Agent Laboratory: Using LLM Agents as Research Assistants
논문 정보
- Date: 2025-01-21
- Reviewer: 상엽
Introduction
사람의 자원 한계로 인해 탐색할 수 없는 많은 리서치 분야가 있음.
LLM을 활용한 자동화를 통해 리서치 탐색의 영역을 획기적으로 늘릴 수 있음.
-
ResearchAgent (Baek et al. (2024))
-
자동으로 리서치 아이디어, 방법론, 실험 디자인을 생성
-
peer discussion 단계를 모방하기 위해 다수의 reviewing agent를 통해 feedback, refine 과정을 거침.
-
human-aligned evaluation criteria를 이용해 output을 향상
-
-
The AI Scientist (Lu et al. (2024a))
-
fully automated paper generation
- 리서치 아이디어 → 코드 작성 → 실험 실행 → 페이퍼 작성 → peer-review를 통한 평가
-
→ Si et al. (2024)
-
위의 방법들이 새로운 아이디어를 제시한다고 할지라도 detail과 feasibility에서 여전한 한계점 존재
-
사람을 완전히 대체하기 보다는 사람의 idea를 상호보완적으로 발전시키는 역할을 하는 것을 제안
Agent Laboratory
-
Human idea + LLM을 활용한 보조 (사람의 feedback level은 다양하게 가능!)
-
Human research idea → research report & code repository
Contribution
-
개인의 리서치 역량을 향상시킬 수 있는 오픈소스 LLM 모델 제공 (다양한 compute 레벨 지원)
-
사람 평가 결과 (실험 및 리포트 quality, 유용성): o1-preview > o1-mini > gpt-4o
-
Neurips 점수 기준, 사람의 평가와 automated-evaluation의 점수 격차가 매우 컸음. → 평가를 위해서 Human feedback이 필수적임.
-
Overall score: Co-pilot mode > autonomous mode, Co-pilot 모드의 경우 experimental quality와 usefulness trade-off도 존재
-
The co-pilot 모드는 utility와 usability에서 긍정적인 답변을 받았고 사람들은 향후에도 사용하고 싶어함.
