d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
논문 정보
- Date: 2025-01-02
- Reviewer: 김재희
- Property: DiffusionLM, SFT, Reinforcement Learning, Reasoning
1. Intro
1.1 결론
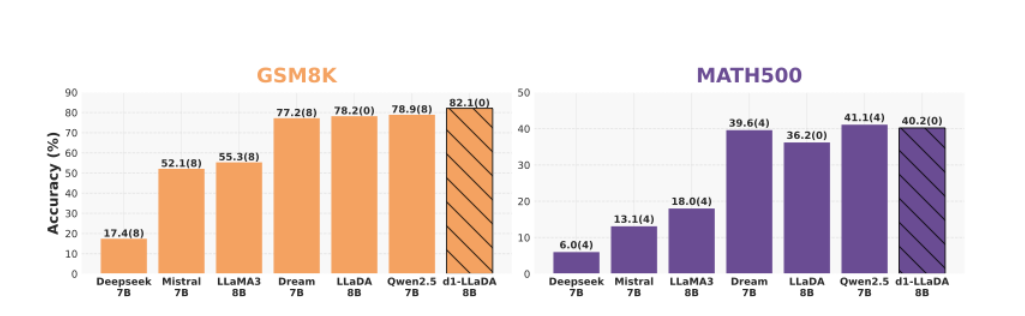
LLaMA3보다 높은 성능을 내는 Diffuion LM 강화학습 방법론.
1.2 RL(GRPO)
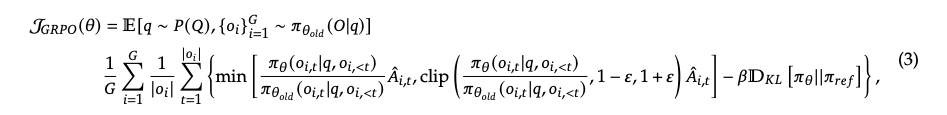
**특징: **
-
단일 쿼리에 대한 복수개의 샘플링 필요
-
토큰 레벨(advantage 항) 및 문장 레벨(KL 항)의 loglikelihood 필요
-
inner/outer loop 존재: 강화학습의 맥락에서 나온 개념인듯
-
inner loop: 이미 추출된 샘플, advantage 항, old policy를 이용하여 k회 반복해서 policy 모델을 업데이트 하는 것
-
장점: 샘플링이 추가적으로 진행되지 않으므로 빠른 수렴에 도움
-
단점: 특정 데이터에 대해 과적합되거나 학습 불안정 발생 가능
-
outer loop: 쿼리에 대해 n개의 샘플을 추출하고 advantage를 계산하는 과정
-
장점: 다양한 데이터에 대한 일반화 성능 확보
-
단점: 매 쿼리마다 많은 수의 샘플링을 동반하여 학습 속도가 느려짐
-
GRPO를 DDLM에 적용할 때 발생하는 문제점
-
토큰 레벨 loglikelihood 계산이 매우 비쌈
- DDLM: 각 토큰의 loglikelihood를 계산하기 위해 해당 토큰만 마스킹하고 forwarding해야 함
-
⇒ 이미 샘플링된 문장에 대해 문장 길이만큼 forwarding 필요
-
문장 레벨 loglikelihood 계산이 불가능함
-
AR 모델의 문장 레벨 계산: \log \pi*\textbf{AR} (o q) = \sum*{k=1}^{ o } \log \pi_\textbf{AR} ( o^l q, o^{<k}) - 단순하게 모든 토큰의 loglikelihood를 더하면 됨
-
DDLM의 forwarding 방식: \log \pi*{\textbf{DDLM}}(o q, MASK*{ o }) - 모든 토큰이 동시에 생성되어 문장 단위 loglikelihood로 구성 불가
-
⇒ 단순히 AR의 GRPO를 적용할 수 없음.
