Between Underthinking and Overthinking: An Empirical Study of Reasoning Length and correctness in LLMs
논문 정보
- Date: 2025-07-01
- Reviewer: 준원 장
- Property: Reasoning
1. Introduction
-
Test-time scaling is trending, but longer reasoning is not always better.
-
Reasoning와 accuracy가 항상 상관관계를 이루지 않는다는 최신연구 존재 (Xie et al., 2025; Jin et al., 2024; Wu et al., 2025)
(연구들 안봤지만 (1) 모델이 작거나 (2) 32K, 64K까지 inference안해봐서 그럴거 같다고 생각.. o3도 아예 못푸는 lcb pro 수준이라면 예외)
-
여튼, 이러한 흐름에 따라 최근에 나온 용어
- Overthinking phenomenon; simple problems에도 verbose outputs을 생성하는 현상
-
그래서 논문은 DeepSeek-1.5B-Distill과 DeepScaler-1.5B-Preview를 가지고 reasoning length와 accuracy를 가지고 체계적인 분석을 수행하겠다!
2. Related Work
⇒ lengthy reasoning 문제를 관측하고, 이를 해결하기 위한 학습방법론들
-
Concise thinking
- reward나 pre-sampling (뭔진 몰겠음..)으로 RL/SFT-training때 good accuracy를 유지하면서 상대적으로 짧은 reasoning path를 생성하는 연구 계열
-
Adaptive thinking
- (prompting 위주) 문제 난이도·모델 확신도에 따라 토큰 예산을 동적으로 조정하거나 조기 종료
→ lengthy reasoning path가 high accuracy를 보장하지 않는다는 실험적인 결과를 보이는 경우가 많음
-
Optimal Thinking
- reasoning path가 길어지면 성능이 처음엔 오르다가 다시 떨어진다는 점을 이론·실험으로 입증
(…이게 이론으로 입증이.. 되나..?)
3. Experimental Setting
-
Model
-
DeepSeek-1.5B-Distill (Denoted as R1-Distill)
-
DeepScaler-1.5B-Preview (Denoted as R1-Preview)
-
-
Dataset
-
GSM8K
-
MATH
-
-
Params.
