DeepSeek R1
논문 정보
- Date: 2025-01-02
- Reviewer: 건우 김

https://substack.com/home/post/p-153314921
Introduction
최근에 post-training은 reasoning tasks, align/adapt to user preference 등 성능을 올리기 위해 많이 사용되고 있음. 특히 Reasoning capability 측면에서 보면 GPT-4-o1은 CoT의 reasoning process의 Length를 늘리며 inference-time 관점에서 scaling-out한 방법으로 처음 소개된 모델임. test-time scaling을 효과적으로 수행하기 위한 방법으로 다양한 선행 연구들이 있었지만, 이중에 어느 것도 o1과 같은 reasoning model의 성능을 달성하진 못했음.
본 연구에서는 Reinforcement Learning(RL)을 활용해서 Language Model의 reasoning 성능을 끌어올리는 방법을 타묵함. 연구의 주된 목표는 SFT 없이 RL만 활용해서 LLM의 reasoning capabilities를 키우는 것임.
DeepSeek-V3-Base을 backbone model로 두고 GROP (RL)로만 학습시켜 DeepSeek-R1-Zero를 만들었고, 이것의 reasoning 성능은 AIME2024에서 GPT-4-o1의 86.7% 수준의 성능을 보여줌.
하지만 DeepSeek-R1-Zero의 output은 가독성이 떨어지기 때문에, 이를 해결하고자 multi-stage로 학습되는DeepSeek-R1 모델을 개발함. 본 모델의 학습 과정은 아래와 같음
-
Cold start
-
Reasoning-oriented RL
-
Rejection Sampling and SFT
-
RL for all Scenarios
더 나아가서 DeepSeek-R1을 활용하여 여러 Open-source models을 대상으로 distillation을 진행시켰고, large model에서 보이는 reasoning pattern이 small models들에 transfer가 어느 정도 되는 것을 보여줌.
본 논문의 주된 Contributions은 아래와 같음
-
Post-Training: Large-Scale Reinforcement Learning on the Base Model
-
Distillation: Smaller Models Can Be Powerful Too
Approach
(논문의 내용과 jay alammar의 시각 자료를 활용함)
Overview
DeepSeek-R1은 DeepSeek-V3에서 소개된 모델을 backbone으로 활용함. (이때, DeepSeek-V3의 final model이 아니고 base model임)
DeepSeek-v3-Base에 SFT를 진행한 뒤에 RL을 적용하면 ⇒ DeepSeek-R1 !!
1. Long chains of reasoning SFT Data
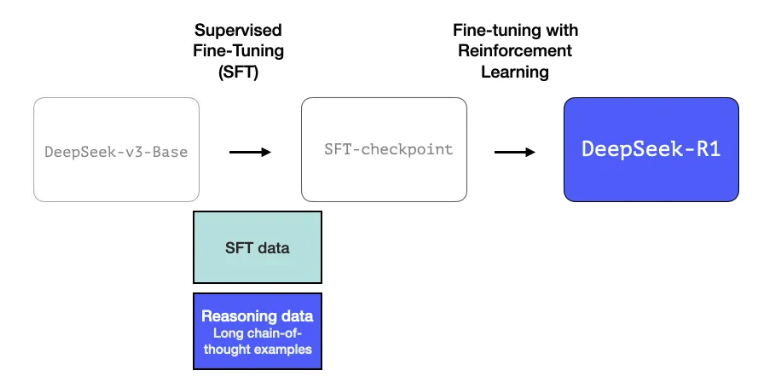
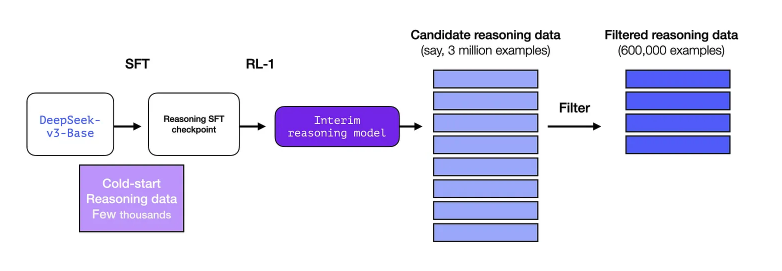
SFT를 진행하기 위해서는 많은 양의 labeled data가 필요한데, 이 만큼의 양을 사람으로부터 얻기는 어렵다. 따라서, 이런 high quality의 long chain-of-thought reasoning examples을 얻기 위해서 “Interim reasoning LLM”을 별도로 학습시켜서 활요함.