2. Method
2.1 Mean Field Estimation
-
복잡한 상호작용을 가진 시스템의 기대값 계산을 단순화하기 위해 독립 확률 분포로 근사하는 방법론
- k개의 output이 존재하는 시스템에서 원래는 각 k개의 output이 다른 output에 영향을 받는데, 독립이라 가정하고 확률을 계산
-
AR: 각 토큰의 생성이 이전 토큰에 종속적
- causal attention을 통해 자연스럽게 만족
-
DDLM: 각 토큰의 생성이 모든 다른 토큰에 종속적
-
bi-directional attention으로 인해 발생
-
각 토큰의 확률 및 문장 확률 계산: 반복적인 계산이 필요하여 매우 비싼 연산
-
→ Mean Field Estimation 적용을 통해 연산 단순화
⇒ 각 토큰의 생성을 타 토큰에 독립적이라고 가정 (가장 단순한 버전)
2.1 Sequence-level Loglikelihood Estimation
-
AR: 각 토큰의 loglikelihod로 분해 가능
-
DDLM: 모든 토큰이 동시에 생성되어 적용 불가
- 각 토큰이 다른 토큰 생성에 종속적
→ Mean Field Approximation을 이용하여 각 토큰이 독립적으로 생성되었다고 간주
→ AR처럼 sequence-level loglikelihood = 각 token loglikelihood의 합
| \log \pi*{\textbf{DDLM}}(o | q) = \sum^{ | o | }*{k=1} \log \pi_{\textbf{DDLM}} (o^k | q) |
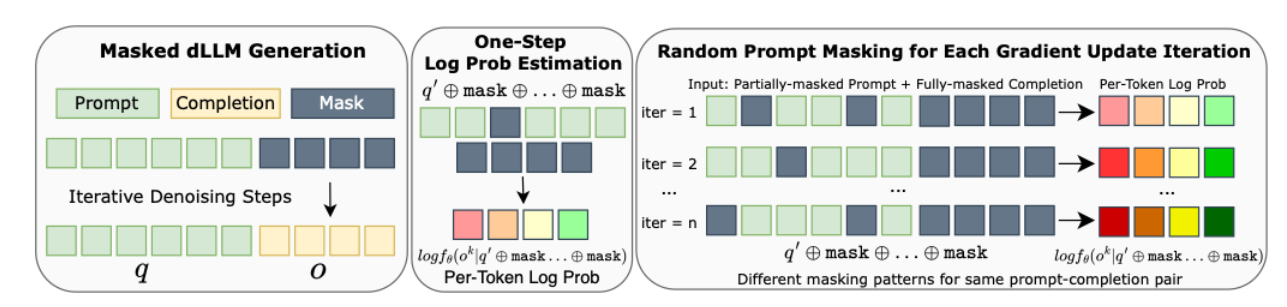
2.2 One-step Per-token loglikelihood estimation
-
기존 쿼리의 일부 토큰을 masking하고 전체 토큰의 loglikelihood를 그대로 사용
- masking 하는 이유는 estimation과 관련 X
2.3 diffu-GRPO: Policy Gradient Optimization for Masked dLLMs

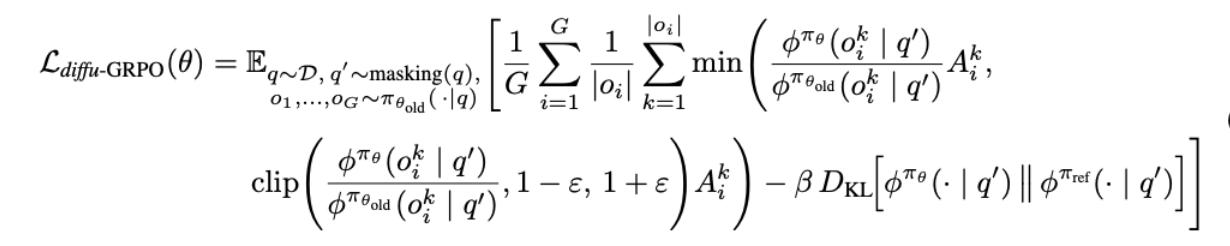
-
기존 GRPO와 다른 점: 쿼리의 일부 토큰을 masking
-
이외 점은 Mean Field Estimation을 통해 동일하게 구성됨 → 뭐여;;