-
temperature T = 1.0 (most calibrated)
-
top-p = 1
-
-
Notations
-
question: q
-
of completions: N
-
{(o(q)i , l(q)_i , c(q)_i )}^{N −1}{i=0}
-
o(): output
-
l(): length
-
l(): correctness 여부 {0,1}
-
-
4. Sample-Level Analysis
→ q는 고정하고 길이가 다른 10개 completion을 비교해 length와 accuracy의 직접 상관을 조사
- 난이도에 대한 변인을 고정하고 length ↔ accuracy 관계만 볼 수 있음
Non-Linear Relationship of Sample Length and Correctness
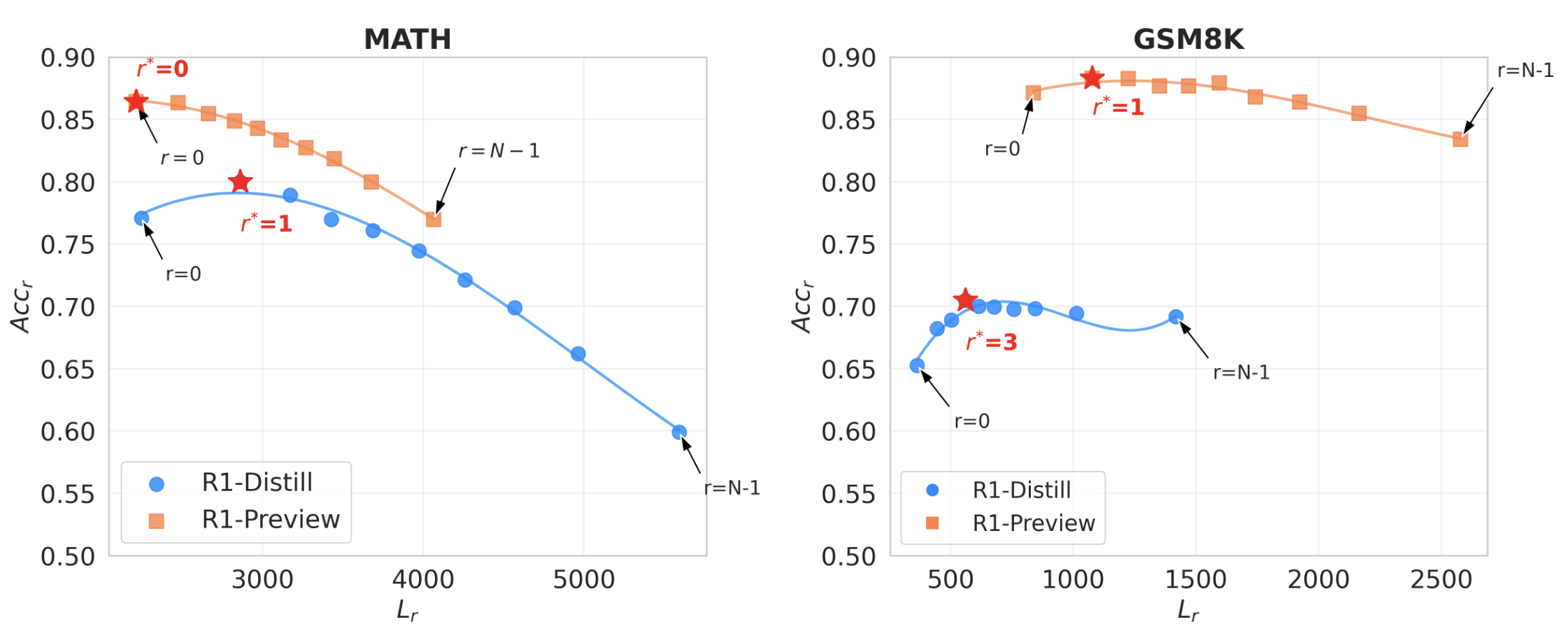
- L_r, Acc_r: r번째로 짧은 reasoning path의 평균 length/accuracy
(모든 q에 대해 10개씩 다 생성하고 가장 짧은 completion의 길이 평균: L_0)
-
consistent non-monotonic trend 관찰
- Distill 기준 어느정도는 길어야 best acc, 너무 길어지면 decline