2. An interim high-quality reasoning LLM (but worse at non-reasoning tasks)
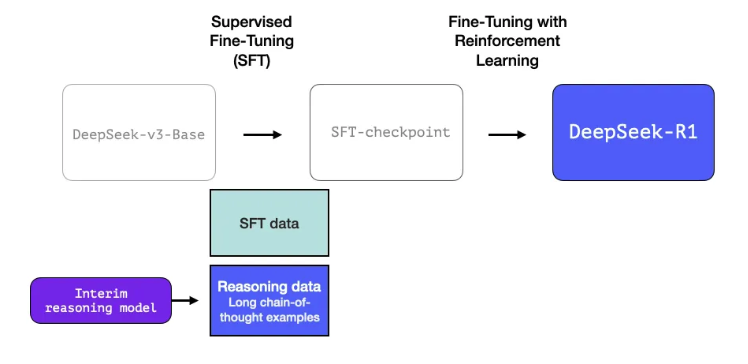
Interim reasoning model을 별도로 학습시켜서 SFT data를 구축하는데 사용함. 이때, Interim reasoning model은 DeepSeek-R1-Zero과 비슷하게 구축이 됨. (DeepSeek-R1-Zero를 먼저 만들고 난 뒤에, 여기서 영감을 얻어 DeepSeek-R1을 개발함)
3. Creating reasoning models with large-scale RL
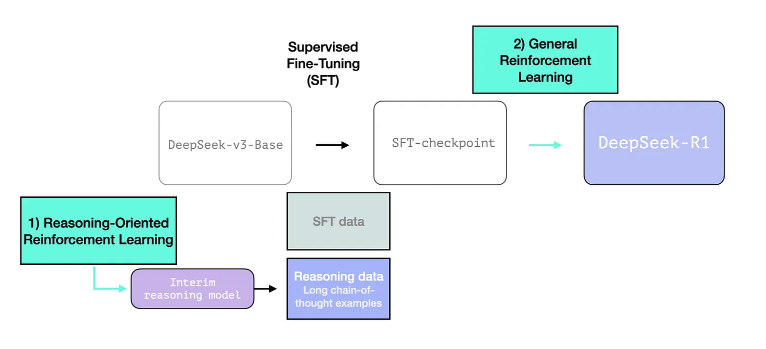
3.1 Large-Scale Reasoning-Oriented RL (R1-Zero)
여기서 RL은 interim model을 학습시키기 위해 사용하고 해당 모델로 SFT reasoning samples을 구축함. 아래 table에서 보이는 바와 같이 R1-Zero는 o1과 비슷한 수준의 Reasoning 성능을 보여줬기에, 이에 영감을 받아 SFT reasoning samples을 구축하고자 함.
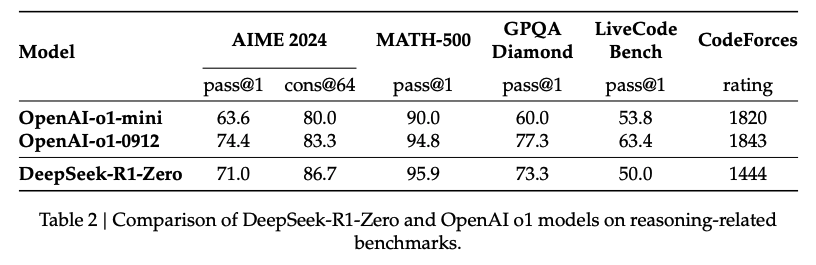
기존의 ML 모델들과 다르게, 더 이상 새로운 데이터를 추가하지 않아도 성능이 향상될 수 있음을 보여줌
-
14.8 Billion high-quality tokens으로 학습한 base model이 있는데, 이미 많은 데이터로 학습시켰기 때문에, 단순히 더 많은 데이터를 추가한다고 해서 성능이 획기적으로 좋아지는 단계는 지났을 가능성이 큼
-
Reasoning 문제는 데이터 없이도 성능이 개선될 수 있음.
-
일반적인 chat, wrtining은 사람이 직접 quality를 평가해야 하지만 reasoning 문제는 (수학, 코딩) 자동으로 정답을 확인할 수 있음. (ex. 2+2=5가 틀렸다는 것을 자명하게 알 수 있음)
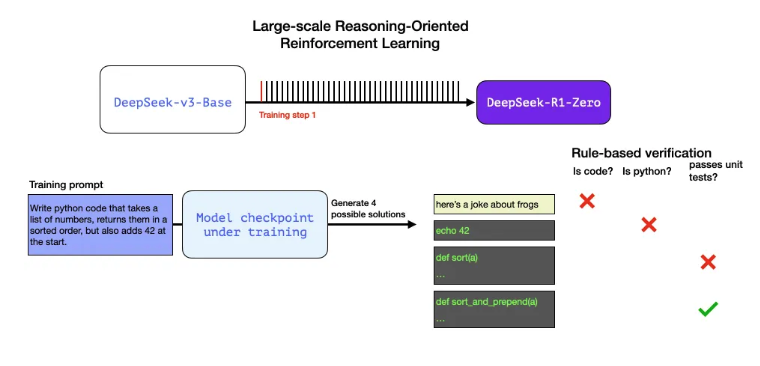
Example
Write python code that takes a list of numbers, returns them in a sorted order, but also adds 42 at the start.