-
masking이 가져오는 이점
- inner loop 계산 시 overfit을 방지하고 더 빠른 수렴이 가능하게 함
→ 매 inner loop iteration마다 다른 쿼리 토큰을 마스킹
- policy update의 regularization 혹은 augmented data로서 동작 가능
-
해당 장점은 사실 학습 속도에 매우 큰 영향을 미침
-
전체 학습에서 샘플링 수의 감소
-
inner loop을 많이 돌수록 모델은 더 빨리 수렴하게 됨
-
이로 인해 outer loop(sampling) 과정이 덜 실행되도 높은 성능 도달 가능
-
dLLM 특성 상 생성에 많은 비용이 들어가므로 매우 중요한 이점
-
-
2.4 SFT
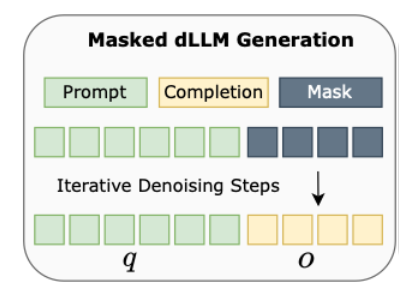
-
LLaDA에서 사용한 방식 그대로 활용
-
max length 만큼 masking 토큰을 입력하고 모델이 반복적으로 복원하도록 함
-
input: prompt text + [MASK] \timesmax_len
-
output: prompt text + completion text + [PAD] \times 나머지
-
-
학습 데이터: s1K 데이터 사용
-
reasoning ability 발현(instill)을 위해 수집 및 정제한 1,000개의 데이터셋
- 분야, reasoning 길이 등을 최대한 잘 조절하여 구축
-
3. Experiments
3.0 Setup
-
backbone: LLaDA-8B-Instruct, from scratch로 학습된 dLLM
-
reward: correctness, formatting
-
max len:
-
SFT: 4,096 → LLaDA의 Max len
-
diffu-GRPO: 256 → A5000 \times 4 로 진행해서 이 이상은 무리였던듯
-
3.1 Main
-
각 데이터 별 별도 학습 진행
-
SFT와 diffu-GRPO의 효과 검증
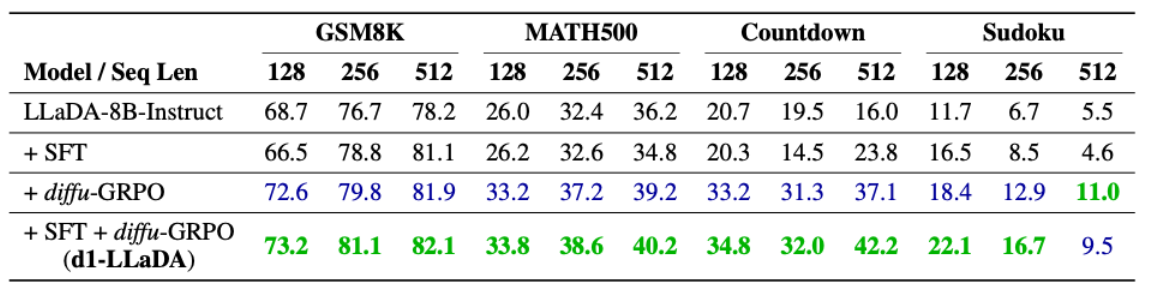
-
SFT: 일부 지표에서 성능이 개선되는 모습을 보임
- s1k 데이터를 통한 reasoning 성능 발현 효과
-
diffu-GRPO: SFT보다 훨씬 큰 성능 개선을 모든 지표에서 보임
- 우리 방법론 킹왕짱