(준원 뇌피셜: 일단 R1은 (1) MATH 관련 데이터는 외워서 풀것 같기 때문에 temp=1.0, top_p=1로 줘서 decoding path 길어지면 degen 발생했을것으로 예상 (2) GSM8K 유사 난이도는 거의 외웠을것이고 + 상대적으로 쉽기 때문에 1~1.5K thinking budget내로는 거의 비슷할거 같음..)
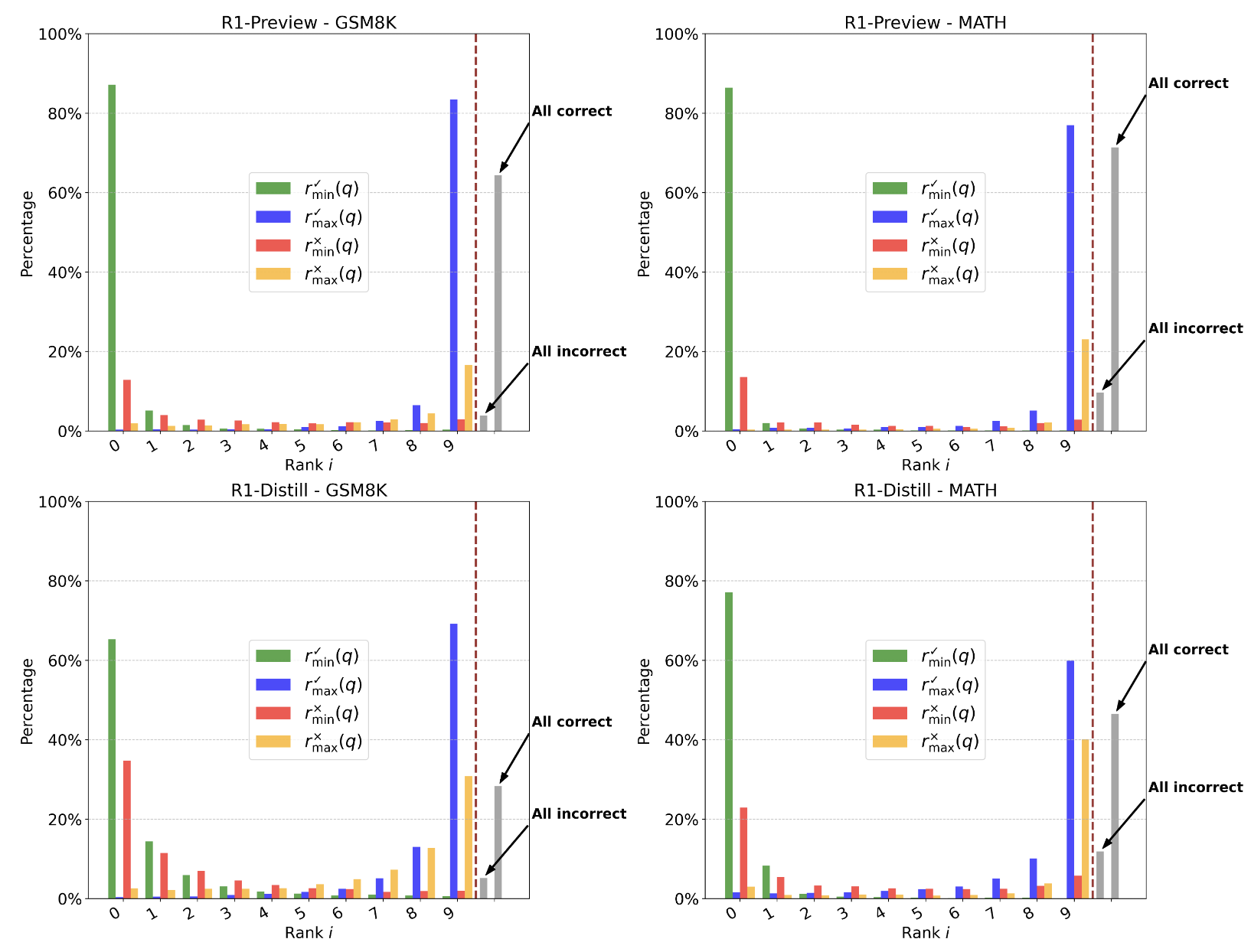
-
초록: q에 대한 정답 completion중 가장 짧은 거
-
파랑: q에 대한 정답 completion중 가장 긴거
-
빨강: q에 대한 오답 completion중 가장 짧은 거
-
노랑: q에 대한 정답 completion중 가장 긴거
-
R1-Preview는 MATH, GSM8K 모두 80% 이상의 질문에서 가장 짧은 샘플로 정답을 생성할 수 있음을 보임
-
most length한 completion중에 correct response도 있지만 incorrect response도 존재 (논문 해석 이상..)
5. Question-Level Analysis
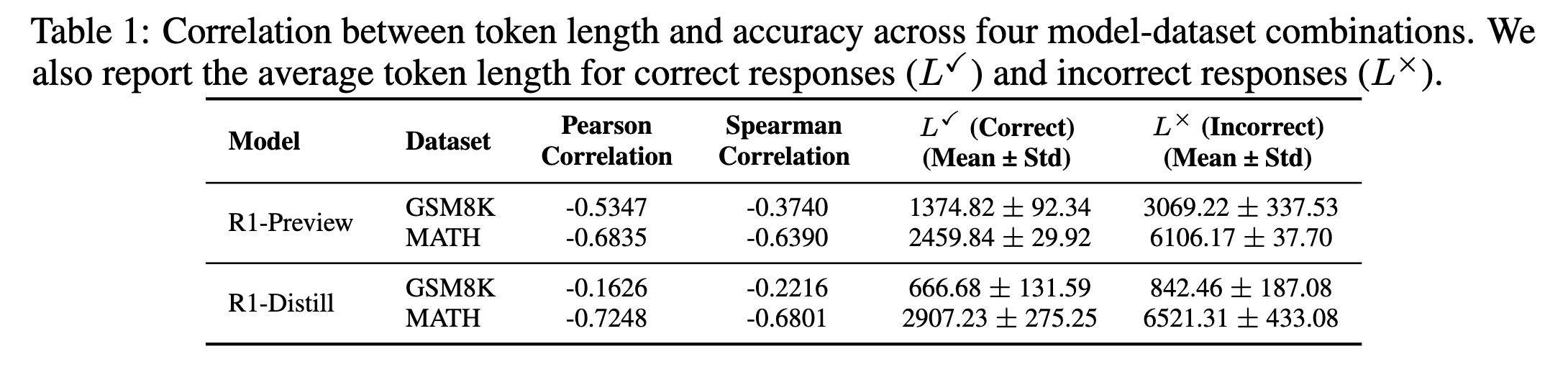
- 단순하게 문제 난이도를 틀림 여부로 볼때, incorrect response가 어떤 조합에서든 response 길이가 더 길었음