-
비용과 추론 시간에 대한 분석 수행, 기존 모델 대비 저렴한 비용으로 작업 수행
-
MLE-Bench에서 SOTA 성능을 보이는 mle-solver 제안
Agent Laboratory
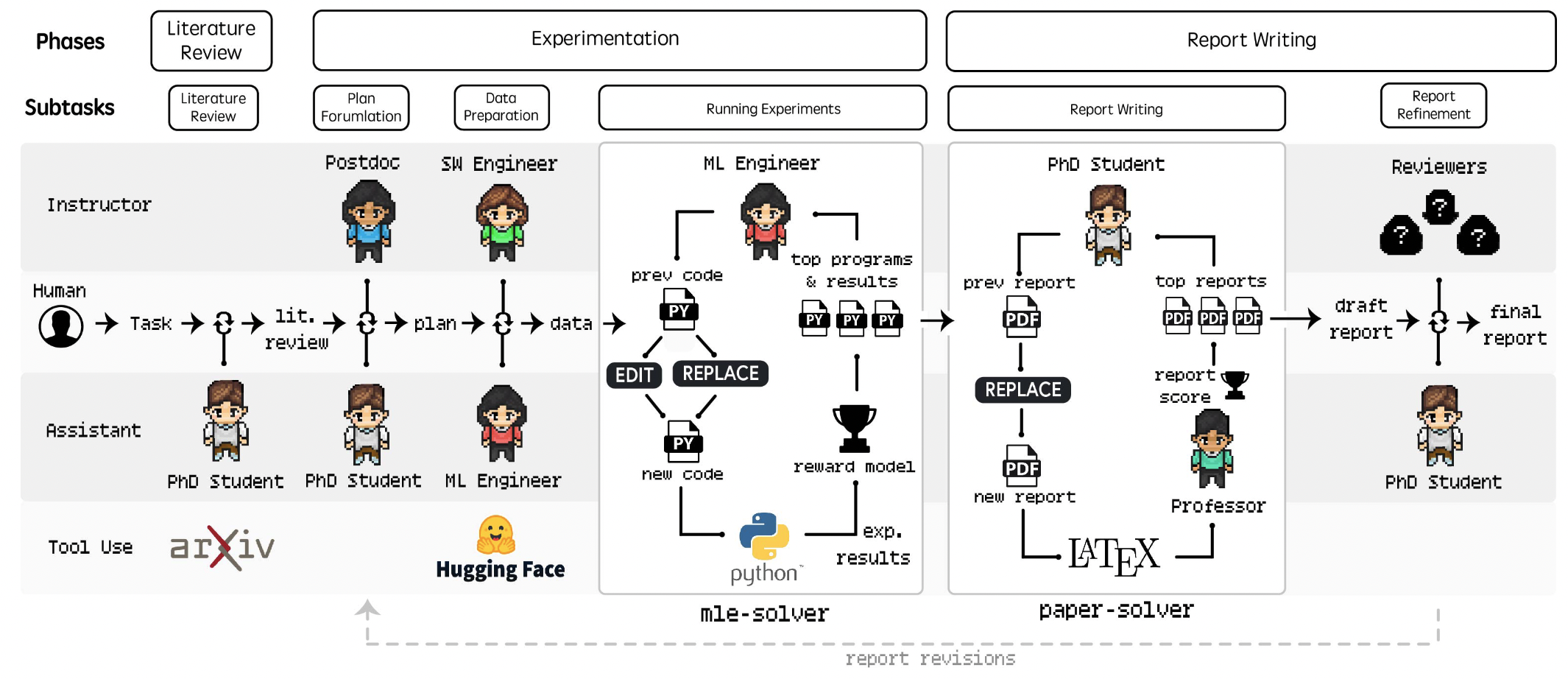
3 Phases: (1) Literature Review, (2) Experimentation, and (3) Report Writing.

-
role
-
Task instruction
-
command description
-
context: 찾은 자료
-
History: agent 행적
-
…
Literature Review

Literature Review Phase: 다음 단계 레퍼런스를 위해 관련 리서치 논문을 찾는 작업.
PhD agent: arXiv API를 활용해 아래 3가지 main actions을 수행.

-
summary: agent에 의해 생성된 쿼리와 관련성이 높은 20개의 paper를 추출.
-
full text: paper의 전체 content를 추출.
-
add paper: summary와 full text를 이용해 curated review를 만듦.
-
위의 과정은 반복적으로 실행 (다수의 쿼리를 이용)하며 매 스텝에서 selection을 진행하여 최종적으로 N_max의 레퍼런스가 확보되면 종료
Experimentation
**Plan Formulation phase: **literature review와 goal을 기반으로 하여 자세하고 실행가능한 리서치 계획을 세우는 작업
PhD & Postdoc agent: 대화를 통한 협업 진행
-
리서치 목표를 어떻게 달성할지에 대해 구체화
-
실험 구성 요소에 대한 설계 (머신러닝 모델)
-
어떤 데이터셋을 사용할 것인지 등
→ Consensus에 도달하면 Postdoc agent가 plan command를 실행하며 생성된 plan을 다음 단계로 전달


Data Preparation phase
목적: 실험 진행을 위한 데이터셋을 준비하는 코드를 작성
ML Engineer

-
**Python **command를 활용해 코드를 실행
-
HuggingFace dataset에 접근해 검색 실행 (search HF command)
SW Engineer
