DeepSeek v3
논문 정보
- Date: 2025-02-18
- Reviewer: 김재희
- Property: LLM, Pre-Training, MoE
1. Intro
Contribution
지금까지 공개된 모든 좋을 것 방법론을 모두 가져다 써봤다!
하드웨어 최적화를 열심히 해서 최대한 효율적으로 학습했다!
-
MoE 학습 시 발생 가능한 overhead와 학습 불안정 요소 해소
-
transformer 구조 변경을 통한 caching 효율화 방법론 제안
-
Multi-Token Prediction을 통한 추가 학습 loss 이용
-
학습 인프라 최적화를 통한 분산학습 방법론 제안
-
fill-in-the-middle 학습을 통한 추가적 모델 유연성 확보
-
distillation 등을 통한 post-training 최적화
2. Architecture & Loss functions
2-1. 모델 구조
2-1-1. Overall Architecture
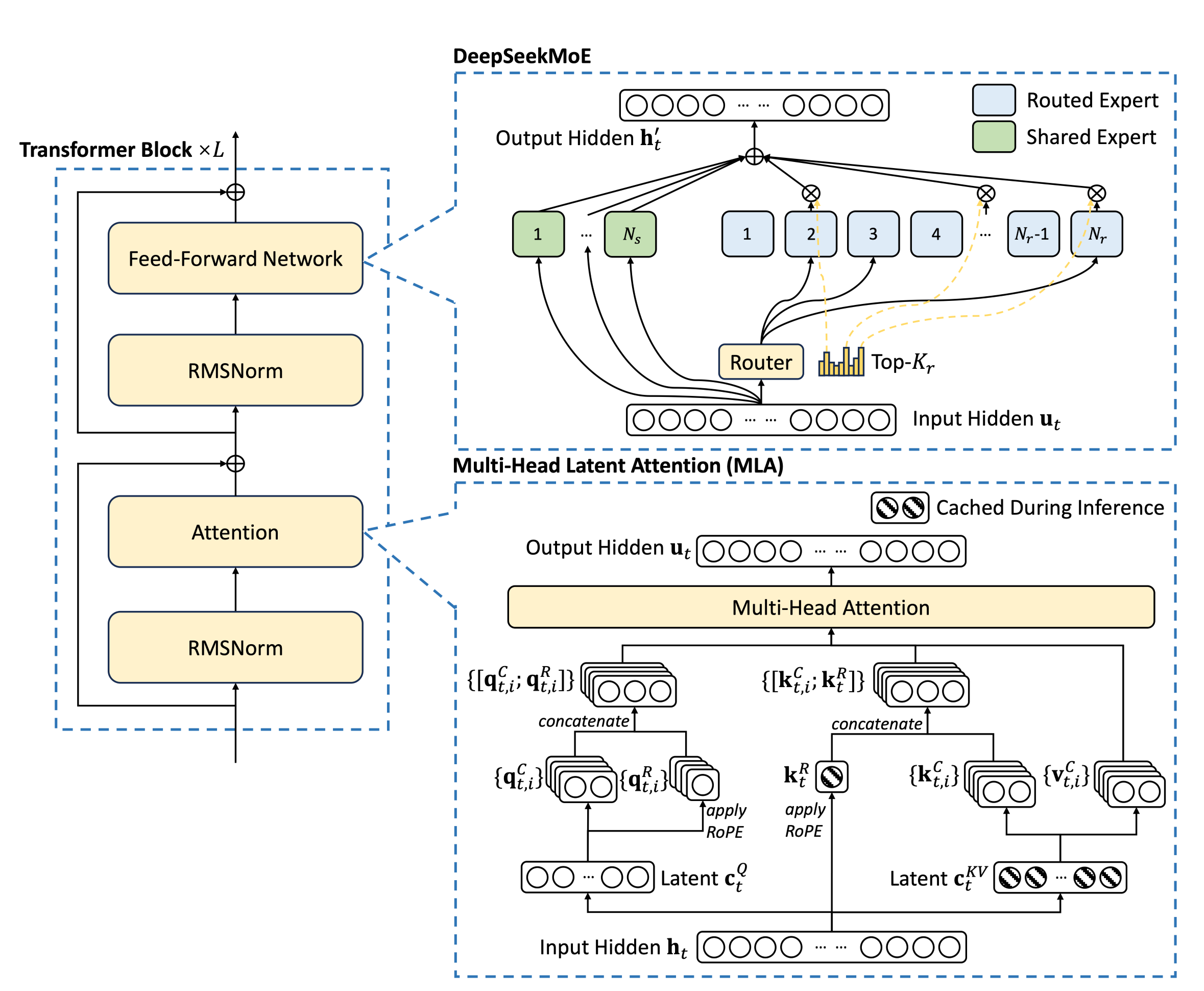
-
기존 transformer 구조 거의 유지
-
FFNN: MoE 구조 사용 → 존재하던 방법론
-
Attention: Multi-head Latent Attention(MLA) 구조 사용 → 새롭게 제안
2-1-2. Mixture-of-Experts
-
기존에 널리 활용되던 MoE 구조 차용
-
shared expert와 routed expert로 구분하여 사용 → DeepSeekMoE 논문 결과
- shared expert: routing 결과와 관계없이 항상 사용되는 expert, routing 시 고려대상 X
→ 레이어당 1개
- routed expert: 실제로 routing을 통해 사용되는 expert
→ 레이어 당 256개 중 8개
-