위 문제는
-
linter와 같은 software를 활용하여 생성된 코드가 python 문법을 따르는지 확인할 수 있음
-
코드가 실제로 실행되는지 테스트할 수 있음 (실행되지 않으면 잘못된 코드임을 확인함)
-
실행 속도(퍼포먼스) 측정 가능.
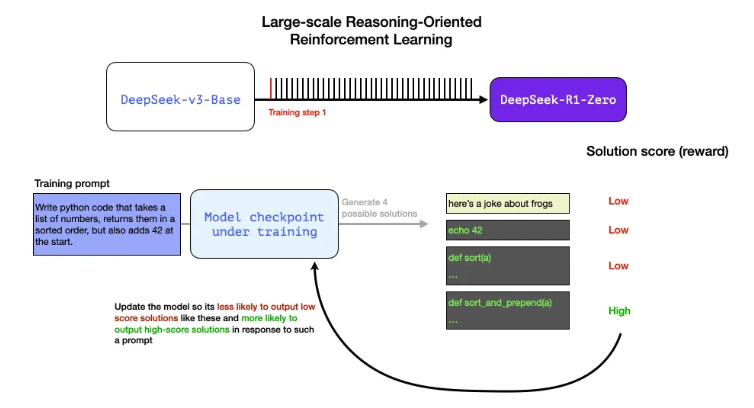
이때 사용한 System message는 아래와 같음 (명시적으로

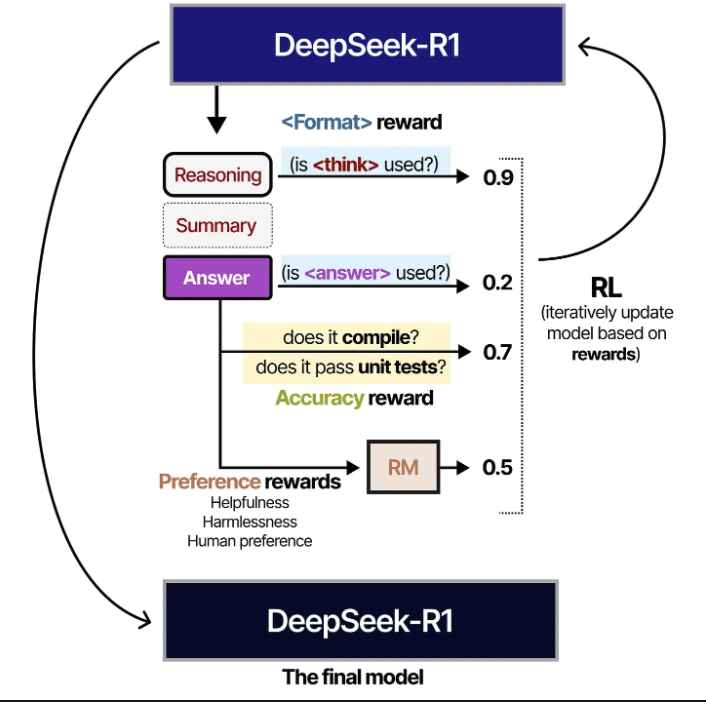
RL과정에서 사용된 두 가지 rewards는 accuracy reward (답변이 맞는지 확인)과 format rewards( think, answer tag를 잘 사용하고 있는지)가 있고, GRPO 알고리즘을 활용하여 model을 update함
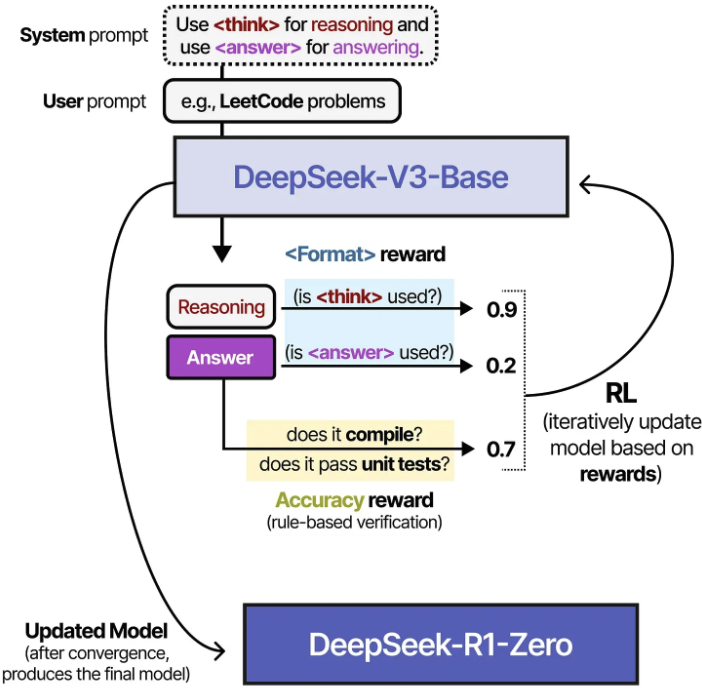
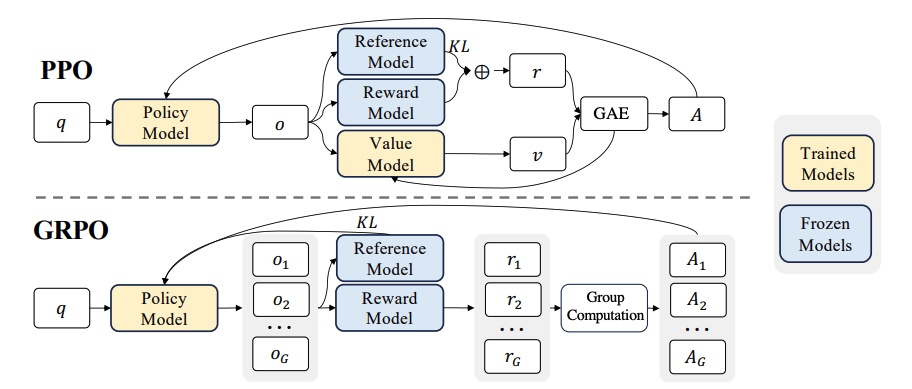
Group Relative Policy Optimization (GRPO)
PPO
Deepseekmath: Pushing the limits of mathematical reasoning in open language models. 참조
Proximal Policy Optimization (PPO): Actor-Critic RL algorithm
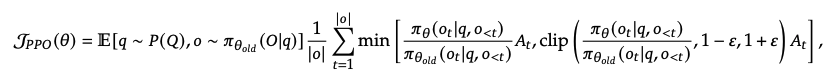
PPO Advantage를 뜯어보면 아래와 같음
- Advantage는 Rt - V(st)로 산출됨
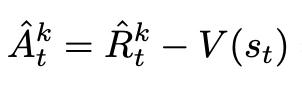
-
상태 st에서 얻을 수 있는 실제 return Rt^hat과 현재의 value function V(st)의 차이.
-
advantage 양수 (Rt > V(st)): 현재 policy가 기존 policy 보다 나음
-
advantage 음수 (Rt < V(st)): 현재 policy가 기존 policy 보다 별로
-
-
Return: 총 보상을 나타내는 return 값.
