WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia
논문 정보
- Date: 2024-02-20
- Reviewer: 김재희
- Property: Retrieval, ICL, QA, Knowledge
1. Intro
Wikipedia 기반 Knowledge Grounded Conversation 특화 언어모델
-
LLM : Hallucination 현상이 매우 심함
-
잘못된 Implicit Knowledge를 이용한 답변
-
모델의 학습 이후 시점의 정보와 관련된 질문
-
⇒ 기존 접근 방법 : Retrieval-based(RALM) / Knowledge Editing(ROME)
- RALM : Query 관련 정보를 Retrieval하여 추가 정보로 입력하자.

-
Retrieve된 정보가 정확한 지식을 포함한다고 보장 X
-
Retrieve된 정보를 입력으로 생성된 문장이 Retrieve된 정보를 충분히 사용하여 생성했다고 보장 X
-
Retrieve된 문장으로 인해 생성 시 사용되는 정보량(Token 수)가 매우 많아짐 —> 생성 난이도 상승/Input Length 제한 발생
-
ROME : 모델의 내부 파라미터를 수정하여 지식을 업데이트하자.
-
걍 어렵다.
-
여전히 안된다.
-
하지만 신기하쥬?
-
-
Knowledge Grounded Task 평가 방식
- 주어진 질문에 대해 모델이 사실 기반 문장을 잘 생성하는지 평가
⇒ Human Annotator를 이용
⇒ 일반적으로 사람들이 잘 알고 있는 지식을 이용하여 데이터셋 구성 → Corpus Distribution 내 Head에 해당하는 내용으로만 평가 진행
- 모델 역시 Head에 해당하는 지식은 학습이 쉬움
⇒ Pretrain Corpus에 자주 등장했기 때문
- 사람도 구축하기 어려운 Tail 지식들을 이용해서 평가하는 것이 중요