routing: sigmoid 함수를 이용하여 입력값에 대한 각 expert의 활용 점수(affinity score) 산출
- affinity score 상위 Top-K 개의 expert를 이용하여 forward
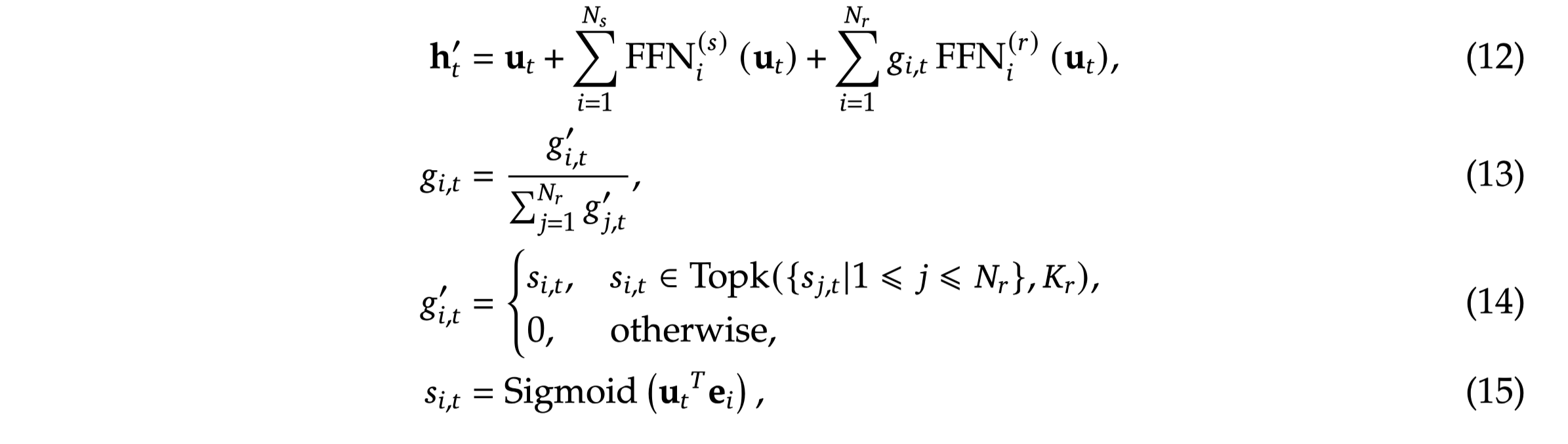
2-1-3. Multi-head Latent Attention
KV Caching
-
K, V Caching: 생성 시 과거 시점의 k, v representation을 caching하여 연산량을 절감하는 방법론
- 광범위하게 사용/trasnformers library, 최근 decoder 모델에서 거의 기본적으로 사용
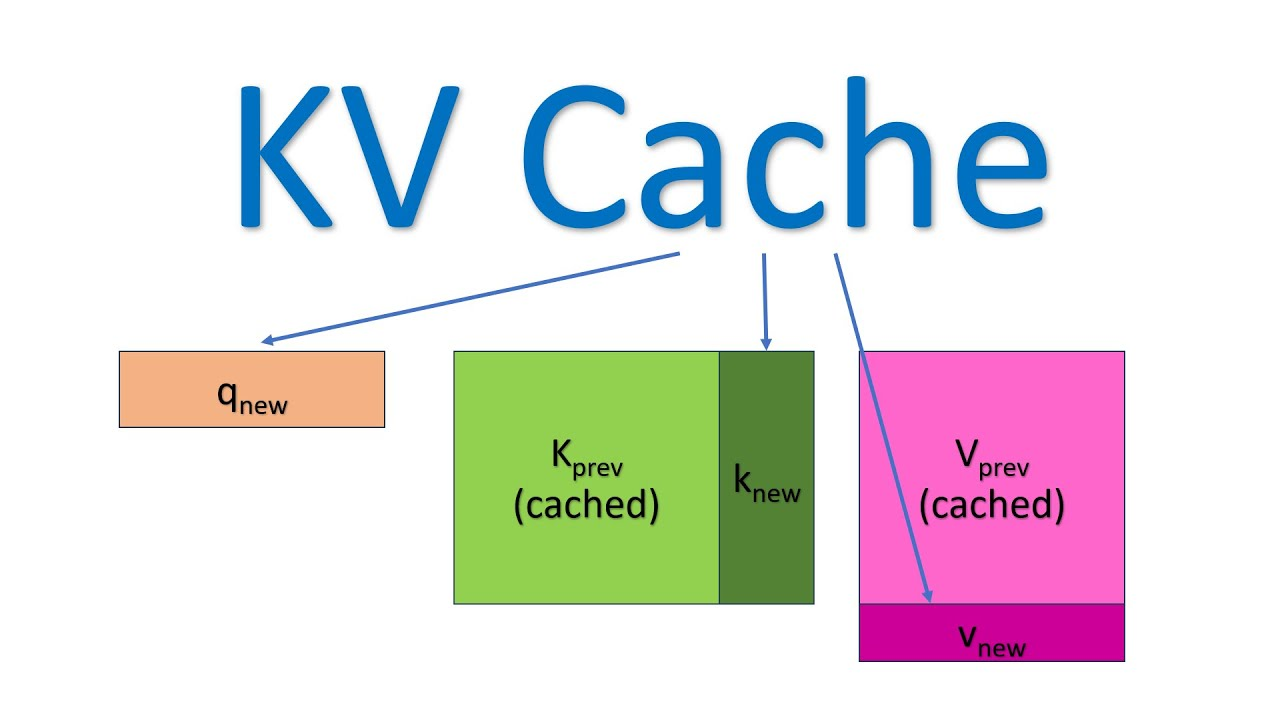
-
Pros: 연산해야 하는 representation이 새롭게 입력된 last token으로 매우 효율적
-
Cons: 이전 시점의 모든 layer의 모든 k, v를 저장해야 함
- long context 시 매우 많은 vram을 차지하게 됨
Multi-head Latent Attention
- basic idea: caching 해야 하는 representaiton을 줄이고, 조금만 더 연산해보자
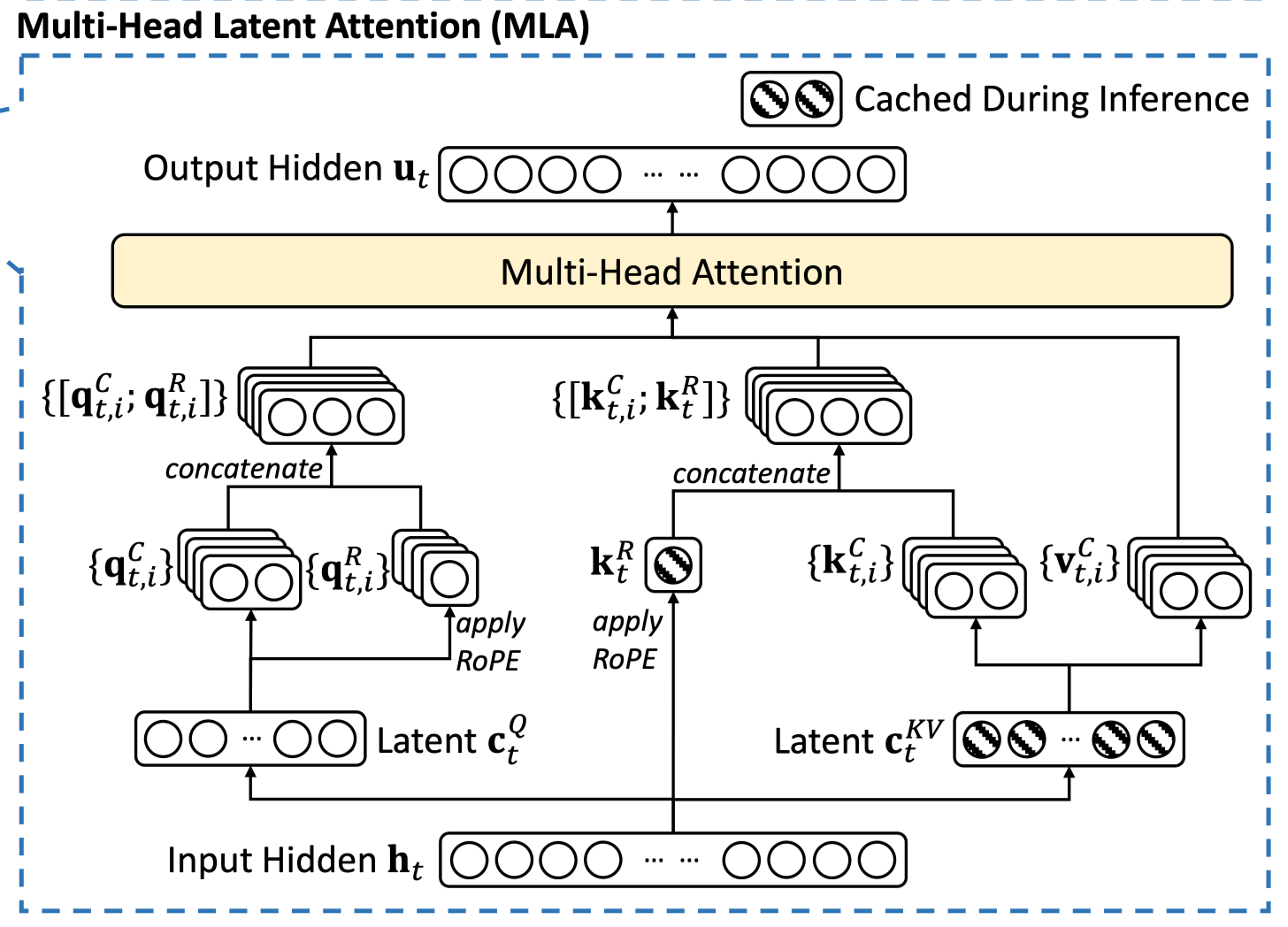
-
(eq1) c: k, v를 생성하는 compressed latent vector (512 차원)
-
caching의 대상 → 기존 caching 대비 매우 적은 크기의 vector만 cacing하면 됨
-
head 별 구분없이 동일한 c vector 이용
-
⇒ RoPE 사용 불가능 (K, V가 동일한 벡터에서 생성되니까)
-
(eq3) RoPE가 적용된 k vector를 별도로 생성하여 저장
-
(eq2, 5)cached c vector로부터 head 별 다른 projection matrix를 이용하여 k, v 생성