-
code 최종 승인 후, **submit **command
-
최종 승인 전 python compiler를 통해 코드 실행, compile 관련 에러가 없어질 때까지 반복 실행
Running Experiments phase
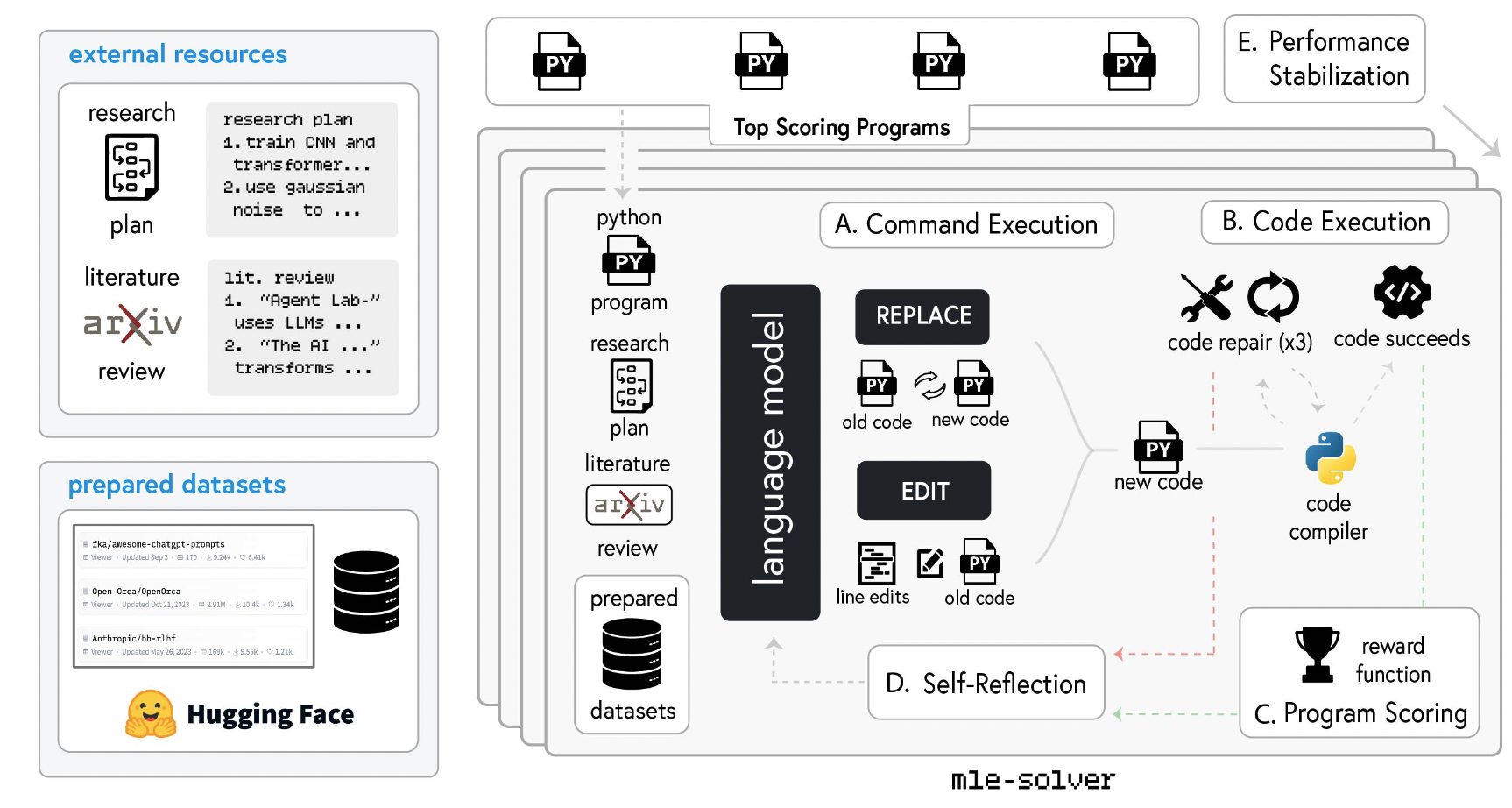
ML Engineer: 이전 실험 계획을 수행하는 것이 목표
mle-solver 활용: 코드 생성, 테스트, 수정에 특화된 모듈
-
리서치 plan과 레퍼런스에서의 insight에 따라 initial code 작성 from scratch
-
절차 (top scoring program: 성능이 가장 높은 파일을 기준으로 수정, 대체 작업을 하는 것)
- Command Execution
-
현재 단계에서 상위 성능 프로그램 (단일 파일, *.py)을 샘플링
-
EDIT: 라인 범위 지정 → 해당 라인의 코드를 다른 것으로 수정
-
REPLACE: 완전히 새로운 파일을 생성
- Code Execution
-
compiler를 통해 런타임 에러 체크
-
성공할 시, 스코어 측정, top score program 리스트 업데이트
-
실패할 시, 코드 수정 N_{rep}=3번 도전 그래도 실패할 경우 replacement
- Program Scoring
-
2단계 성공 시, scoring function을 이용해 해당 코드가 이전 단계의 코드보다 점수가 향상되었는지를 확인
-
LLM을 활용해 mle-solver가 만든 코드의 효과성에 대해 scoring (0~1)
- Self Reflection
-
성공, 실패 여부와 상관없이 reflection 실행, 액션의 결과에 대해 반영하라고 prompted
-
실패할 경우, 다음 단계에 어떻게 에러를 고칠 것이지에 대해 반영
-
성공할 경우, 이것이 어떻게 점수를 향상시켰는지에 대해 반영
-
- Performance Stabilization
-
시스템 성능의 안정성을 위해 다음 두 가지 전략을 취함.
-
top program sampling: 위의 설명과 같음.
-
Batch-parallelization: 각 step에서 N개를 동시에 생성, 최상위 1개만 남기는 방식 (Prompt 변화는 없는듯, temparature를 높게 가져감.)