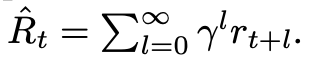
- rt는 실제 보상이고 gamma discount를 적용하여 미래 보상 반영
- reward signal: reward model이 산출한 값과 policy model과 reference model의 ratio를 KL penalty로 적용
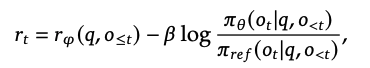
Gradient Update process
-
Actor update (PPO Objective function)
-
Actor policy model weight update
-
Advantage를 활용하여 좋은 policy 방향으로 update 유도
-
Critic update (Value function)
-
Critic Loss를 사용해서 V(st)를 Rt에 가깝게 만들도록 MSE
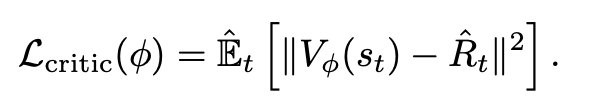
- critic model의 역할은 현재 state의 value를 예측하고, 실제 reward와 비교하여 advantage를 계산하는 것을 담당
Actor update → Critic update
-
PPO에서는 별도의 critic model (=value function)을 사용하여 policy model의 행동을 평가하는데, critic model의 크기는 policy model과 동일하거나 비슷하기에 computational cost가 높은 단점이 있음
-
critic model → group scores로 대체하여 baseline을 추정하는 방식
-
Core Ideas
-
query q에 대해 기존 policy model의 여러 개의 responses (o1, o2, … oG)을 sampling함
-
그룹 내에서 relative compairson을 통해 baseline을 추정함
-
new policy model은 위 정보를 기반으로 objective를 maximize하도록 학습
-
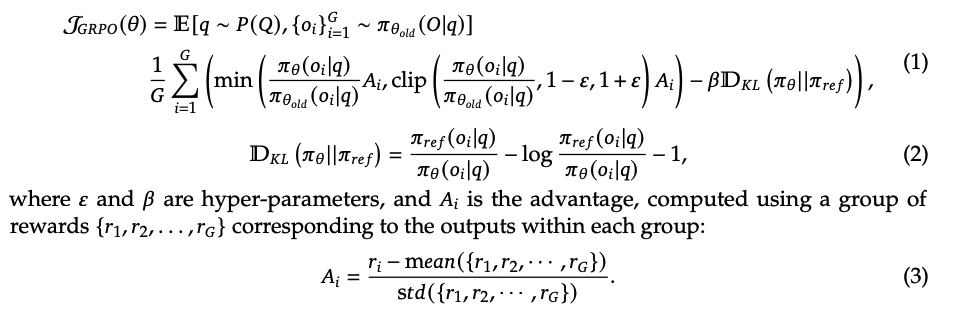
(1) PPO의 Clip Trick을 활용함
-
new policy model과 기존 policy model의 ratio 비교
-
Ai: 각 response oi에 대한 advantage
-
Clip Trick: +- eps 범위에서 ratio를 제한하여 큰 update 방지
→ 이전 policy model 대비 new policy model이 크게 변화하지 않도록 제한하면서 advantage을 극대화 시킴
(2) KL Divergence
- policy model이 reference model 대비 분포의 차이를 최소화 시켜줌
(3) Advantage (Ai)
-
ri: response oi의 reward 값
-
group 내 mean rewards를 빼고 std로 나누어 정규화 시킴
→ 각 응답의 상대적인 보상을 group 내에서 정규화하여 advantage를 구함
GRPO의 알고리즘은 아래와 같음

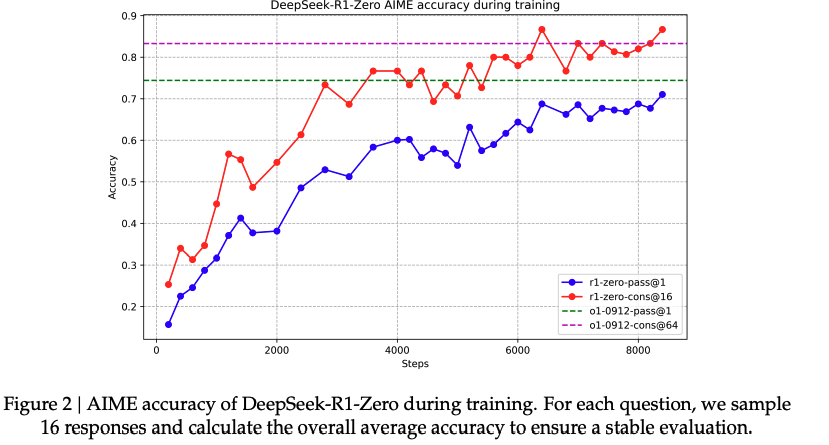
rule-based reward signal을 활용하여 model을 update하고 학습이 진행됨에 따라 성능이 올라가는 것을 볼 수 있음. (Step이 커짐에 따라 성능도 비례하며 올라감)
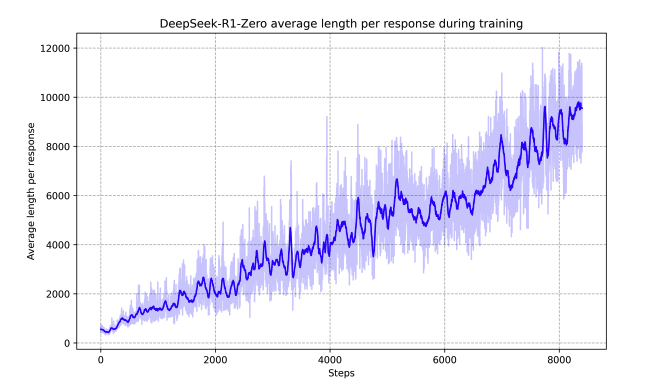
위와 같이 학습한 R1-Zero는 reasoning tasks에서 높은 성능을 보여주긴 하지만, poor readability와 같은 문제점이 존재함. (Step이 커짐에 따라 모델이 생성하고자 하는 text length도 길어짐)
따라서 RL로만 학습하는 방식이 아닌 SFT 학습과정을 포함시킴 R1을 소개함.