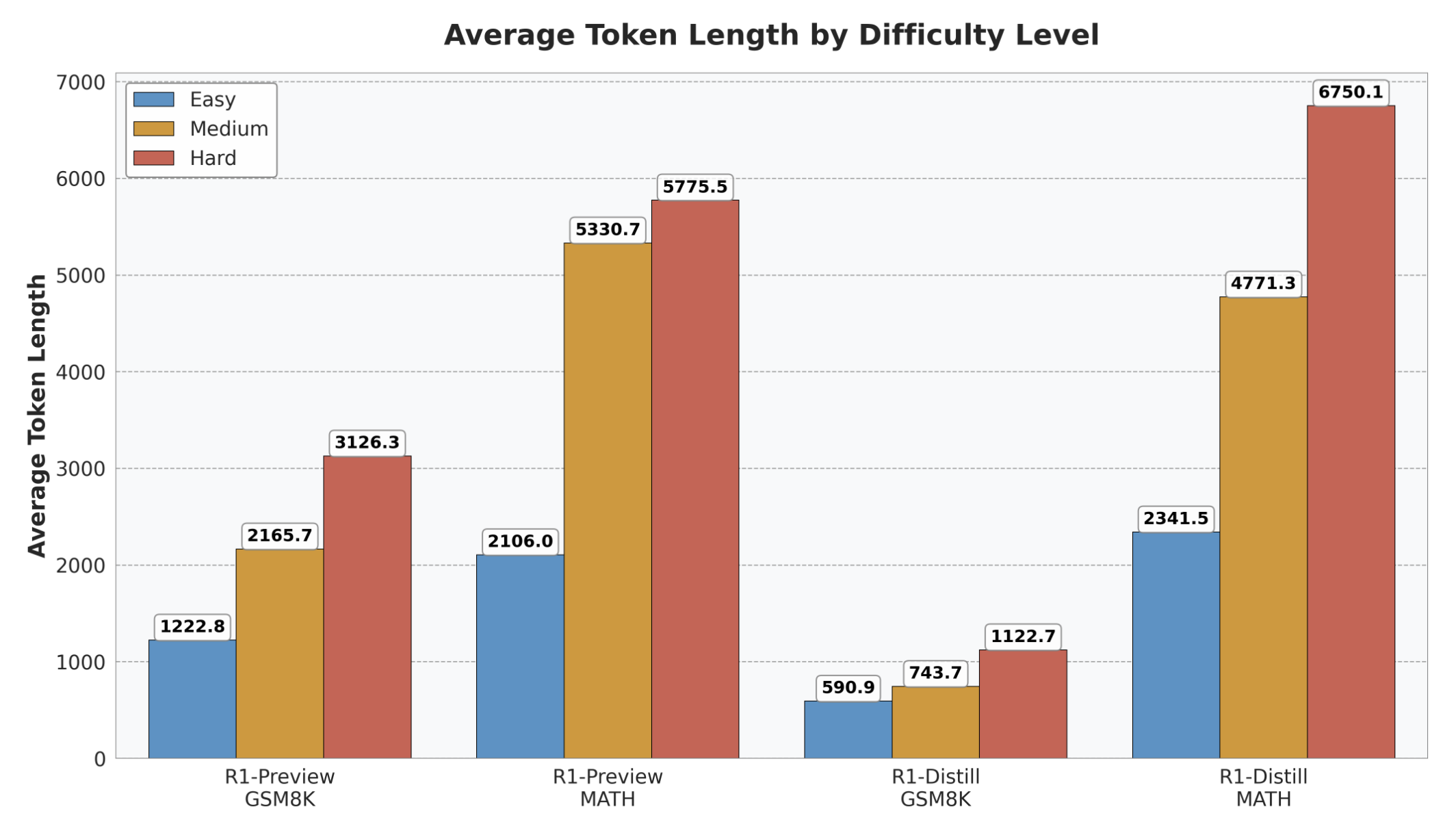
-
N-completion별로 difficulty를 분류
-
Easy: model이 10 completion 모두 정답률 100%
-
Medium: model이 10 completion에서 정답률 0% < acc < 100%
-
Hard: model이 10 completion에서 정답률 0%
-
⇒ 그러나 (1) 문제가 어려워서 lengthy한지 (2) length해져서 틀린건지 판단이 어려움
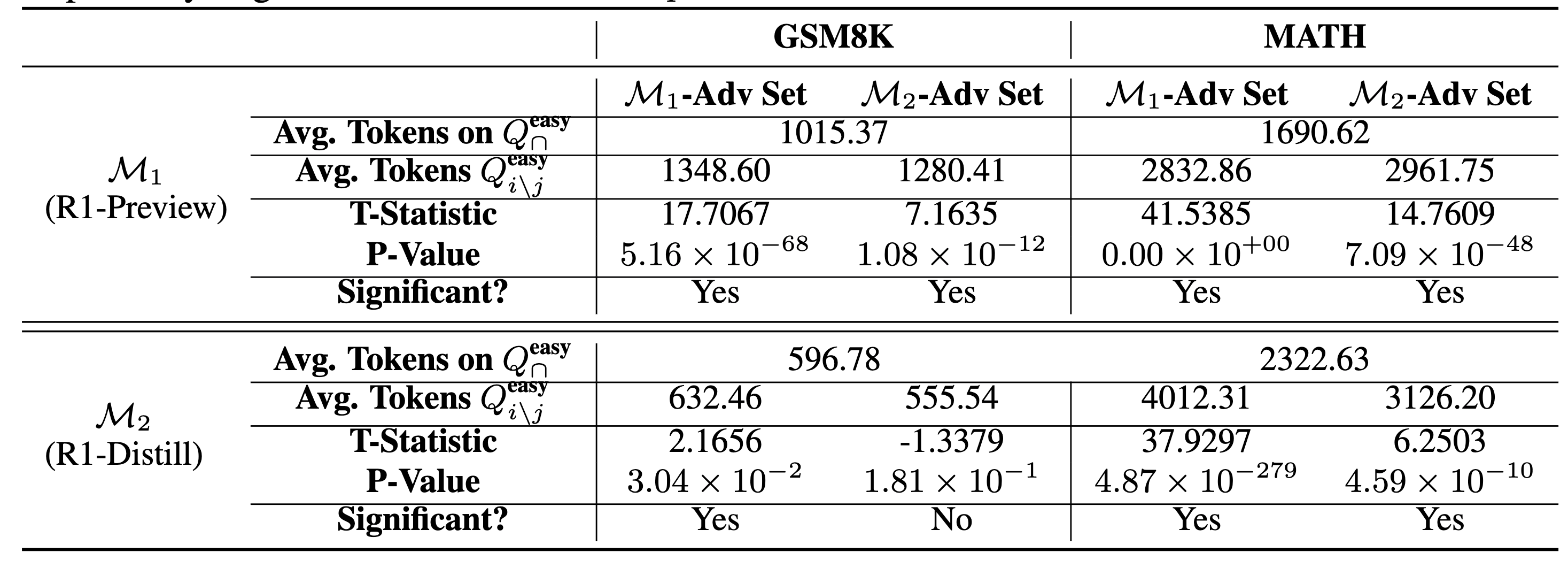
-
Q^{easy}{\cap} = Q^{easy}{i} \cap Q^{easy}_{j}
-
Q^{easy}{i/j} = Q^{easy}{i} / Q^{easy}_{j} > M_i 에서만 쉬운 문제
-
Q^{easy}{j/i} = Q^{easy}{j} / Q^{easy}_{i} > M_j에서만 쉬운 문제
-
보편적으로 쉬운 문제가 아니라 another model’s advantage set (다른모델에서 쉬운 문제)에서 오히려 lengthy generation을 보임
-
signficant로 보면 M_i → M_j-Adv Set을 풀때 보다 lengthy해짐