**Contribution **1. 광범위한 지식, 그 중에서도 모델 학습 이후 발생하는 지식을 이용한 효과적인 대화 모델 프레임워크 및 평가 방법론 제안 2. Knowledge Base 변경을 통해 개인정보 및 기업 내부 정보에 대해서도 활용 가능
2. Method
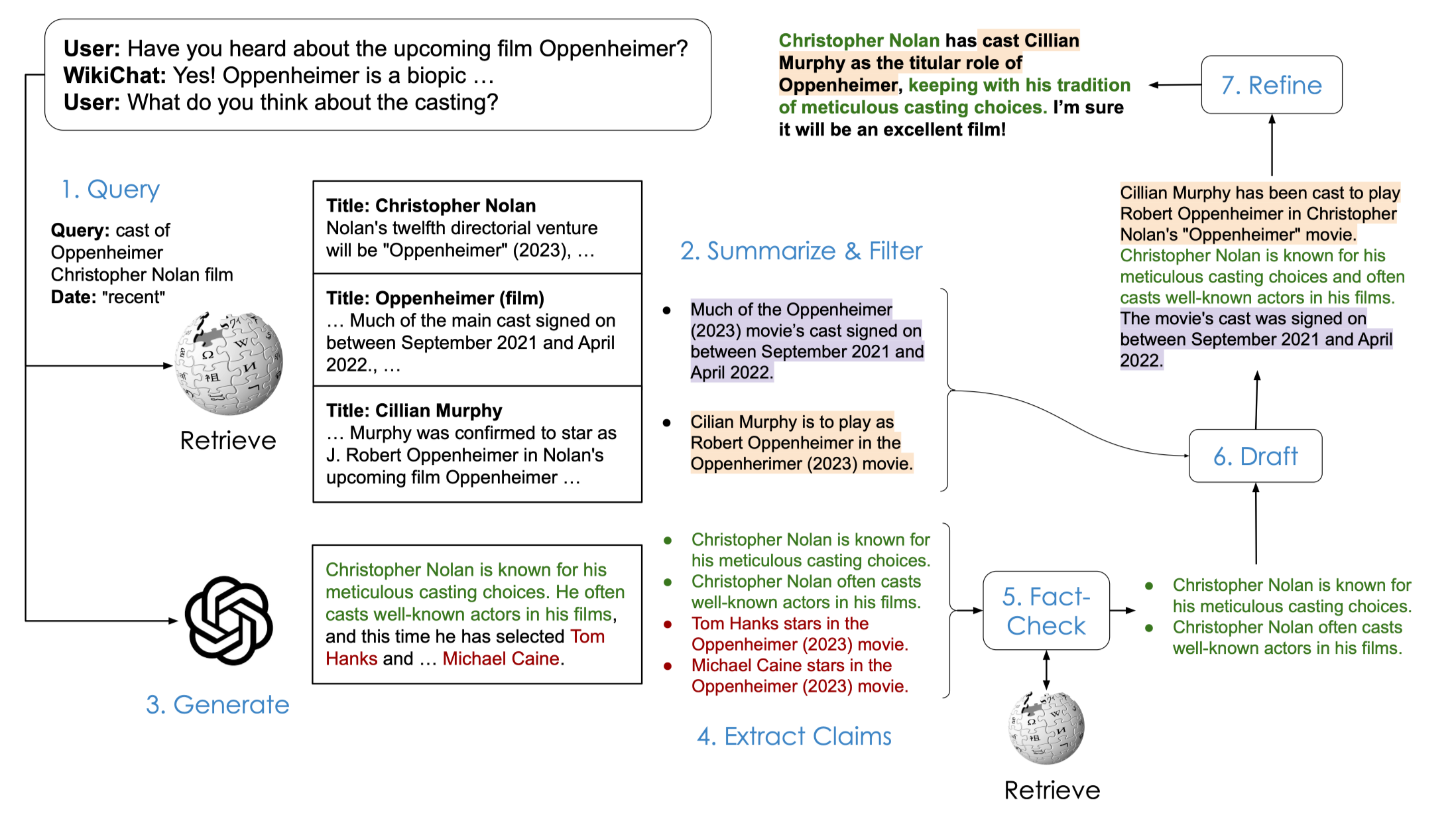
7단계로 구성된 Retrieve-and-Generate Framework → 기존 LLM을 이용하여 Prompting + Retrieval의 결합으로 Knowledge-Grounded Response 생성
-
LLM : GPT-3.5/GPT-4/LLaMA-1
-
Retriever : ColBERT + PLAID(reranker)
1단계 Search Query 작성
-
Retrieval을 위한 Query 작성
-
모든 Turn에 대해 Search를 진행 X
-
Prompting을 통해 모델이 직접 Search 시점 선택
-
-
Input : User Query + history → 특히 입력 정보의 시점을 함께 Prompting

- Retriever가 N_{IR}개의 Passage 반환
2단계 Passage 내 필요 정보 추출
-
Passage에는 현재 User Query와 관련된 정보와 관련없는 정보가 혼재
-
Bullet Point를 통해 Passage의 정보를 요약/필터링하도록 Promping
- K-Shot Prompting 사용

3단계 LLM 단독 Response 생성
- Retrieve된 정보를 이용하지 않고 User Query에 대한 Response 생성
→ 흥미롭고 자연스러운 Response 초안
- 해당 과정에서 생성된 Response는 신뢰도가 낮음

4단계 Response 분해
-
3단계에서 생성된 Response 초안을 Claim 단위로 분해
-