-
(eq3) RoPE 적용을 위해 RoPE 적용 k와 기존 k를 concat하여 사용
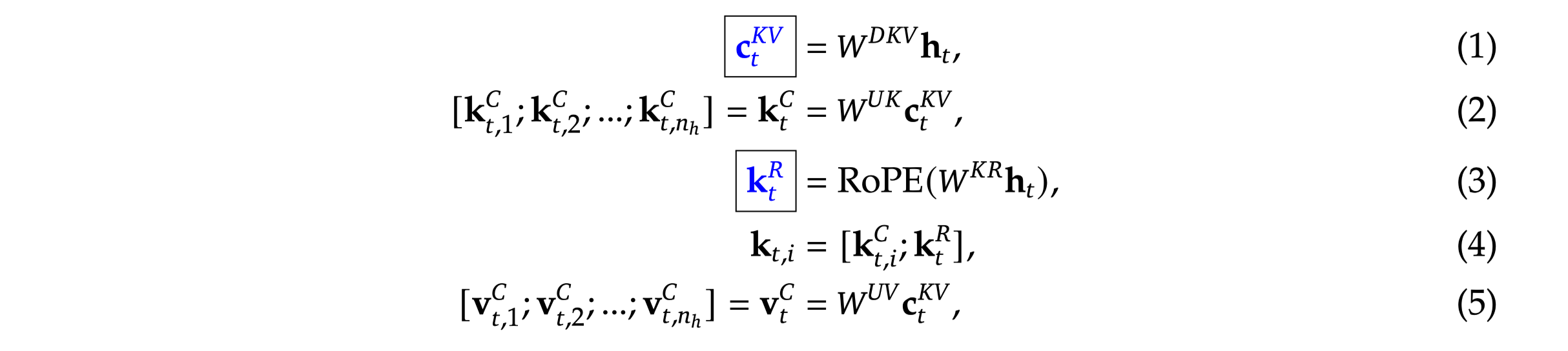
- 실제 attention 작업 시에는 기존 masked self attention과 동일하게 진행
2-2. Training Loss
2-2-1. Auxiliary-Loss-Free Load Balancing
-
Load Balancing: MoE 구조 학습 시 각 expert 들이 비슷한 횟수만큼 학습에 활용될 수 있는 장치
- load balancing을 고려하지 않으면 일부 expert만 과도하게 학습되어, MoE의 목표에 부합 X, 성능 저하 발생
-
기존 해결책: Auxiliary Loss를 이용하여 각 expert의 선택 분포를 uniform하도록 제한
-
DeepSeek v3: 각 expert에 대한 bias term을 도입하여 affinity score 계산 시 활용
- bias term의 값이 클수록 해당 expert가 선택될 경향이 높아지게 됨
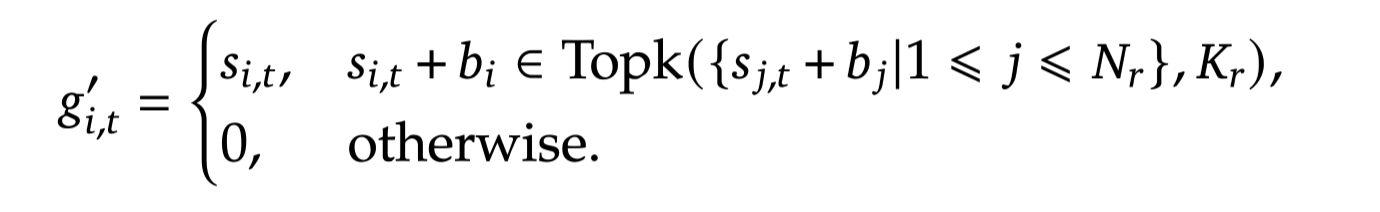
-
bias term은 end-to-end 학습 대상 X
-
매 step마다 실제 각 expert의 선택 횟수를 이용하여 bias term 값 조정
-
평균보다 많이 사용된 expert: \gamma만큼 bias 감소
-
평균보다 적게 사용된 expert: \gamma만큼 bias 증가
-
-
⇒ 자연스레 expert들이 uniform하게 사용되도록 유도
2-2-2. Complementary Sequence-Wise Auxiliary Loss
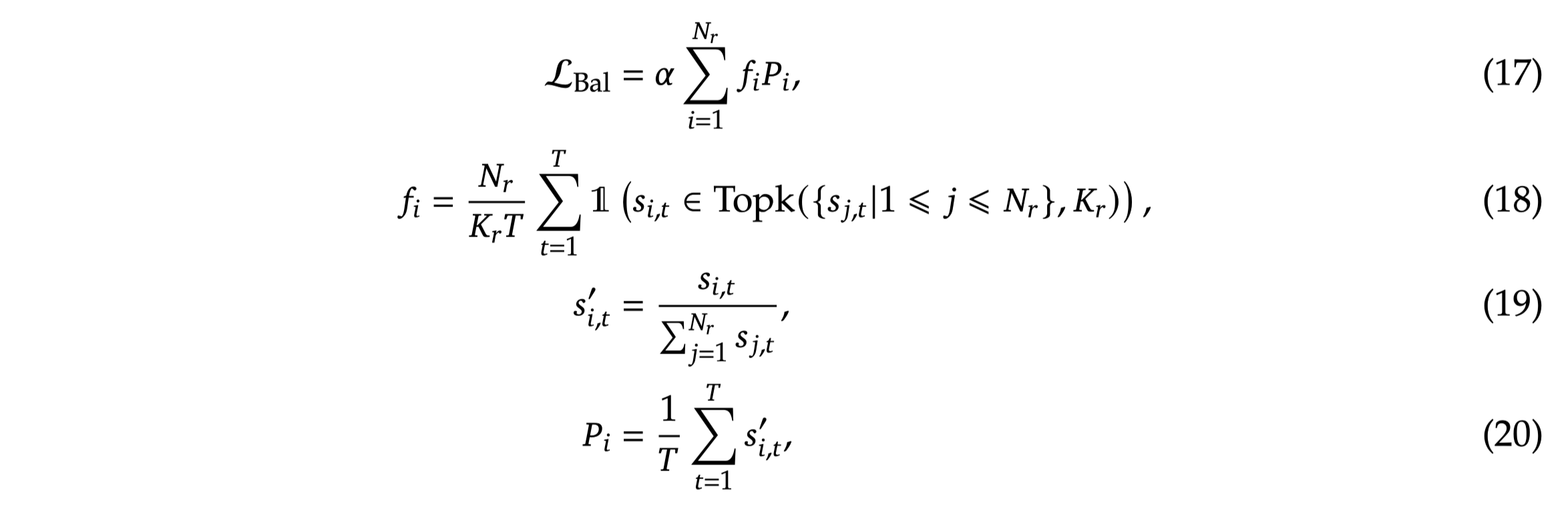
-
여전히 load imbalance 문제가 발생할 수 있음 → 특히 한 sequence 내에서!