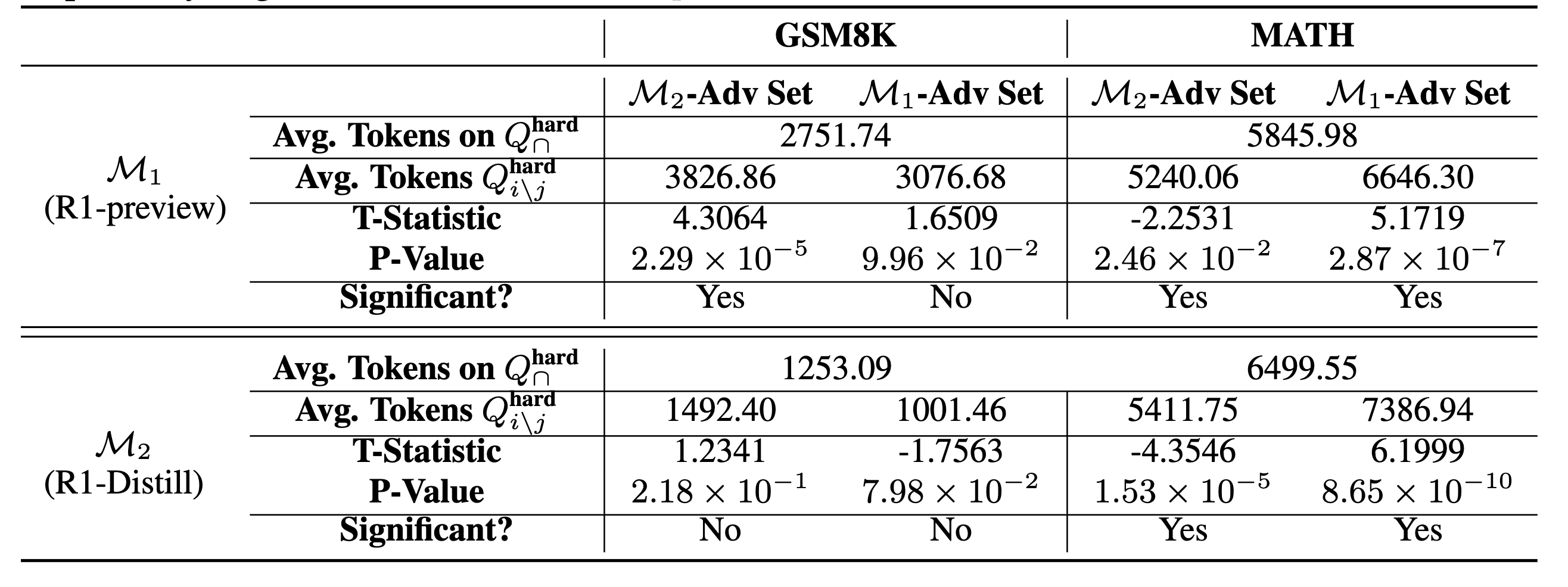
-
hard question에서는 Q^{hard}_{\cap}에서 보다 another model’s advantage set에서 lengthy해질 것을 기대했으나 그렇진 않음
- hard question에서 clear pattern은 없음
→ 문제가 너무 어려운 경우 모델이 어려운 문제의 난이도 증가를 인식하고 이에 대응하는 데 어려움을 겪을 수 있음 (e.g., 문제 난이도를 과소평가하여 짧게 생성)
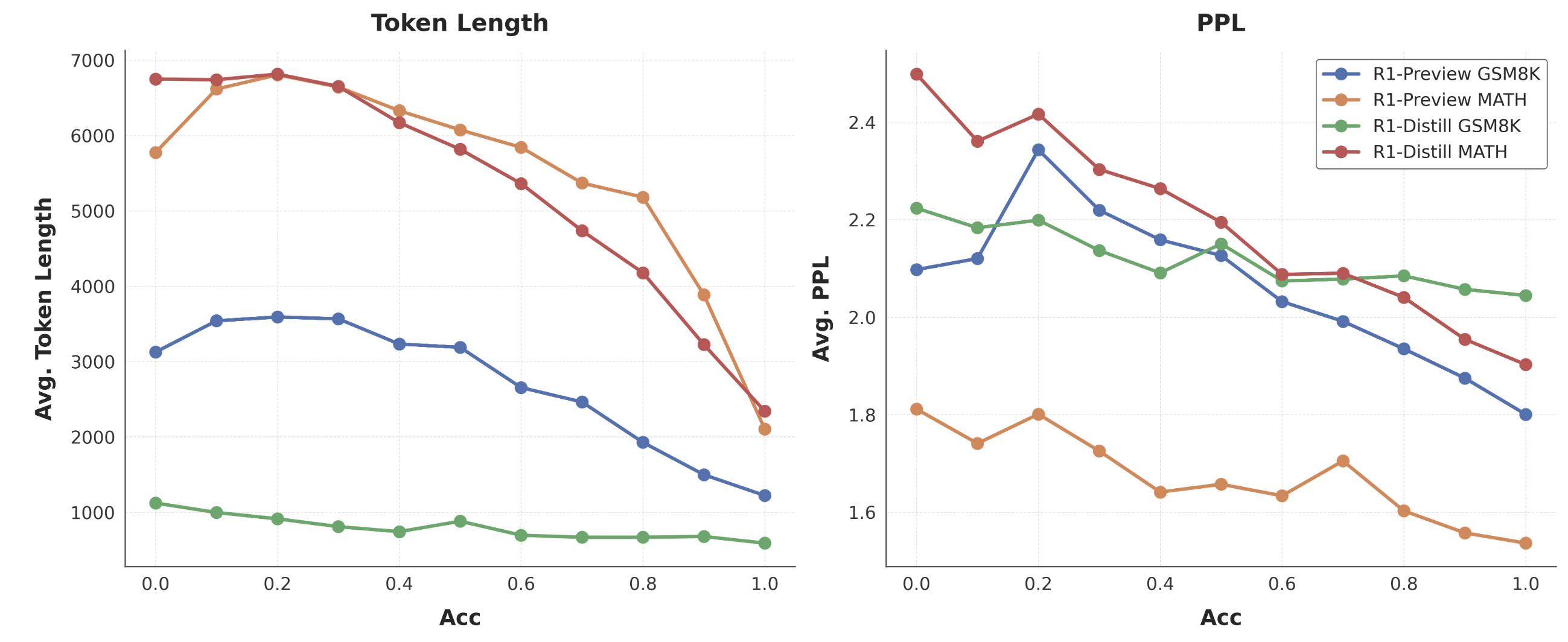
-
(어떻게 실험했는지는 모르겠는데..) token length가 짧아질수록 accuracy가 올라간다.
-
위에 실험을 기반으로 token legnth가 짧으니 확률적으로 당연히 accuracy가 높은 답변일수록 PPL도 낮을 것
6. Effect of Length Preference Optimization
- 지금까지 지적된 문제들을 해결하기 위해 correct/length-balanced reward-based RL등이 소개되었음
(N» samples, ground truth label이 필요)
-
이를 위해 이전에 drive-out한 직관들을 가지고 간단한 실험을 진행.