분해 과정에서 발생할 수 있는 Coreference 문제를 해결하도록 Prompting
→ 단순 대명사/호칭/날짜(오늘 → 2024년 02월 20일) 등
-
대화 기준 날짜를 직접 명시하여 날짜에 다른 지식 변화 고려
-
K-Shot Prompting


- 각각의 Claim에 대해 Retriever을 이용하여 N_{evidence}개의 Passage 탐색
5단계 Claim 검증
-
4단계에서 마련된 (claim-passage) tuple을 이용하여 prompting
-
날짜 정보 함께 기재하여 지식 변화 고려
-
K-Shot Prompting
-
CoT prompting
-
-
모델은 각 claim이 (사실, 거짓, 판별불가)인지 분류
→ 사실로 분류된 claim만 향후 사용


6단계 실제 Response 초안 작성
-
5단계에서 사실로 판별된 claim이 있을 경우에만 수행
- 모든 claim이 (판별 불가 or 거짓)이었다면 7단계로 넘어감
-
2단계에서 생성한 passage 요약을 prompting하여 response 생성
-
K-Shot Prompting
-
날짜 정보 함께 기재하여 지식 변화 고려
-

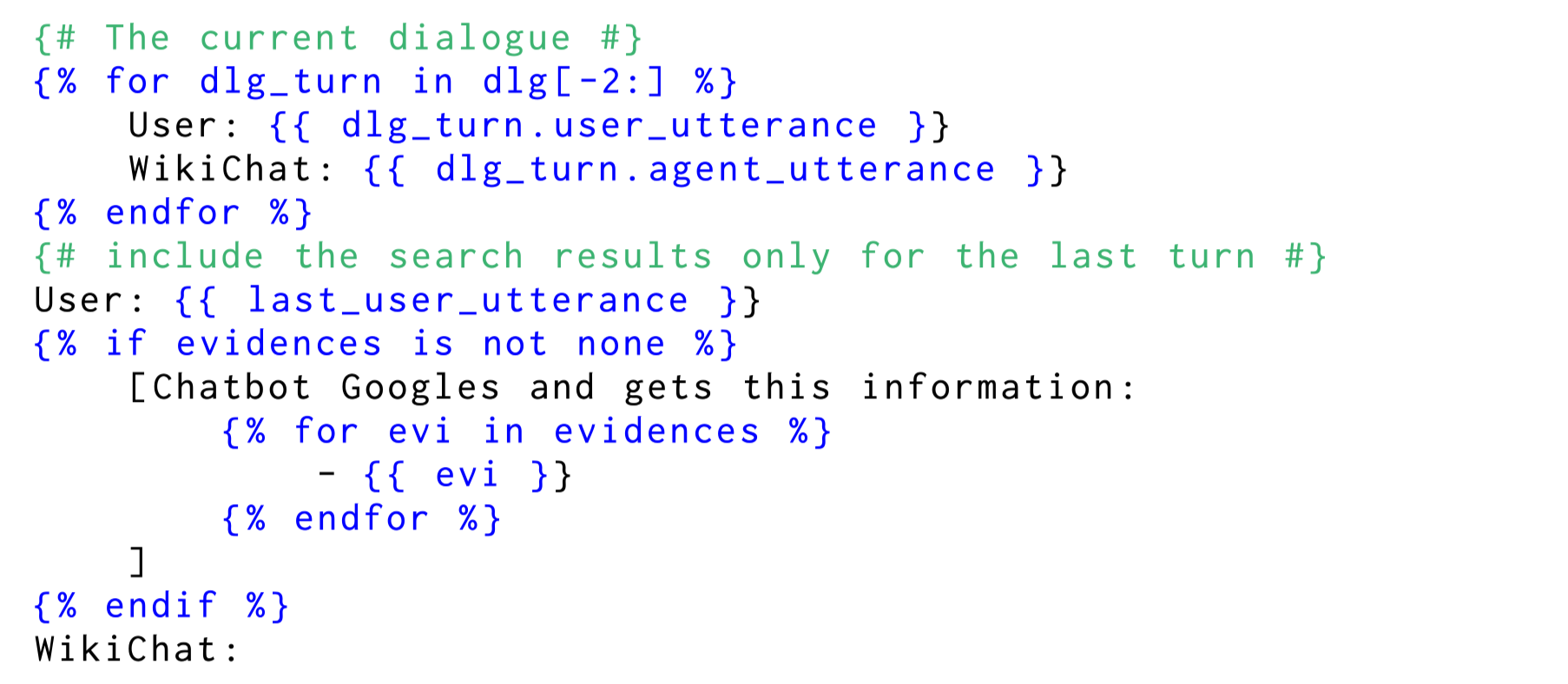
7단계 Response 정제
-
6단계에서 생성한 Response를 다시 Prompting하여 Feedback 작성 → 반영
-
Feedback 기준
-
Relevance : User Query와 관련된 Response인가
-
Naturalness : 문장이 자연스러운가
-
Non-Repetitiveness : 반복된 표현은 없는가
-
Temporal Correctness : 해당 시점에 옳바른 정보인가
-
-
Feedback: 각 기준에 대해 0-100점
-
Refinement : feedback 생성 시점 이후에 바로 정제하도록 prompting
-
K-Shot Prompting

Distillation to LLaMA