-
하나의 sequence 내에서도 Load balance 하도록 auxiliary loss term 도입
- seq len(T) 내에서 전체 expert 수( K_r) 중에 선택되는 expert의 수(N_R)를 계산하여 각 expert가 uniform하게 선택될 수 있도록 강제
2-2-3. Multi-Token Prediction
-
MTP: pretrain 시 next token 외에도 t+k 시점의 미래 시점 토큰도 함께 예측하도록 학습하는 것
-
목표: 모델이 미래 생성 문장에 대한 planning 등의 능력을 갖추도록 함
- 실제로 하나의 시점에서 미래 다수의 시점 토큰을 생성하고자 하는 것이 X
-
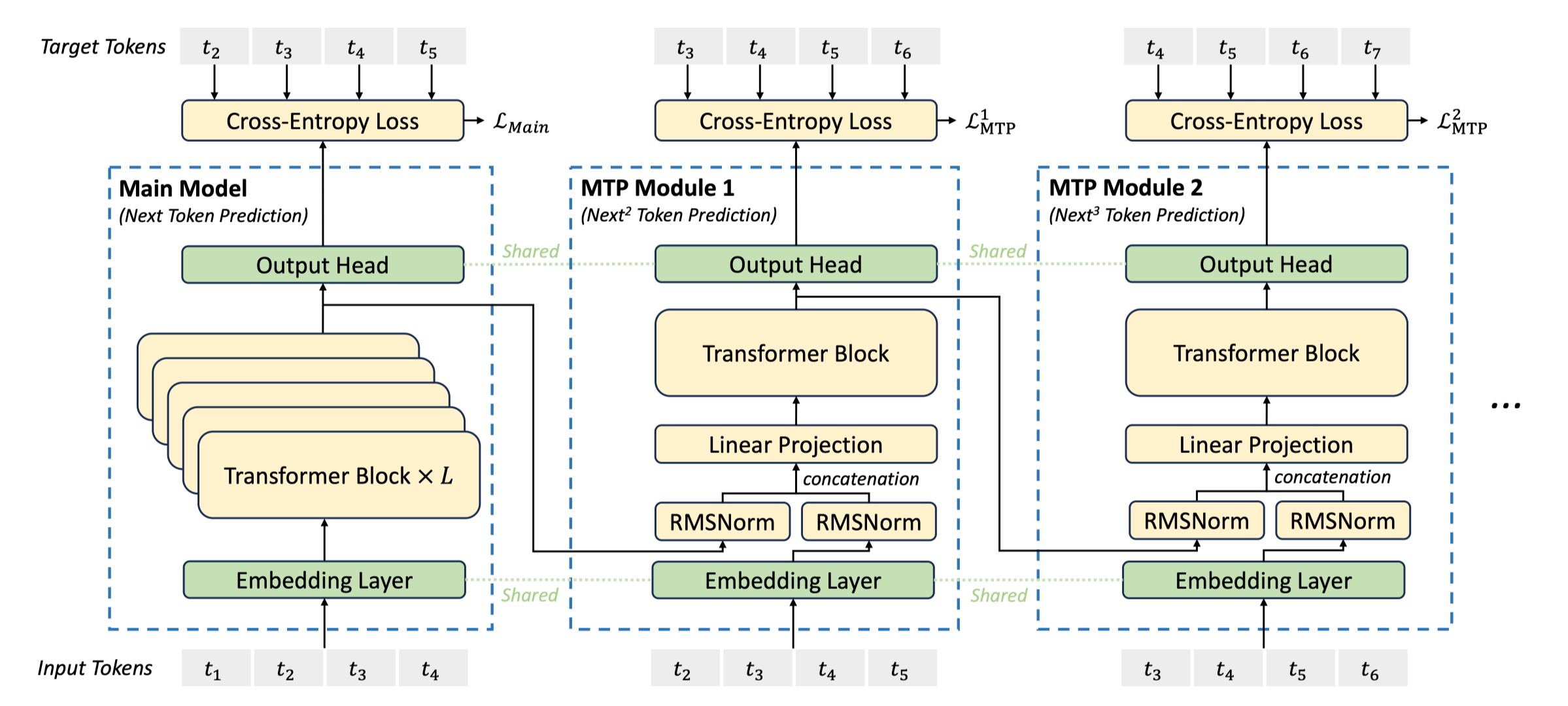
-
원 MTP 논문과 달리 MTP Module 도입
-
MTP Module 1: t+2 시점의 토큰 예측 태스크 학습 모듈
-
1 transformer layer로 구성
-
lm head/embedding layer는 Original model과 공유
-
이전 MTP module/original model로부터 last hidden state을 가져와 활용
-
-
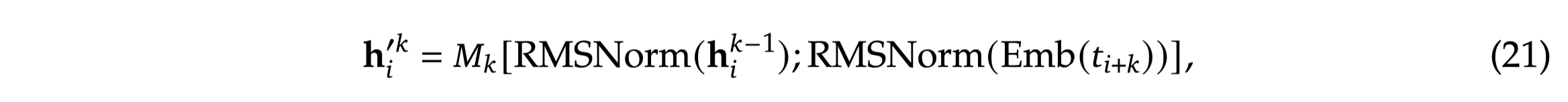

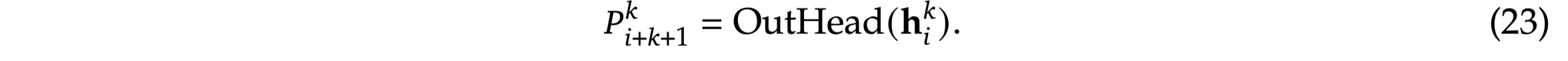
Forwarding Process (MTP Module 2)
-
module 1의 last hidden representation을 가지고 와서 RMSNorm 통과
-
t+1번째 token부터 embedding layer에 통과시켜 representation 획득 → t+2 시점의 단어 예측을 위한 추가 정보로서 활용하는 듯
-
1과 2의 representation을 concat하여 transformer layer 및 LM Head를 통과시켜 예측 진행
MTP 모듈은 학습에만 사용되고 추론 시 사용되지 않습니다. DeepSeek v3는 next token predction만 수행하여 inference합니다.