-
Results Interpretation
Phd & Postdoc agent간 토론을 통해 실험 결과로부터 유의미한 인사이트를 추출
Report Writing
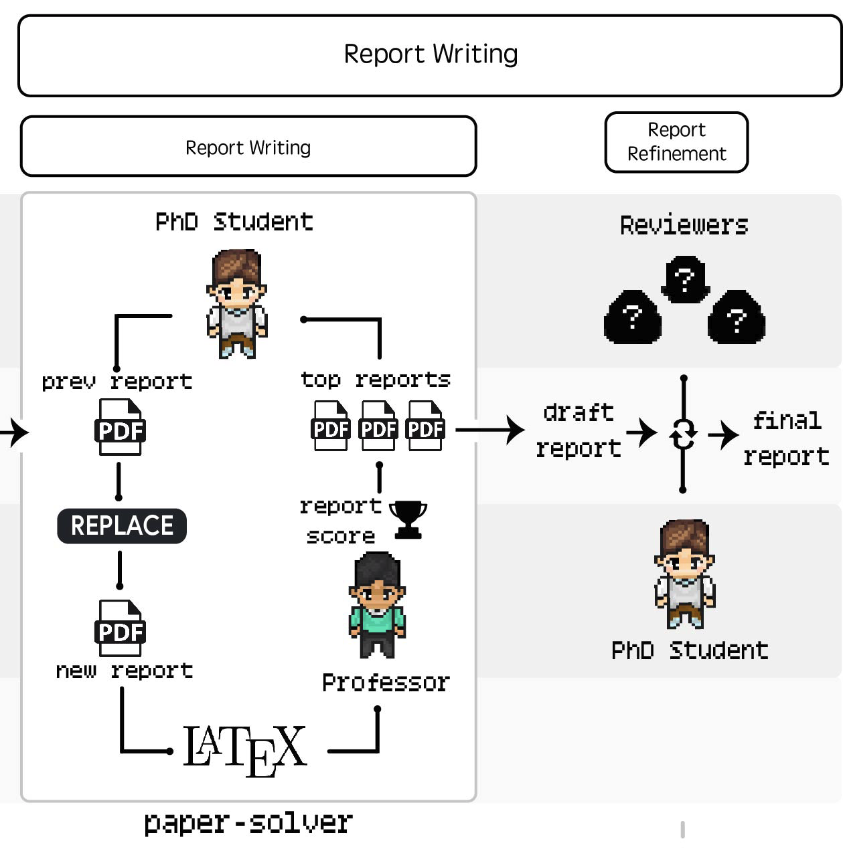
Report Writing
PhD & Professor agent는 paper-solver를 활용해 최종 보고서를 작성하는 역할을 함.
완전한 논문을 작성하는 것은 아니며 이전 결과물들을 readable한 형태로 정리하고 보고서로 만드는 것이 목적
- Initial Report Scaffold
-
8개의 표준 섹션으로 구성 (Abstract, Introduction, Background, Related Work, Methods, Experimental Setup, Results, and Discussion)
-
Latex format 관련 코드 포함, 각 섹션 별로 placeholder로 구성
- Arxiv Research
- 이전 단계와 같은 API를 활용 이전에 찾은 reference 외에 추가로 필요할 경우 선택적으로 활용
- Report Editing
-
실제 report를 작성하는 단계
-
EDIT: latex code를 line 단위로 수정하는 것, 반복적 수정을 통해 계속 글을 수정하여 만족할만한 quality까지 도달할 수 있음.
-
latex compile을 통해 bug-free 보장
- Paper Review


-
각 iteration을 돌 때 마다 글을 평가하기 위해 LLM을 활용한 자동화 된 리뷰 시스템을 활용
-
Neurips 가이드라인을 기준으로 prompt를 구성
-
ICLR 2022 논문을 평가할 시 인간 수준의 정확도를 보였음.
Paper Refinement
세 명의 reviewer agent를 활용해 peer review 단계를 모방, 각각의 평가에 대해 분석 후 Phd agent는 작성을 완료할지 이전 단계로 돌아가 글을 수정할지를 결정
Autonomous vs Co-Pilot Mode
-