-
각 단계별 input, output을 pair로 하여 LLaMA2 Finetune 진행
- Label : GPT-4 응답
-
대화 데이터 : User Simulator Framework를 이용하여 다양한 지식에 대해 이야기하는 데이터셋 구축 → GPT-4 이용
- User의 개성 및 사용 정보를 다양하게 Prompting하여 실제 대화를 모사
-
Knowledge : Head, Tail, Recent로 구분하여 구축
-
Wikipedia 조회수를 기준으로 선택
- 조회수가 높을수록 웹 상에 자주 언급되는 Knowledge라고 가정(자주 사용되는 proxy)
-
Head : Wikipedia 내 2020년(LLM들이 학습된 데이터 시점)까지의 데이터 중 68M ~ 16M회 조회된 페이지
-
Tail : 1000회 이하로 조회된 데이터
-
Recent : 2023년 01월 ~ 2023년 04월까지 새롭게 수정된 페이지
-
Summary
- Retrieval, Summarization, Refinement의 반복을 통해 답변의 품질 개선 프레임워크
3. Evaluation
Factuality
-
답변이 정말 사실 정보를 바탕으로 생성되었는지 평가
-
GPT-4 + human을 통해 Response의 Factuality 평가
-
response를 claim 단위로 분해
-
각각의 claim에 대해 evidence를 Retriever을 통해 산출
-
각각의 claim이 evidence를 기반으로 사실 정보인지 판단 ⇒ GPT-4가 잘 수행하지 못하여 Annotator 고용
-
⇒ Atomic Factuality Check → Factscore
Conversationality
-
답변의 챗봇 응답으로서 품질
-
5가지 세부 지표를 설정하여 사용 : relevant, informational, natural, non-repetitive, temporally correct