-
SFT+diffu-GRPO: 최종적인 제안 방법론(d1)으로 훈련된 모델
-
SFT나 diffu-GRPO보다 훨씬 높은 성능 달성
-
SFT 학습 시엔 성능이 저하되던 경우에도 diffu-GRPO를 함께 사용하니 성능이 개선되는 모습을 보임
-
SFT와 diffu-GRPO를 함께 사용하는 것이 중요함
-
3.2 Unified Model
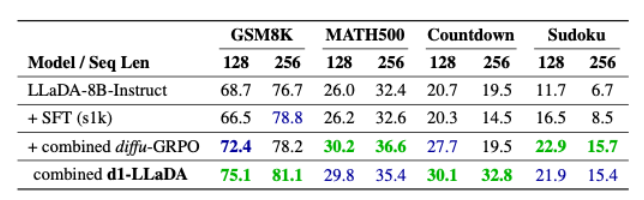
-
각각의 태스크로부터 동일한 크기의 데이터를 샘플링해서 함께 학습시키는 실험 세팅
-
놀랍게도 단일 모델보다 더 높은 성능을 달성
- 근데 512 length는 표기가 안되어 있음…
3.3 Code Domain
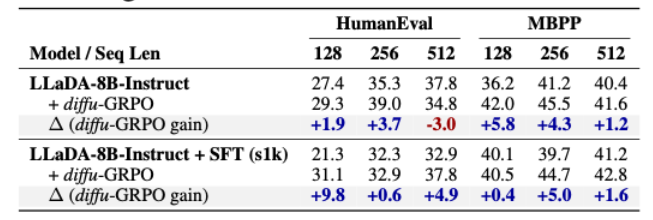
-
code domain에 대한 학습 및 평가 진행
- 학습 데이터: KodCode-Light-RL-10K: 문제와 정답이 모두 있어서 rl 학습 가능
-
SFT: 오히려 성능이 떨어지는 모습을 보이고 있음
- s1k 데이터셋 내에 코드 데이터가 부족해서 발생하는 현상
-
diffu-GRPO: 바로 diffu-GRPO를 적용해도 성능이 대부분 개선되는 모습을 보임
-
SFT후 적용 시에는 훨씬 큰 성능 개선을 보이는 경우 존재
-
(재희) s1k에 coding 도메인은 없지만 reasoning 능력 발현에는 도움이 되는 듯?
-
3.4 beyond trained length
-
재밌는 현상은 rl 시 sampling max length가 256임에도 평가 시 512 토큰 생성시에 개선되는 모습을 보이는 점 (AR은 안 그런가…?)
-
dLLM의 경우 학습 시 length에 overfit되지 않고 general reasoning strategy를 학습하는 것으로 보임
→ analysis 파트에서 계속
4. Analysis
4.1 Aha Moments
-
128,256의 길이 생성 시에는 aha moment가 보이지 않았음
- 지표 상으론 성능이 개선되었지만 reasoning path 구성이 SFT와 크게 다르지 않았음
-
512 길이를 생성시키자 aha moment 발현
-
SFT 및 RL을 통해 backtracking, self-correction 능력이 발현(instill)된 것으로 추정