-
LM을 가지고 2개의 completion을 생성
-
(데이터셋이 쉬웠으니) 정답 유무에 상관없이 짧은 response가 정답일 확률이 높을거라는 가정하에 짧은 response에 preference가 가해지도록 SimPO
-
MATH/GSM8K training set, 8K rollout
-
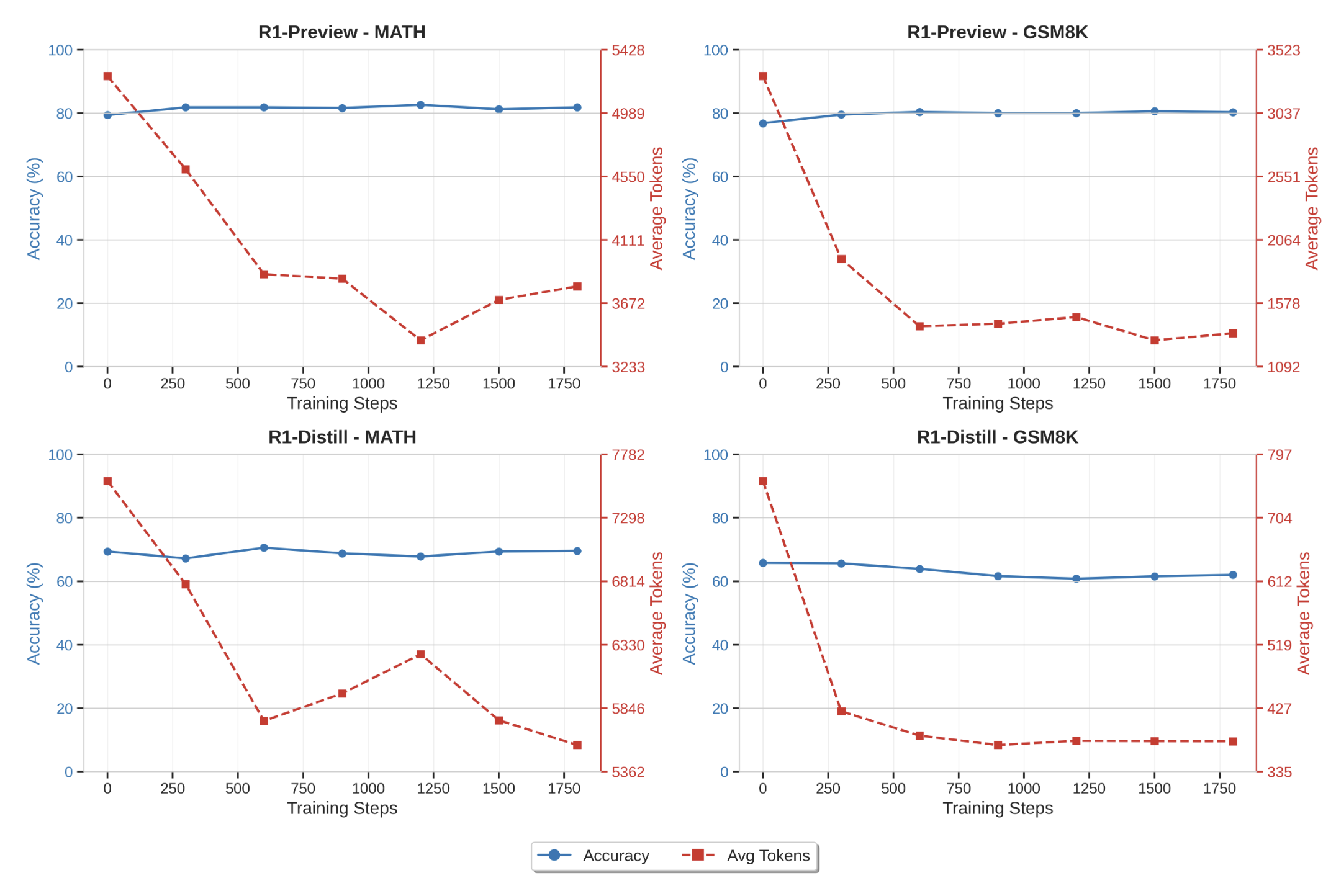
- training step을 반복할수록 accuracy 변동폭은 적으나 average token length 30%에서 60% 감소
(length decrease가 정답의 단축 때문인지, 오답의 단축 때문인지, 아니면 둘 다 때문인지…?)