3. Pretraining
3-1. Data
-
이 놈들이 데이터를 어떻게 수집했는지 밝히지 않고 있습니다…
-
수학 및 코딩 데이터의 비중 증가
-
중국어 및 영어를 포함한 다양한 언어 데이터 포괄
Fill-in-Middle strategy (이미 기존에 공개된 논문)
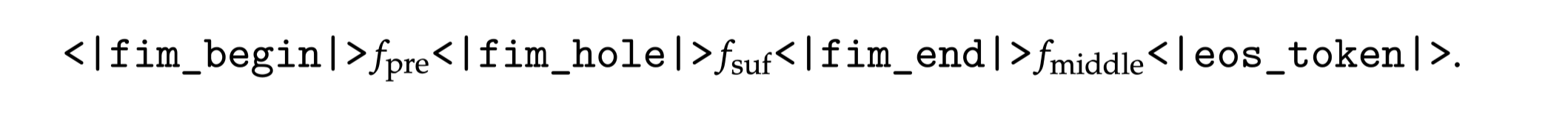
-
Decoder-only 모델에게 문장의 시작(prefix)와 끝(suffix)를 주고 중간 부분을 생성하도록 시키는 것
-
실제 LLM 활용 시 중간 부분을 채워야 하는 경우가 다수 존재. 해당 능력 학습 가능
-
ex) Copilot: 코드를 보여주고 수정하라고 요쳥
-
from transformers import AutoModelForCausalLM, AutoTokenizer
data = load_dataset('imdb')
model_id = 'bert-base-uncased'
model = AutoModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
- BPE 토크나이저를 사용하여 128K 보캡 구축
3-2. Long Context Extension
-
학습 효율화를 위해 context window 길이를 4k(14.8T token) → 23k(1000 step) → 128k(1000 step)로 점차적으로 확장
-