Autonomous mode: 사람은 연구 아이디어만 제공
-
Co-Pilot mode: 사람은 각 subtask별로 리뷰를 진행
Results
Autonomous Mode
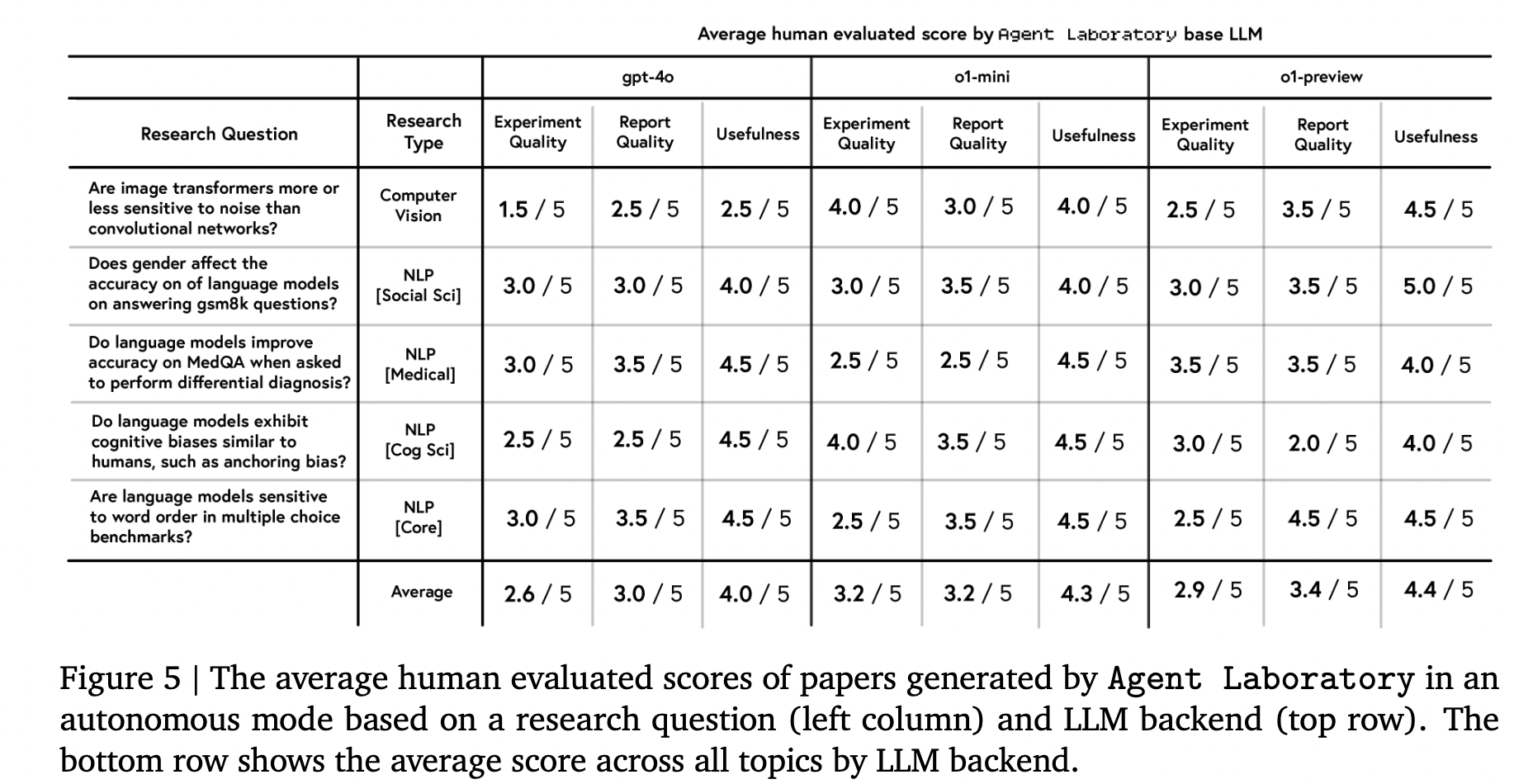
글의 Quality 평가
experiment quality, report quality, usefulness 측면에서 사람 평가 진행
-
Experimental Quality: What is your perception of the quality of the experimental results presented in this report?
-
Report Quality: What is your perception of the quality of the research report writing quality presented in this report?
-
Usefulness: What is your perception of the usefulness of an AI assistant tool that can generate the presented report autonomously?
이렇게 5개의 research question 활용
-
Do language models exhibit cognitive biases, such as confirmation bias or anchoring bias?
-
Are image transformers more or less sensitive to pixel noise than convolutional networks?
-
Do language models improve accuracy on MedQA when asked to perform differential diagnosis?
-
Are language models sensitive to word order in multiple choice benchmarks?
-
Does gender role play affect the accuracy on of language models on answering math questions?