3.2 Creating SFT reasoning data with the interim reasoning model
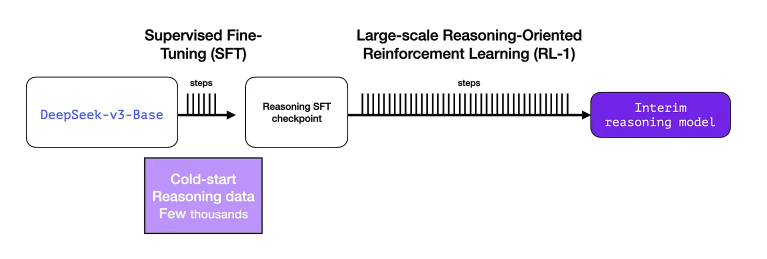
- Cold Start
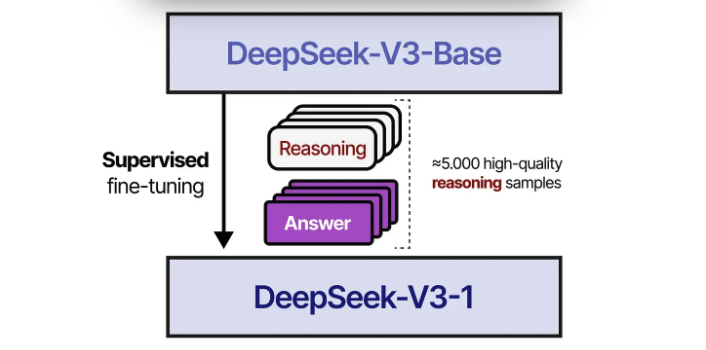
-
R1-Zero와 다르게 초기 불안정한 학습을 방지하고자 수천개의 long CoT samples을 활용하여 SFT를 진행하여 initial RL actor를 구축함.
-
samples을 구축할 때는 few-shot prompting으로 구축하고 human annotators가 post-processing 진행함
-
Cold Start으로 데이터를 구축하면 되는데, RL 과정을 하는 이유는 scale of data!!
-
Cold Start는 5,000개 데이터만 있으면 되지만 R1을 학습시키기 위해서는 600,000개가 필요함
-
Reasoning-oriented Reinforcement Learning
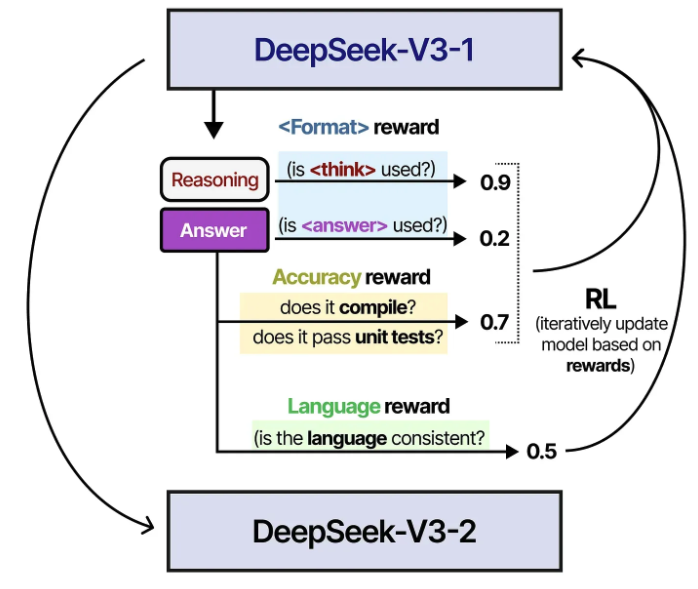
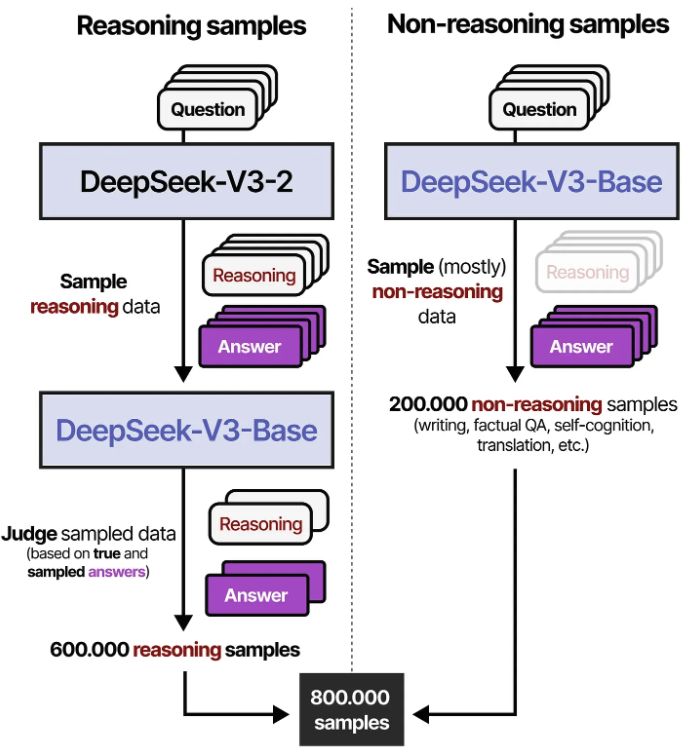
Interim model을 활용하여 600,000개 samples을 만들고 난 뒤에 DeepSeek-V3에서 사용한 SFT dataset samples 200,000개와 결합하여 최종적으로 800,000 SFT samples 구축
3.3 General RL training phase