YaRN 방식을 이용하여 extension 학습 진행
- RoPE에 대해 scaling factor를 두고 interpolation하는 것 같은데 잘 모르겠어요…
4. Post-Training
- RLHF 등의 학습을 진행하기 위한 레시피 제시
SFT
4-1. Reasoning Data
-
고품질의 reasoning data 확보를 위해 DeepSeek-R1 모델 활용 → R1 논문에서 자세히 소개
-
코드/수학 등의 도메인에 대한 고품질 데이터 확보를 위해 각 도메인 별 expert 모델 학습
-
SFT/RL 기반 학습 진행
-
<problem, original response>를 입력으로 하여 R1 모델의 출력값을 산출
-
<problem, original response, r1 response>를 입력으로 하여 각 도메인 모델이 개선된 reasoning/answer를 도출
-
rejection sampling을 통해 고품질의 SFT 데이터 확보
-
4-2. Non-Reasoning Data
-
reasoning이 필요없는 creative writing 데이터는 이전 모델(DeepSeek-V2.5)를 통해 답변 생성
- 사람이 검수하여 해당 답변의 품질 검증
RL
4-3. Reward Model
-
Rule-based RM과 Model-based RM을 혼용하여 사용
-
GRPO를 통해 학습 진행
- multi response를 통한 normalizing으로 value model 사용 X
