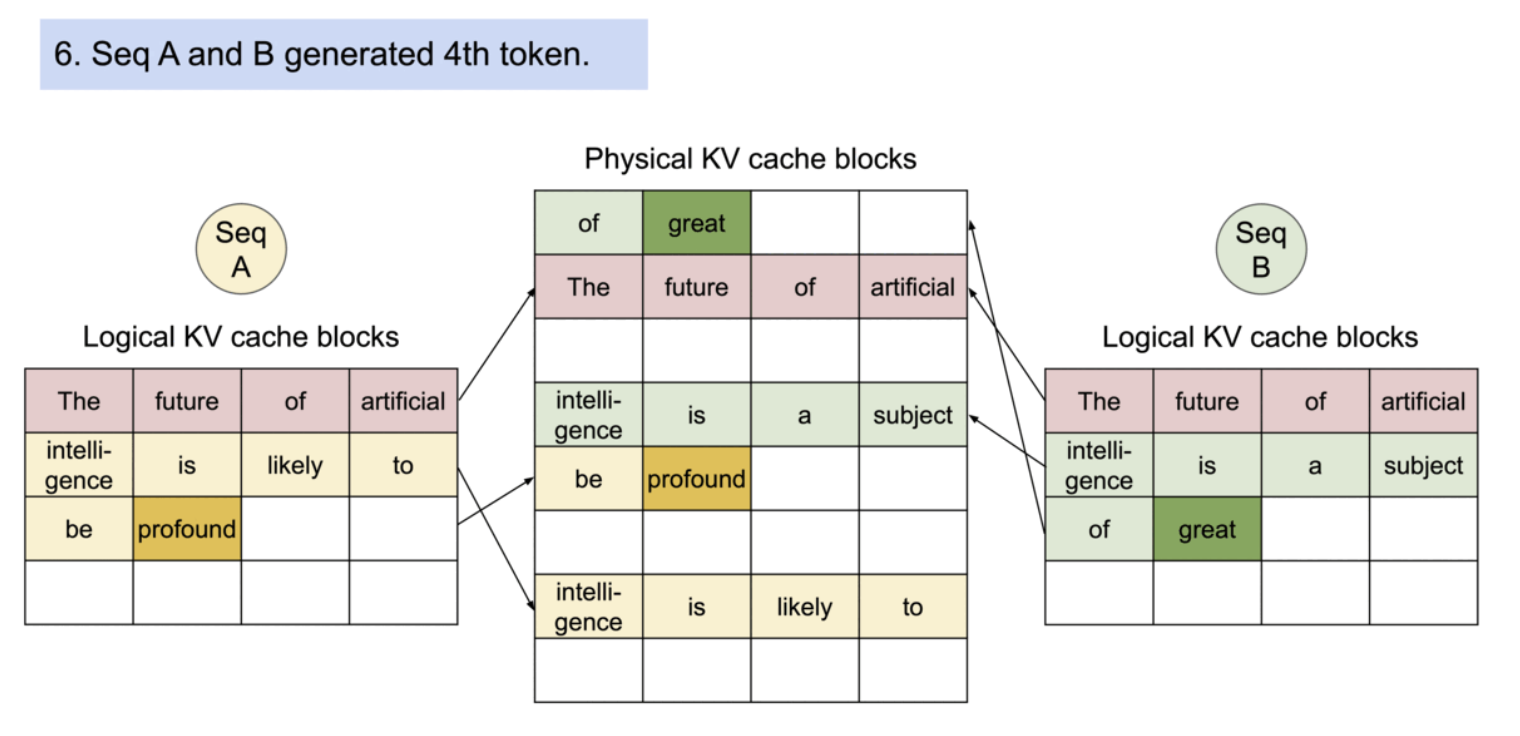
PagedAttention의 메모리 공유는 병렬 샘플링과 빔 서치와 같은 복잡한 샘플링 알고리즘의 메모리 오버헤드를 크게 줄인다. 이로 인해 메모리 사용량이 최대 55%까지 감소할 수 있으며, 이는 최대 2.2배의 처리량 향상으로 이어질 수 있다.
The Silent Hero Behind LMSYS Vicuna and Chatbot Arena
Vicuna 챗봇 연구진은 새로운 백엔드로 vLLM을 사용하여 초기 HF 백엔드와 비교하여 최대 30배 더 높은 처리량을 달성할 수 있다는 것을 확인한다.
vLLM을 이용함으로써 GPU의 필요를 50% 삭감한 것 외에도 매일 3만 건에서 피크타임 6만 건의 요청을 문제없이 처리할 수 있다는 것으로, vLLM의 안정성을 뒷받침한다.
Currently Supported Models

Get started with vLLM
```plain text from vllm import LLM, SamplingParams
prompts = [ “Hello, my name is”, “The president of the United States is”, “The capital of France is”, “The future of AI is”, ] sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model=”facebook/opt-125m”)
outputs = llm.generate(prompts, sampling_params)
Print the outputs.
for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f”Prompt: {prompt!r}, Generated text: {generated_text!r}”)
### OpenAI-Compatible Server
```plain text
python -m vllm.entrypoints.openai.api_server \\
--model facebook/opt-125m \\
--tensor-parallel-size 4 # distributed inference
By default, it starts the server at http://localhost:8000
```plain text import openai
Modify OpenAI’s API key and API base to use vLLM’s API server.
openai.api_key = “EMPTY” openai.api_base = “http://localhost:8000/v1” completion = openai.Completion.create(model=”facebook/opt-125m”, prompt=”San Francisco is a”) print(“Completion result:”, completion)
```