-
인간 개입 없이 Agent Laboratory 실험 진행
-
10명의 PhD 학생들에게 각각 3개의 논문을 배정 후, 평가하게 함.
→ 모델별로 평가 결과가 상이함. o1-preview > o1-mini » gpt-4o
Human reviewer 점수 평가
-
뉴립스 기준에 따라 사람과 LLM을 활용해 평가를 진행
-
전체 점수는 o1-preview > o1-mini > gpt-4o 순으로 똑같은 결과
-
전체 점수가 3.8로 뉴립스 합격자 평균인 5.9에는 미치지 못하는 상태
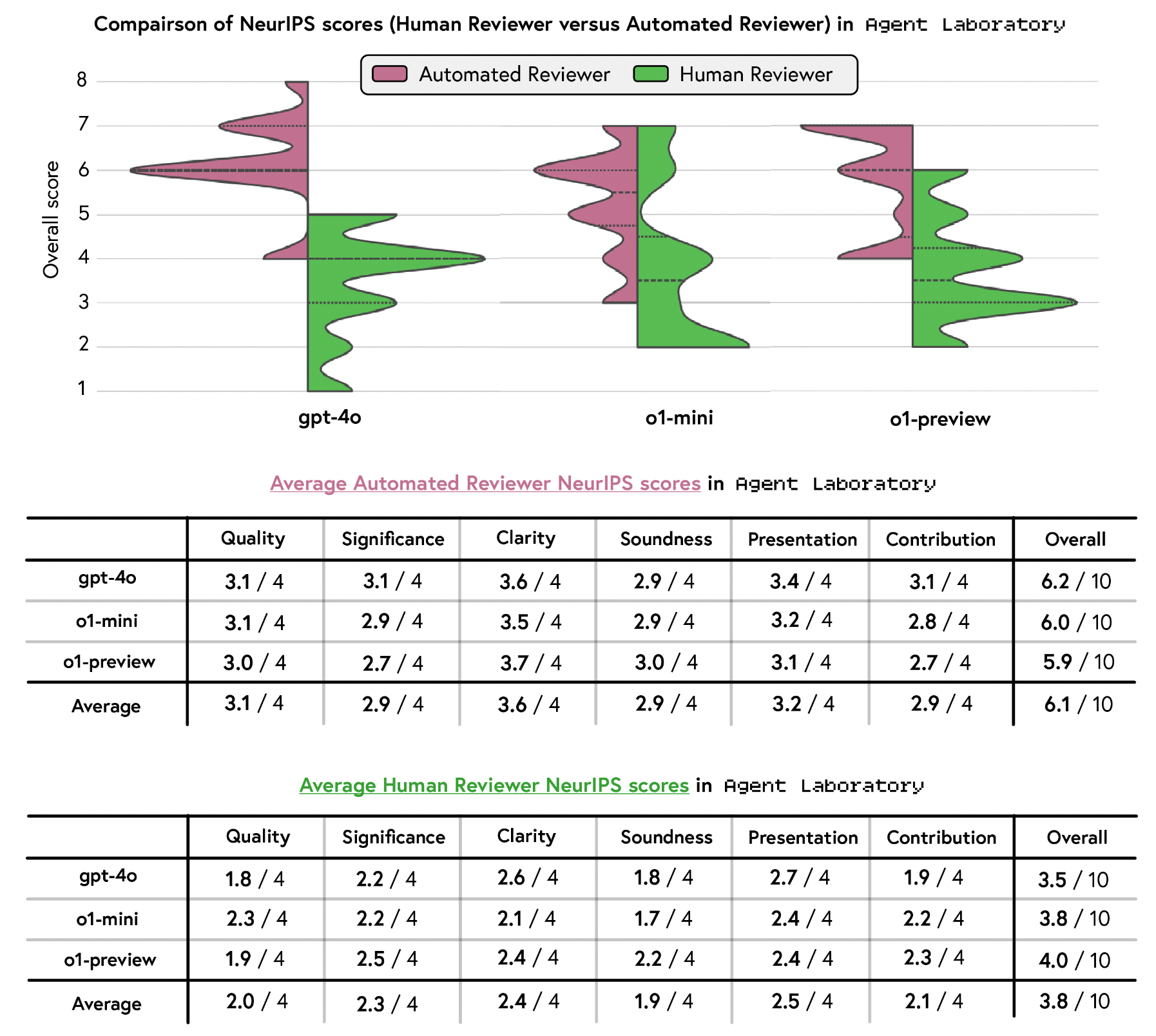
-
사람과 Automated reviewer와의 점수 비교 결과, 사람의 점수와 큰 차이를 보임.
-
인간 평가가 필수적일듯…
Co-pilot Mode
o1-mini로 모든 실험 진행
-
custom: 자신이 선정한 연구 주제와 함께 Agent Laboratory를 활용
-
preselected: 이전 섹션에서 제시된 주제 중에 2가지를 골라서 Agent Laboratory를 활용
Quality as a tool
report 생성 이후 아래 항목에 대해 설문 조사 진행
-
Utility: How useful is Agent Laboratory for assisting your research?
-
Continuation: How likely are you to continue using Agent Laboratory for research?
-
Satisfaction: How much did you enjoy using Agent Laboratory?
-
Usability: How easy was it for you to build a project using Agent Laboratory?
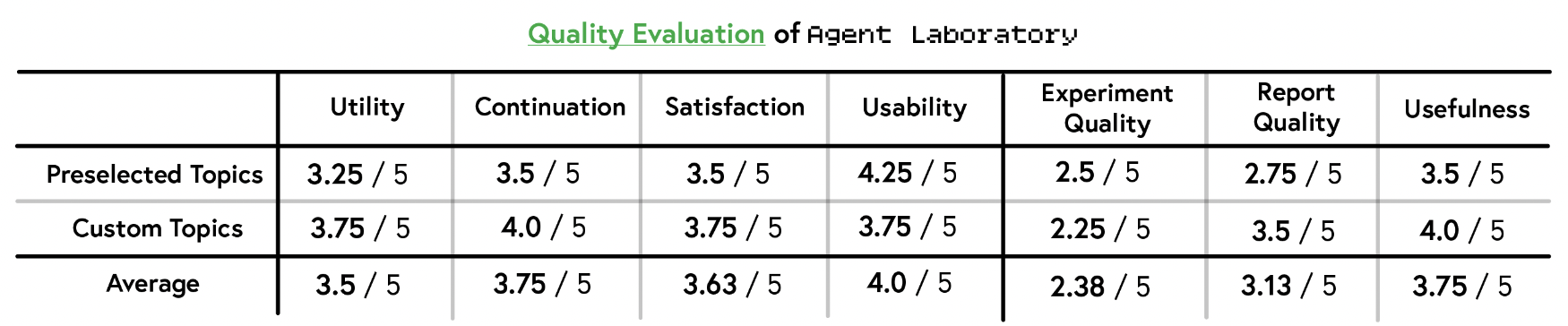
-
Custom Topic이 Usability를 제외하고 더 높은 점수를 받음.