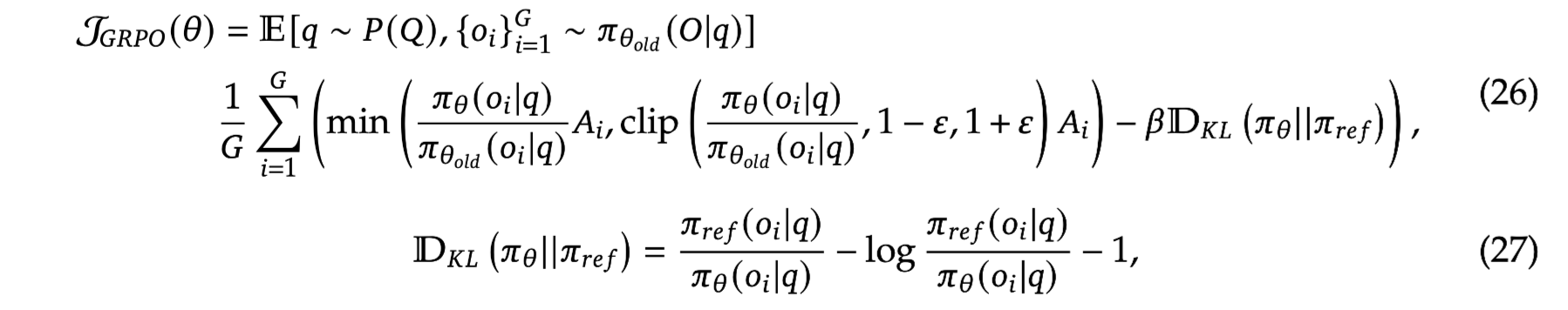
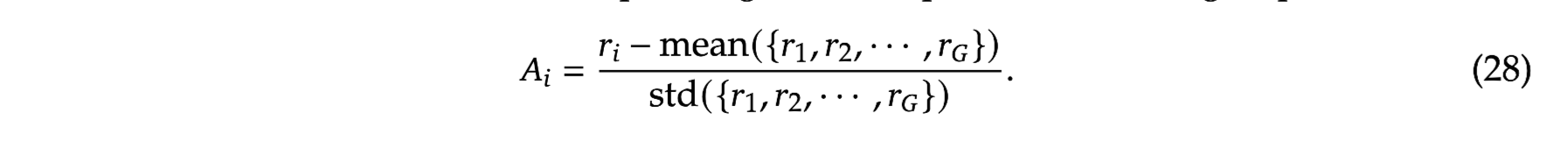
5. Experiments
Pretrain
- Main Table
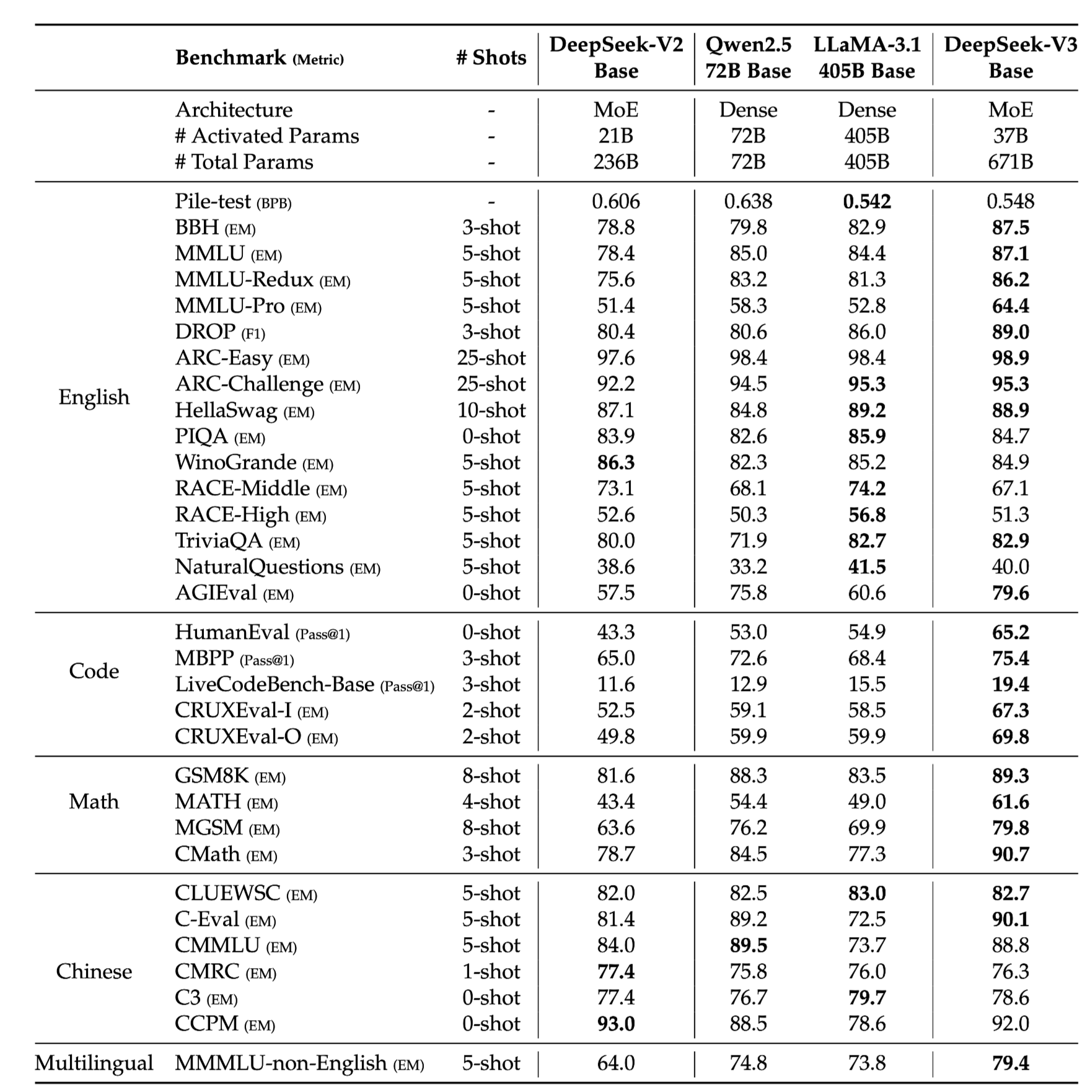
- 성능 킹왕짱!
5-1. MTP Ablation
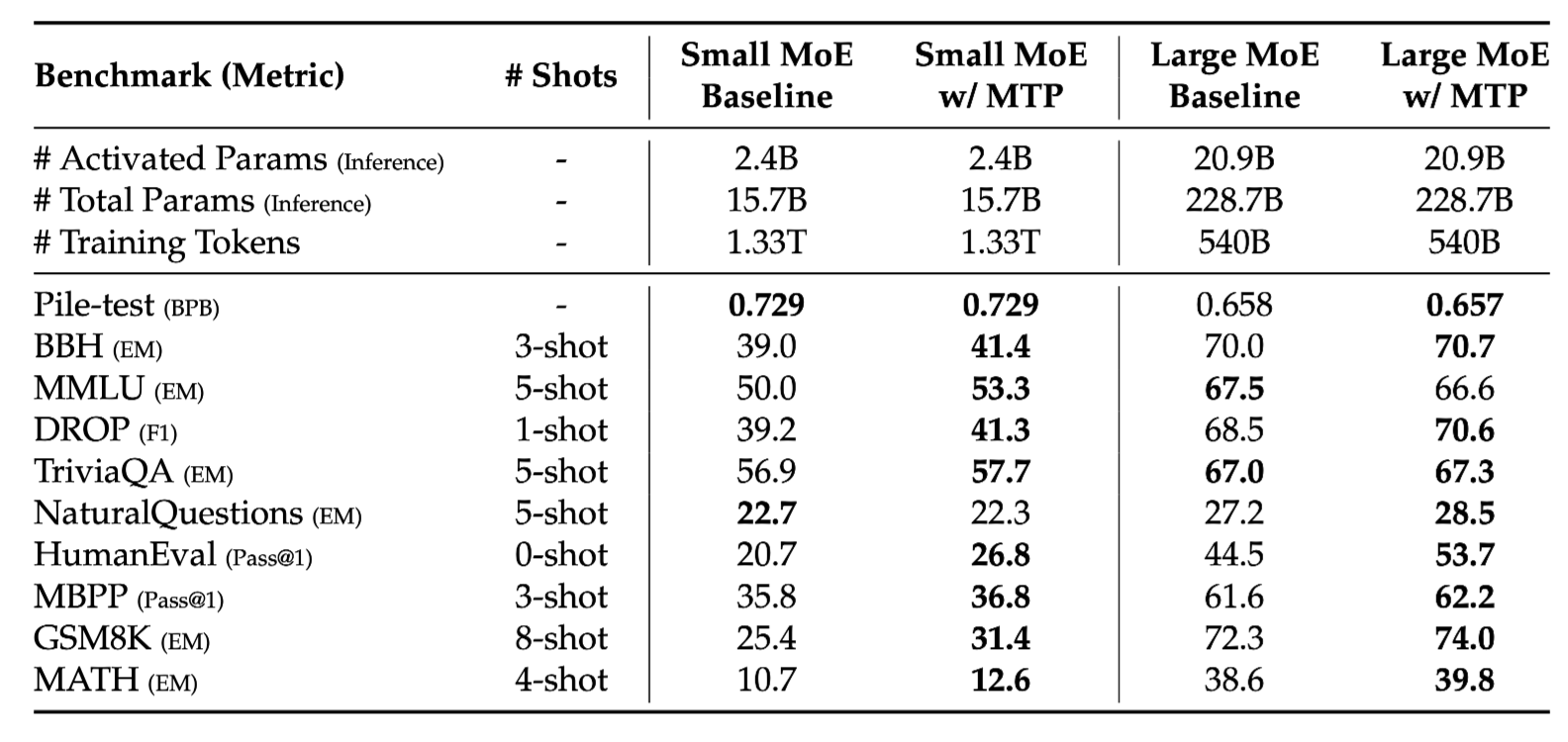
-
모델 크기와 관계없이 MTP 적용 시 성능 개선 효과 확인
-
Multi-Token Module이 기존 모델과 동일한 토큰을 예측하는 비율이 85%, 90% 달성 → speculative decoding 등에 사용될 수도
5-2. Auxiliary Loss Free
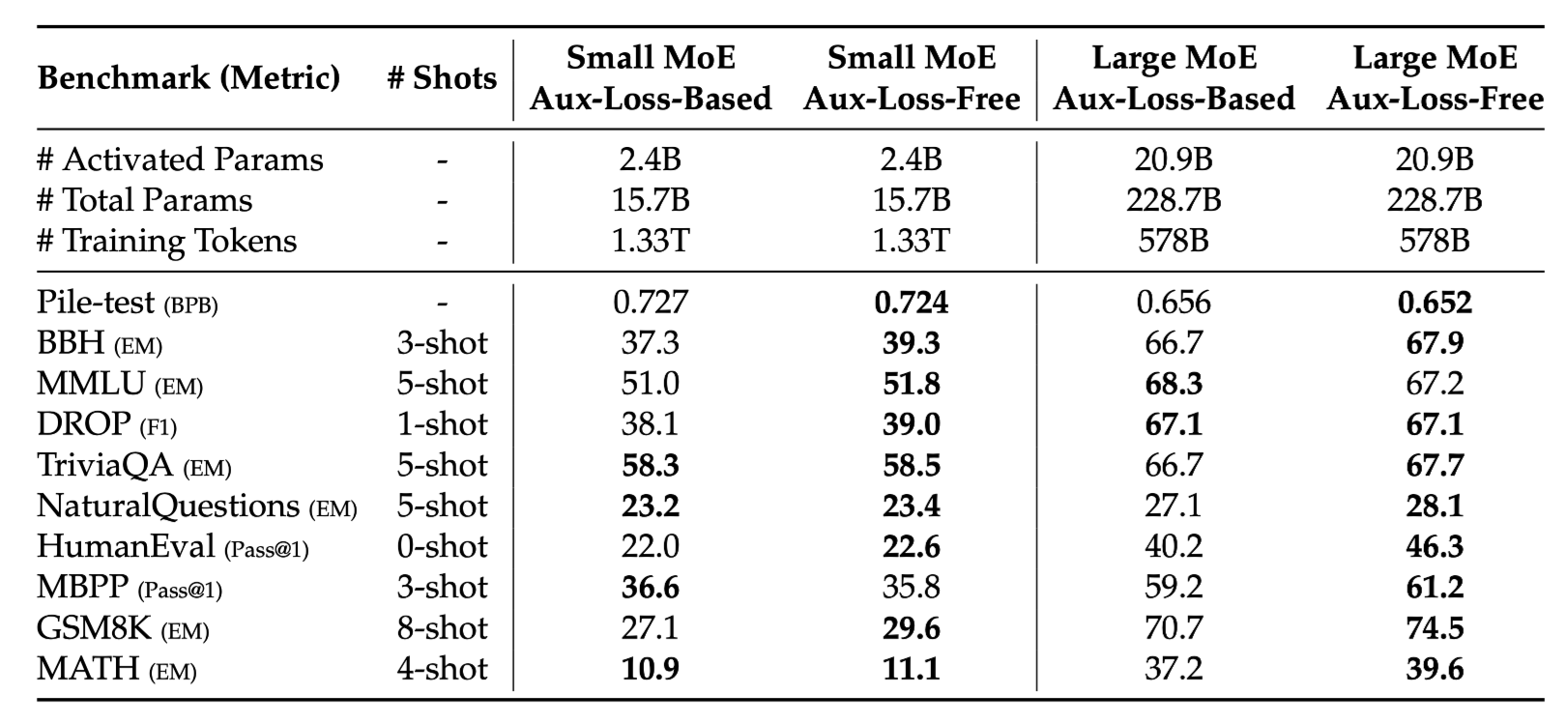
- Auxiliary Loss Free 구조가 훨씬 나은 성능을 꾸준히 보이고 있음
5-3. Sequence-wise vs Batch-wise load balance
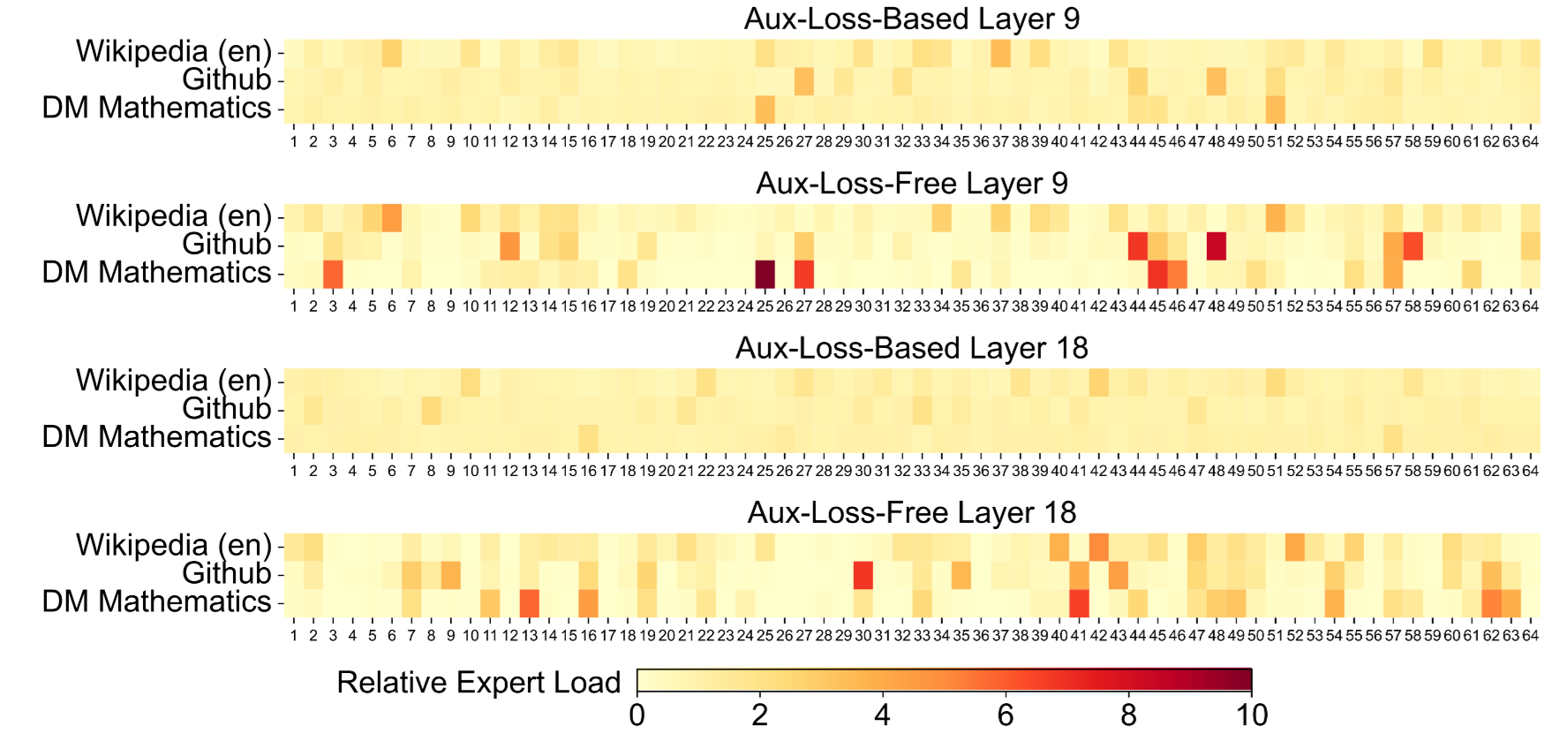
-
axuiliary loss 기반 학습 시 exper 활용이 필요함에도 그렇지 못한 경우 발생
- expert가 특정 도메인에 제대로 반응 X
-
auxiliary loss free 활용 시 특정 도메인마다 활성화되는 expert가 다른 모습 확인 가능