위와 같이 SFT로 학습된 R1은 reasoning 및 non-reasoning tasks를 잘 수행하지만, 더 다양한 applications에 확장시키기 위해서 Llama2에서 사용한 helpfulness / safety reward model을 활용하여 일반적인 RL 학습을 진행함
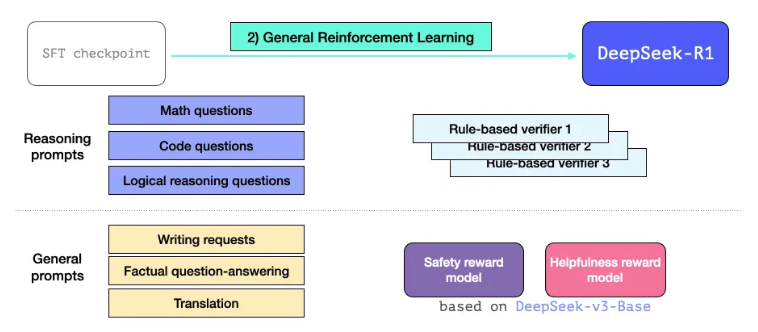
여기서는 기존에 사용하던 reasoning modeling을 위한 reward verifier와 llama2에서 사용한 reward model을 동시에 같이 사용함
*Distillation: Empower Small Models with Reasoning Capability
DeepSeek-R1은 671B params를 갖고 있기 때문에, 일반 hardware에서 사용하기에 어려움이 있음. 본 연구에서 R1의 reasoning quality를 Qwen-32B와 같은 open source model로 distillation을 진행함.
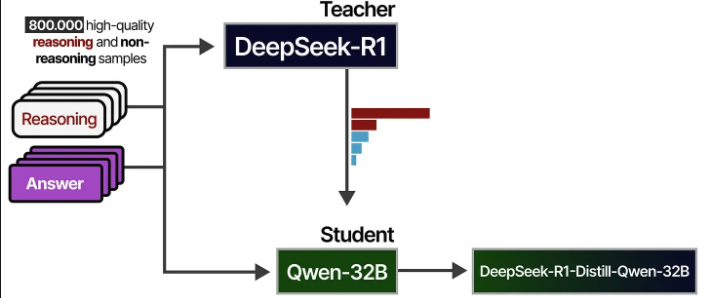
800,000개의 reasoning 및 non-reasoning samples로 학습을 진행함
Experiment
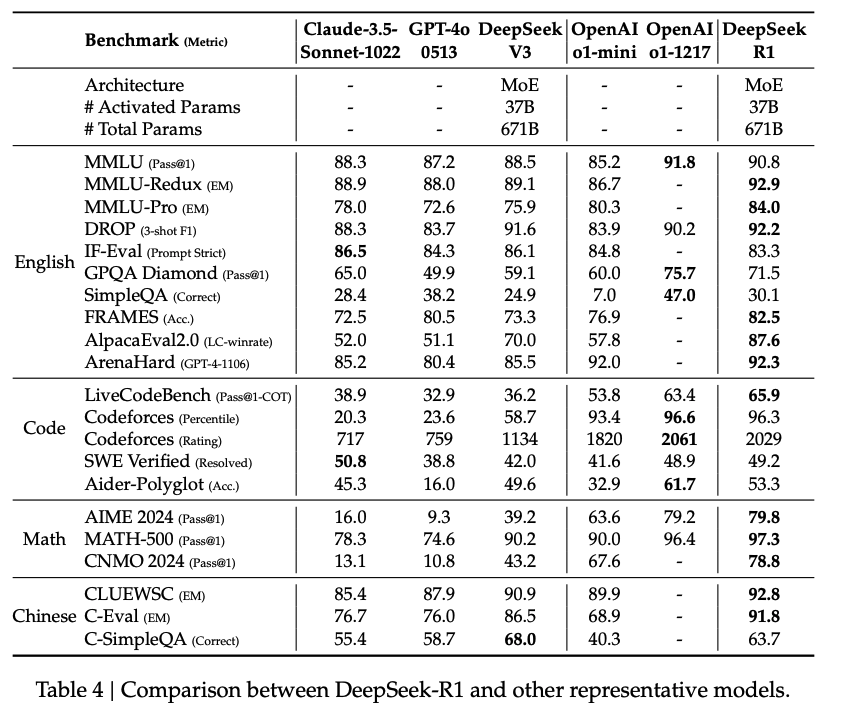
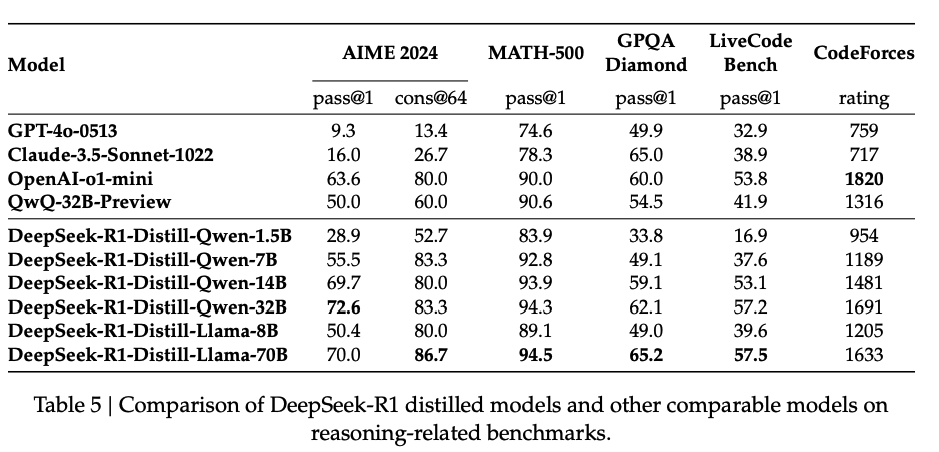
Discussion
Distillation vs. Reinforcement Learning
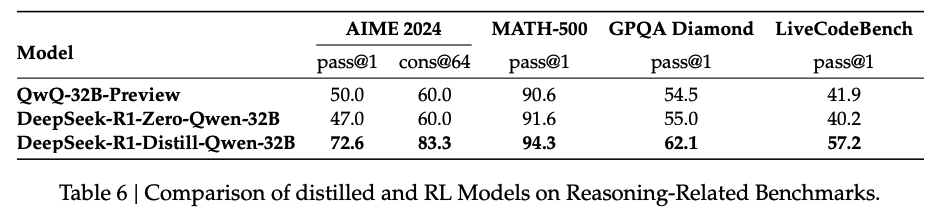