-
Quality 측면에서는 Topic과 무관하게 autonomous o1-mini보다 낮음 점수를 기록 (이는 실험자의 의도를 Agent에게 실행시키는 방법에 어려움이 있어서라고 평가함. 자세한 논의는 뒤에서)
-
추가 설문조사 결과: GUI 추가, 중간 결과 검사 기능 향상, 그림을 포함할 수 있는 옵션 추가, Literature review 단계 개선 등의 요청을 받음.
Evaluation of co-pilot generated papers
Self-evaluation

-
내부 실험자 평가, autonomous mode보다 더 높은 점수를 보임.
-
Overall score 3.8 → 4.13 (+0.33), o1-preview보다 좋은 성능
-
Siginificance와 Contribution은 조금 감소 (-0.3, -0.1)
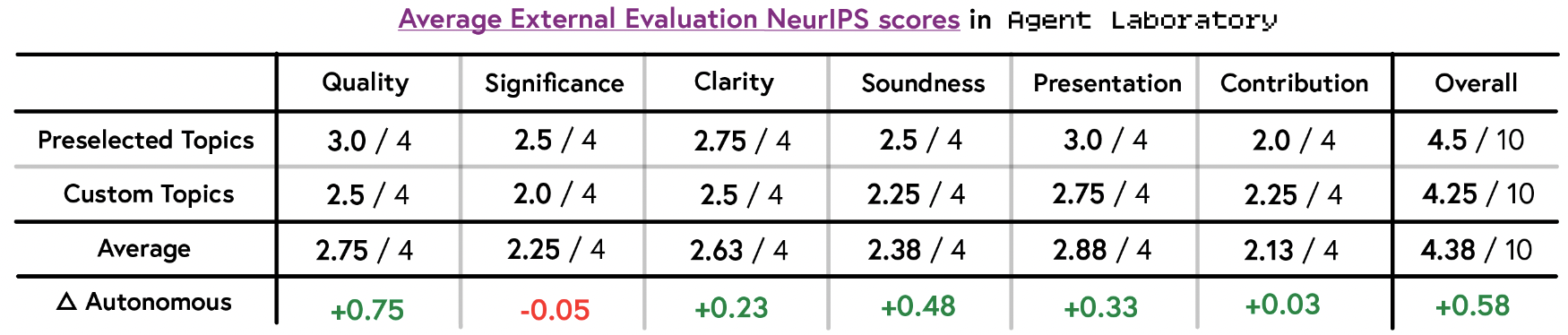
External evaluation
-
외부 평가 결과 점수가 더 향상.
-
Self-evaluation과 비교해도 대체로 상승했으나 Clarity 부분만 감소함.
-
Custom topic과 Preselected topic간 점수 차이도 역전되는 현상 발생 (자체 평가자가 Preselected topic에 대해 조금 낮은 점수를 주는 경향)
Runtime statistics
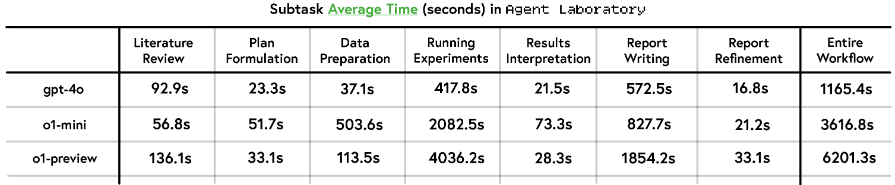
Inference time
-
속도: gpt-4o » o1-mini » o1-preview
-
주요 병목: Running Experiments, Report Writing
Inference cost
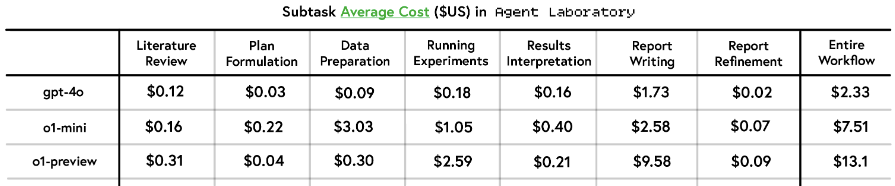
- 이전 연구에서 gpt-4o 비용이 $15였던 것에 비하면 저렴
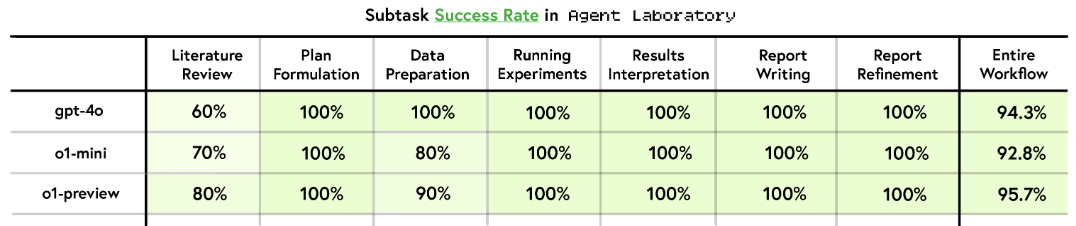
Success Rate
-
모든 모델이 전반적으로 높은 성공률을 가짐.