-
각각의 지표에 대해 GPT-4 Prompting을 통해 해결
-
기존 연구들에서 해당 지표들은 LLM이 잘 판단한다고 알려져 있음(Citation)
-
각 지표 1-5점 scale
-
⇒ GPT-4와 저자 1인의 inter-annotator agreement가 두 저자 간 inter-annotator agreement와 비슷했음
4. Experiments
Main Results
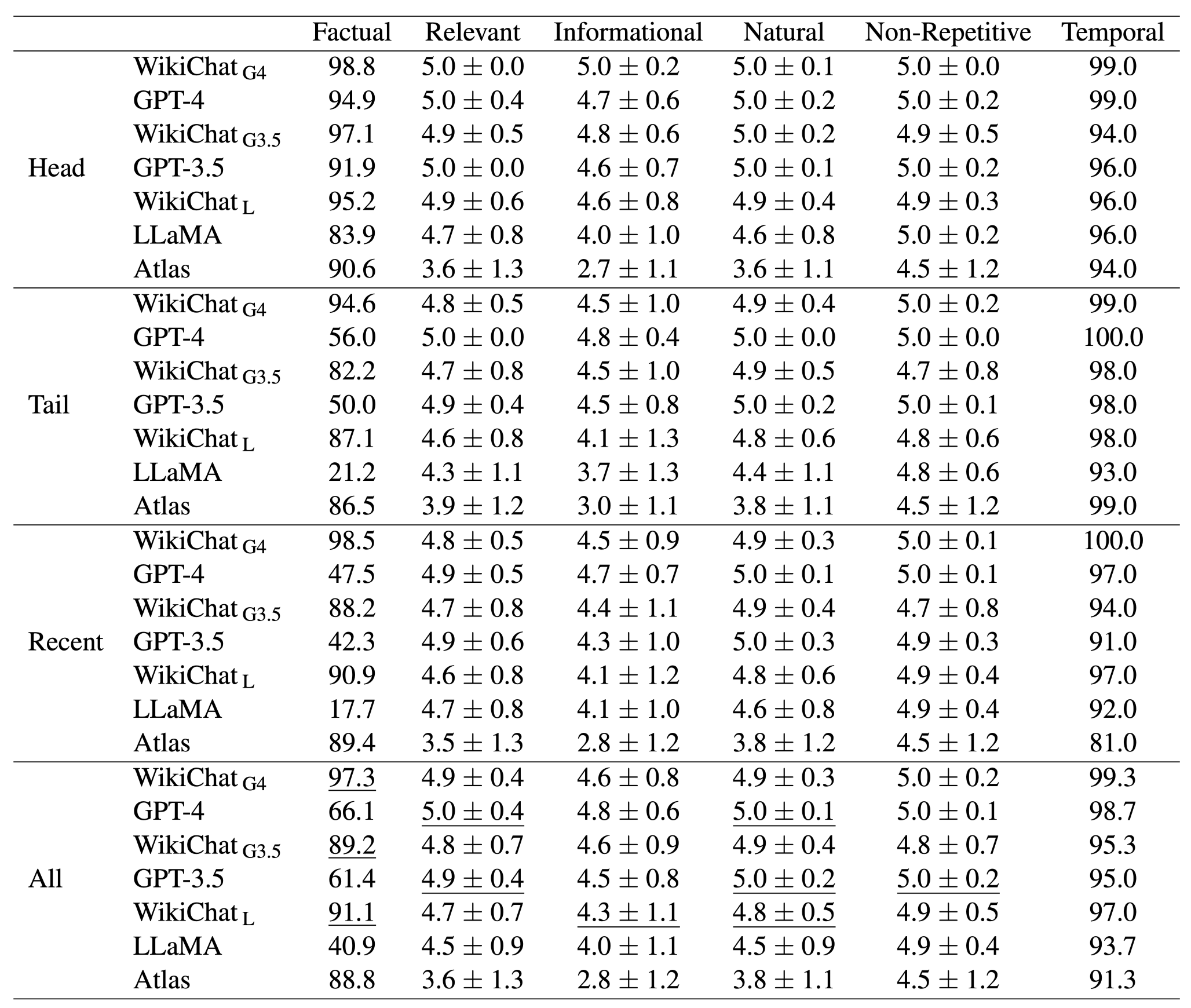
-
All
- WikiChat 모델이 기존 모델 대비 매우 높은 Factuality 달성
⇒ LLaMA의 경우 40% → 91% 상승
⇒ GPT-4에 대한 Distillation + 프레임워크를 통한 사실성 확보
-
GPT Series 역시 Factualtiy 상승
-
대화 점수(5개) 역시 매우 높은 점수 달성
-
기존 점수와 비슷하거나 높은 점수 달성
-
Factuality를 확보하면서 대화 품질 유지
- feedback→refinement를 통한 품질 향상
-
-
Head vs Tail
-
Head에서는 GPT-4/GPT-3.5에 대해 성능 향상이 적은 편
- Head 데이터는 이미 Pretrain Corpus에 다수 포함되어 있어 모델이 이미 잘하고 있기 때문
-
⇒ 기존 Factuality Benchmark 데이터셋들의 한계점이라고 지적
-
Tail 에서는 GPT Series 역시 매우 높은 성능 향상 관찰
- 웹 상에 잘 존재하지 않는 데이터들에 대해 Model 내부의 Knowledge를 사용하기 힘들 때 In Context Learning을 통해 사용하도록 유도한 결과
-
Recent
-
Recent 데이터는 LLM들이 아직 학습하지 않은 데이터
-
LLM들이 타 데이터 대비 Factuality 성능이 매우 떨어지는 모습
-