Can the model achieve comparable performance through the large-scale RL training discussed in the paper without distillation?
→ Qwen32B-base로 실험한 결과 Zero모델은 R1에 비해 다소 떨어진 성능을 보이고 QwQ32B와 비슷한 성능을 보여줌
-
powerful models을 small model로 distillation하는 것은 효과적이나, **small model이 자체적으로 large-scale RL을 진행하는 것은 computaitonal cost가 큰것에 비해 성능이 좋지 **않음
-
distillation이 effective하지만 intelleigence 넘어 도달하는 것은 아직도 powerful base model과 larger-scale RL 알고리즘이 필수적임
Unsuccessful Attempts
(SKIP)
Conclusion
-
Reinforcement Learning Approach: DeepSeek-R1-Zero는 SFT없이 RL만으로 강력한 성능을 달성했으며, DeepSeek-R1은 초기 데이터와 RL을 활용하여 OpenAI-o1-1217 수준의 성능을 보여줌.
-
Distillation to Smaller Models: DeepSeek-R1이 80만 개의 학습 샘플을 생성하여 small model을 tuning한 결과, DeepSeek-R1-Distill-Qwen-1.5B는 수학 벤치마크에서 GPT-4o 및 Claude-3.5-Sonnet보다 높은 성능을 보여줌.
- Distilled-Qwen-32B는 한국어 매우 못함..+ 답변 길이가 매우 김