-
Literature review가 가장 낮으며 Data Preparation은 역전이 되기도 함.
Evaluating mle-solver on MLE-Bench
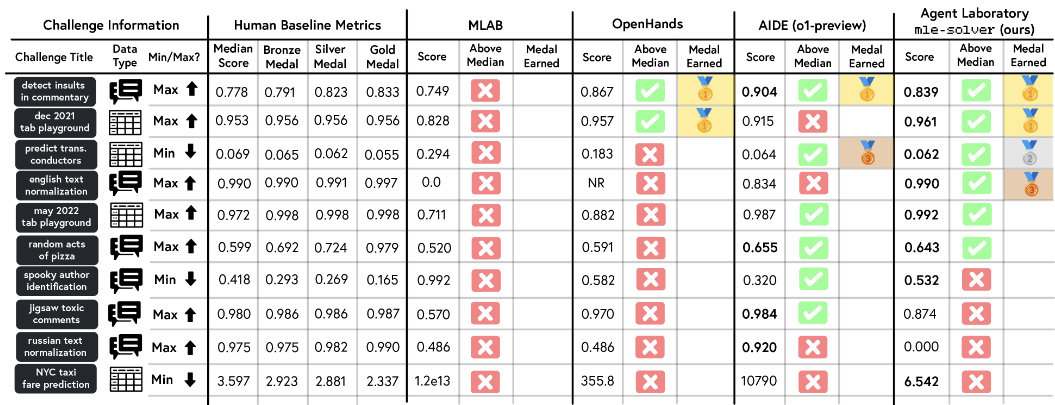
-
이전 평가에서는 ML 문제를 풀기 위한 solver에 대한 구체적 평가는 없었기 때문에 MLE-Bench의 10개 challenge를 이용해 4개의 solver들을 비교해봄.
-
다른 모델의 경우 2시간 제한 안에 challenge를 클리어하지 못하는 경우도 있어 해당 부분은 결과에서 제외함.
-
mle-solver가 가장 많은 메달을 땀. (금: 2, 은: 1, 동: 1), 6/10에서 median score를 넘음.
Limitations
-
벤치마크에서 사람과 거의 유사한 평가를 내리는 모델이라고 할지라도 Agent Laboratory 평가에서는 사람과 일치하지 않음.
-
최종 논문이 아닌 사람과 협업을 위한 중간 report를 만드는 것이 목적임에도 Neurips 기준으로 휴리스틱 평가를 진행
-
고정된 섹션 구조로 글을 작성함.
-
오직 두 개의 그림만 그리게 설정되어 있음.
-
repository 단위로 코드를 관리하지는 못함.
-
gpt-4o와 같이 낮은 성능을 보이는 일부 모델에서 Hallucination이 발생했음.
-
Common failure modes
-
Literature review 단계에서 summary command 사용 빈도가 너무 높음.
-
Literature review 단계에서 context limit에 걸리는 경우가 발생
-
mle-solver가 0% 성능을 보이는 경우도 빈번히 발생
-
mle-solver가 0번 라인 위주로 수정하는 경우가 많아 replace가 더 효과적일 때가 많았음.
-
mle-solver가 exit() 명령어를 사용하여 전체 시스템을 꺼버리는 경우가 존재
-
mle-solver가 subprocess.run()을 사용하여 시스템 명령어를 사용하는 경우가 존재
-
paper-solver가 arxiv api 활용 시 limit에 걸리는 경우가 많음.
-
-
할거면 다하지 중간 report를 만드는 게 목표라는 것이 조금 애매하다.
- limitation이라고는 하지만 비용이 다른 모델 대비 저렴한 것도 이것 때문 아닌가?
-
기대한 것보다는 내용은 조금 없었던 거 같은데 그림이 귀여움.
-
각 Phase 별로 모델을 섞는 것이 best가 아닐까?
-
프롬프트를 포함한 모든 코드가 공개됨. (깔끔한듯, 생각보다 .py의 수도 적어서 쉽게 적용 가능할듯)
- 돌려보니 결과가 좀 다른듯
-
구글 Agent 백서: https://github.com/daiwk/collections/blob/master/assets/google-ai-agents-whitepaper.pdf