Atlas : RAG 방식으로 Scratch부터 학습된 Retiever-Generator 모델
- Atlas는 성능 저하가 거의 없음
-
LLM이 아직 학습하지 않은 데이터에 대해서도 98.5%(GPT-4 기준) Factuality 확보 가능
-
-
Latency
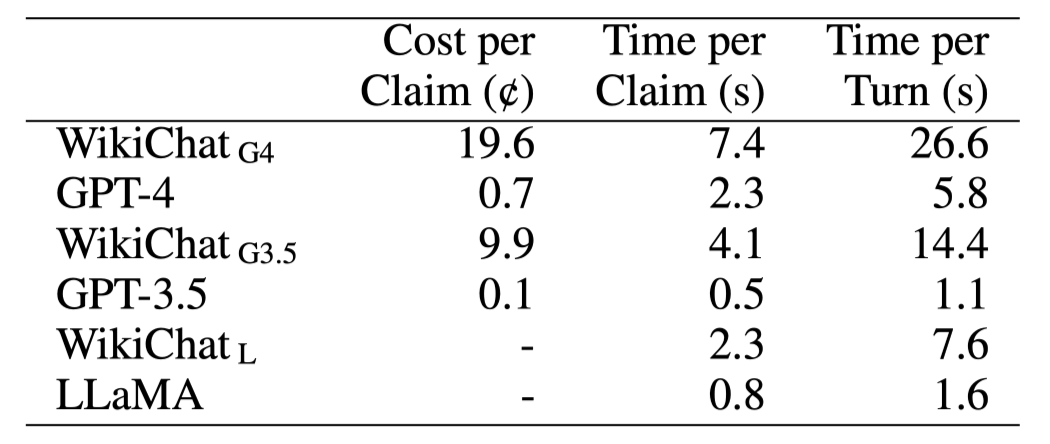
-
Retrieval와 Generation을 매우 여러번 반복하면서 비용과 시간 손해가 매우 큼
-
프레임워크 특성 상 Prompt가 매우 길어져서 불가피한 속도/비용 손해
- 4개의 Prompt가 K-Shot을 사용하고 잇음
Human Evaluation
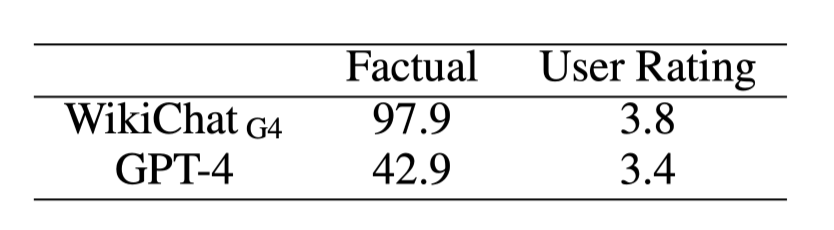
- Human Evaluation 결과 기존 LLM 대비 좋은 성능 기록
-
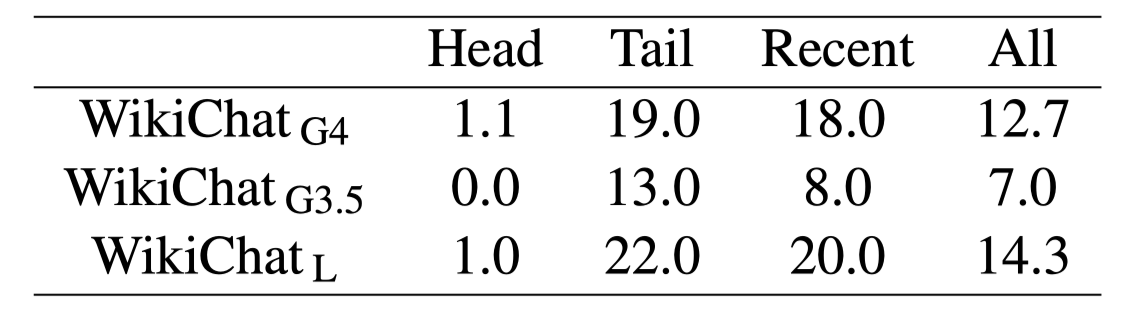
“I Don’t Know”라고 응답한 비중
-
모델이 잘 응답하기 힘든 Tail/Recent에 대해 높은 비중으로 IDK 실행해버림…
-
IDK가 모델 안정성 측면에서는 좋지만, 이 정도로 비중이 높으면 오히려 안좋은 것일텐데…?
-
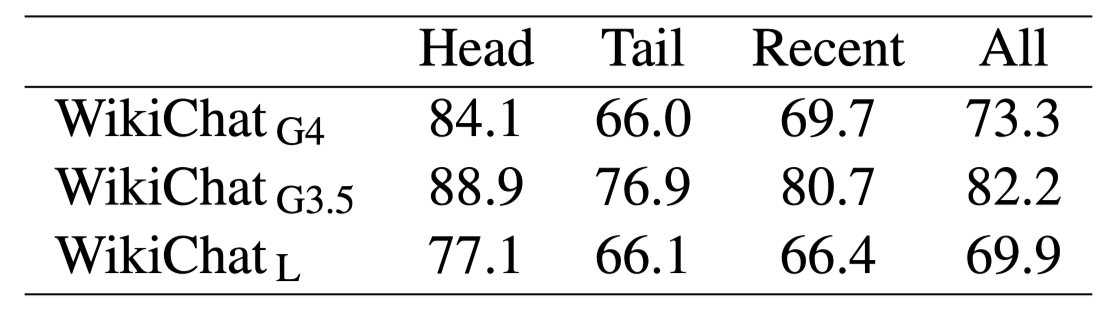
-
refinement 전/후 응답의 BLEU Score 평균
-
Tail/Recent에서 상대적으로 낮은 BLEU Score 기록
-
Tail/Recent에서 모델이 많은 수정 작업을 수행했음
-
7. Conclusion
-
숫자로 보면 매우 좋은 방법론처럼 보임.
-
Prompting과 Retrieval을 극단으로 결합한 프레임워크
-
사실성이 정말 중요한 경우라면 해당 프레임워크 도입 or 개선이 가능할듯
-
당장 해당 방법론이 정말 좋다고 이야기 X
-
평가 metric과 prompting 간 동일한 지표 사용
-
IDK 비율이 매우 높음
-
비용/속도 손해 극심
-