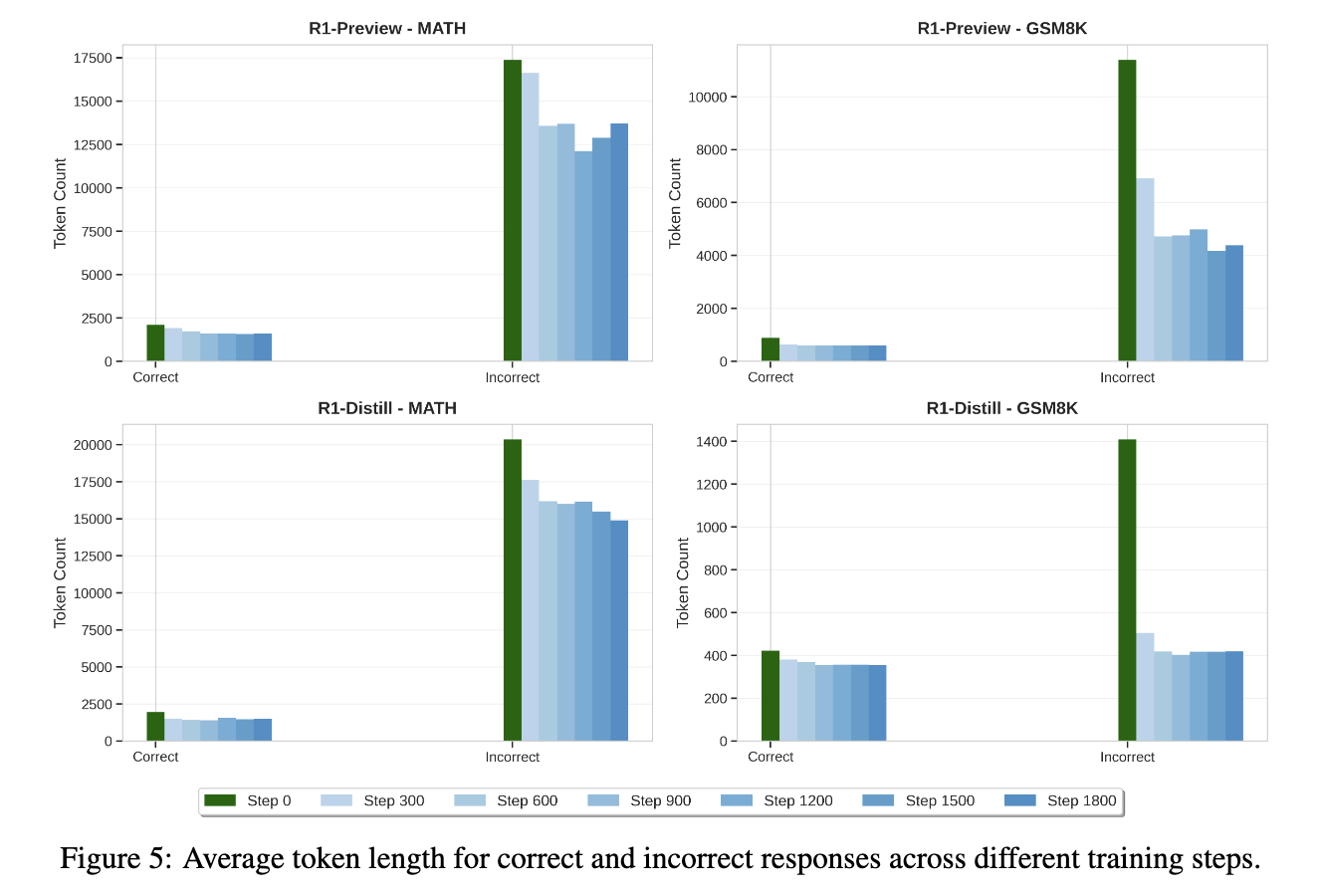
- SimPO가 진행됨에 따라 incorrect response의 생성이 줄어들었다.
→ (준원) 해석을 해보면,
-
어짜피 맞을 문제는 2 completion 다 짧을거였으니 그 중에서도 짧게 생성하도록 model 학습
-
틀린 문제는 2 completion 다 길게 생성했을것이나 (그 중 하나는 조금이라도 짧게 생성했을테니) 학습이 됨에 따라 조금씩 짧게 생성하도록 했을 것
7. Conclusion & Limitation
-
generation length와 final answer correctness에 대해서 심도 있는 분석
- 변인 통제도 신경썼고, takeaway도 많음
-
LM의 크기가 너무 작고, benchmark가 너무 쉬움…
- 큰 LM도 어려운 문제에 대해서 lengthy generation을 하면서 잘 못푸는 모습 (reflexion x)을 많이 관찰했는데, 관련 내용이 있었으면 좋았을듯..