-
512 sample
-

4.2 Generation Length
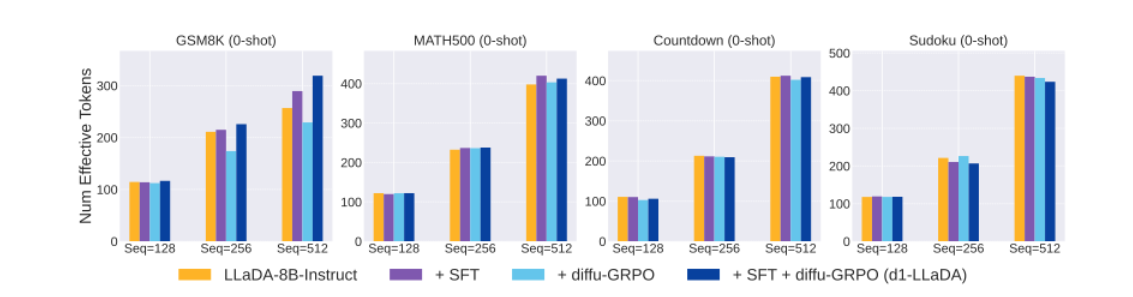
-
max length를 달리하며 각 태스크별 생성 길이 측정
-
(main) 학습된 길이(256)을 넘어 생성하여도 꾸준히 성능이 개선되는 모습을 보임
-
Effective Tokens: 실제 생성된 sequence의 평균 길이 (AR과 다르게 max len 만큼
를 채워서 forwarding해서 이렇게 표현하나…?) -
max len을 늘릴 수록 증가하는 경향성을 보임
-
하지만 AR의 RL 상황과 다르게 RL을 한다고해서 이전보다 생성길이가 길어지는 현상은 존재 X
- dLLM은 RL 시 reasoning step이 길어지도록 학습하는 것이 아니라 reasoning step을 잘 구성하도록 학습이 진행
-
4.3 inner loop 횟수
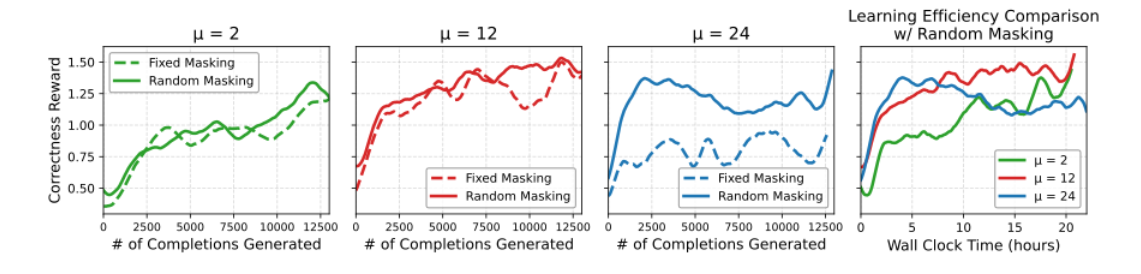
-
prompt masking을 통해 inner loop 횟수를 증가시켜도 안정적인 학습 확인 가능
- (재희) AR 모델의 경우 overfit 방지를 위해 보통 2회 이하로 설정하는듯?
-
inner loop iteration 동안 random하게 masking을 주는 것이 동일 masking보다 높은 성능 달성
- data augmentation or regularization 효과 존재
-
inner loop iteration을 늘리는 것이 실제 수렴 속도를 매우 빠르게 만듬
- 샘플링 횟수가 줄어들기 때문에 RL 시 소모되는 가장 큰 시간을 줄일 수 있음
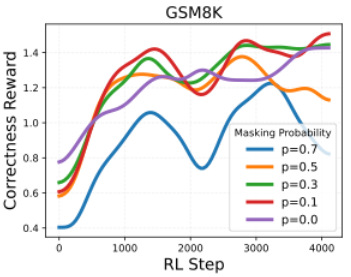
4.4 Masking Ratio
-
masking ratio를 적당히 주면 학습이 잘된다.
-
너무 높이면 학습이 불안정해진다.
7. Conclusion
-
Diffuion LM에서 RL을 위해 필요한 요소들을 잘 정의함
- token/sequence level likelihood 유도 방식
-
매우 단순하게 해결하여 성능 개선을 이끌어냄
-
Diffusion LM의 RL 시 현상들에 대해 (거의) 최초로 분석한 논문
-
scale이 너무 작아서 조금 더 큰 실험들에 대해 궁금하다.