- expert가 expert로 활용되는 모습
Post training
5-4. Standard Benchmark
- main table
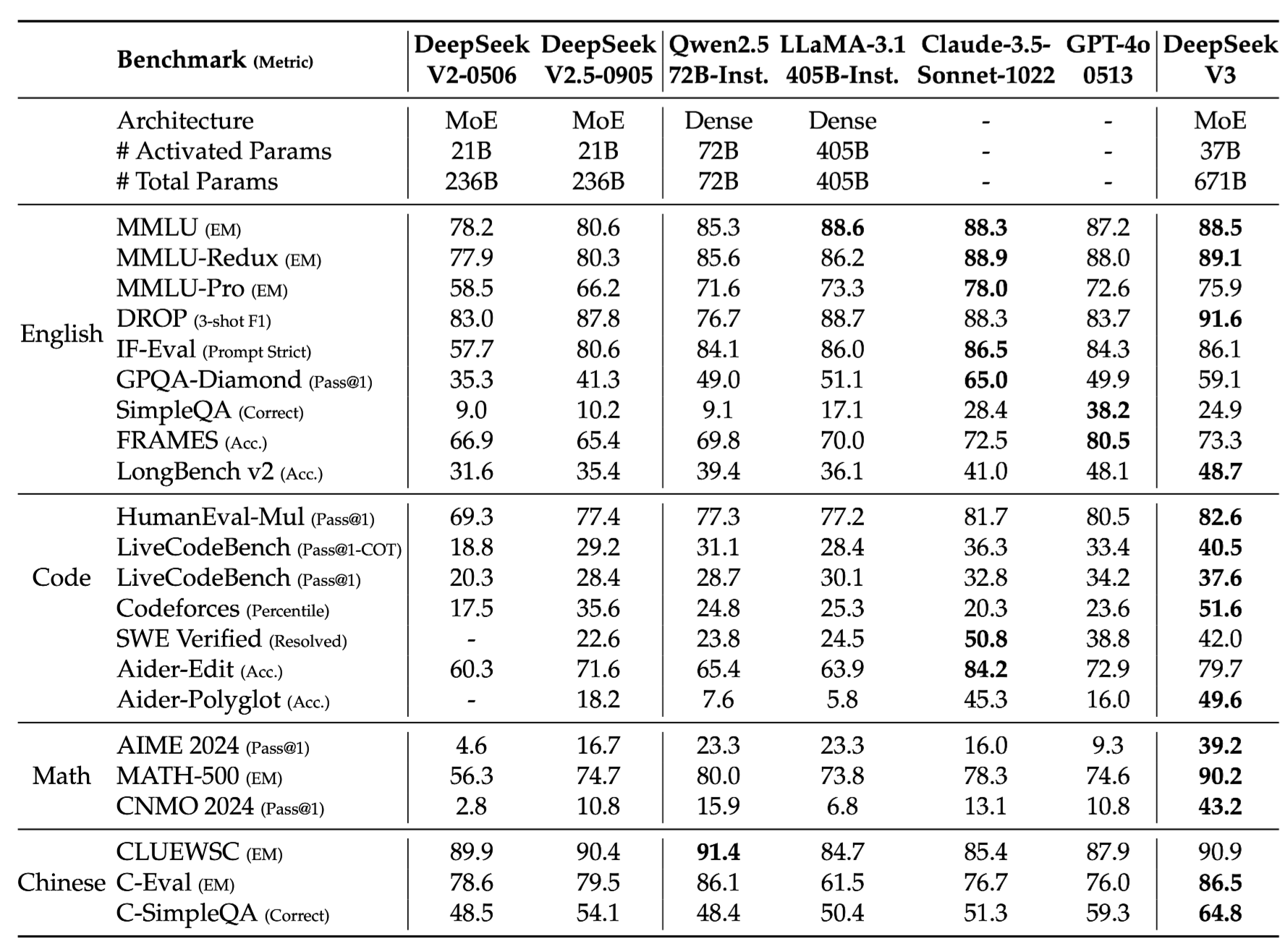
- cloased model 보다도 높은 성능 도출
5-5. Open-ended conversation
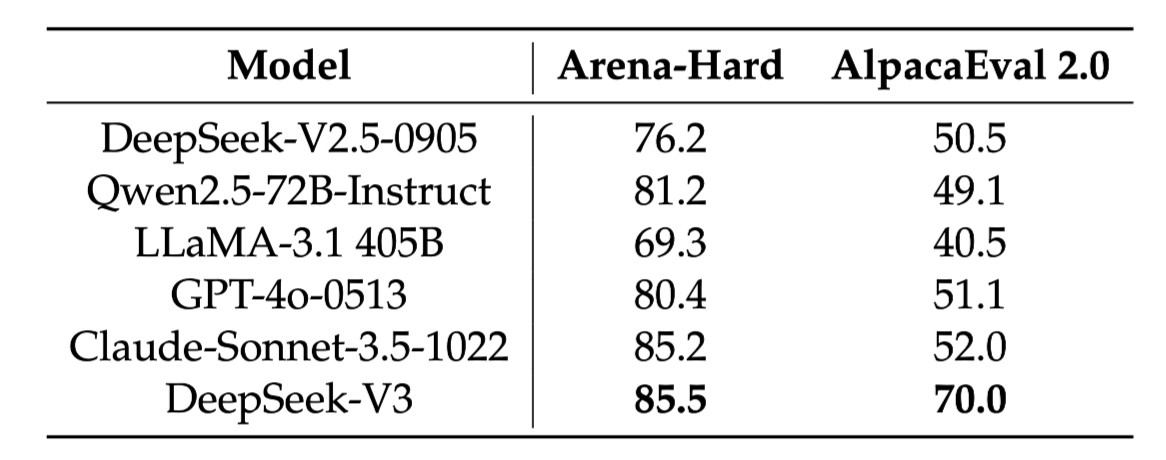
- 기존 open-source 및 closed model 대비 높은 성능 도출
4. Conclusion
-
진짜 깍고 깍아 만든 LLM 구조와 학습 파이프라인
-
MoE 구조의 효과성 입증
-
학습 토큰 효율은 달성할 수 있겠지만, compute efficient한 지 의문
-
추론/학습 시 사용되는 노드/gpu가 달라지게 되면서 비효율 발생
-
-
MTP 및 load balance free의 효과성 입증
- 기존에 제안된 방법론을 잘 변형하여 성능 개선에 도움
-
Post training 과정 고도화를 통해 synthetic data (distilled from strong model)을 잘 활용
-
사실상 R1 모델과 함께 개발된 논문
- R1과 V3 모델을 순차적으로 학습/데이터 구축하여 reasoning과 다양한 지식 성능 극대화
5. Other Techiniques
5-1. Dual Pipeline Scheduling

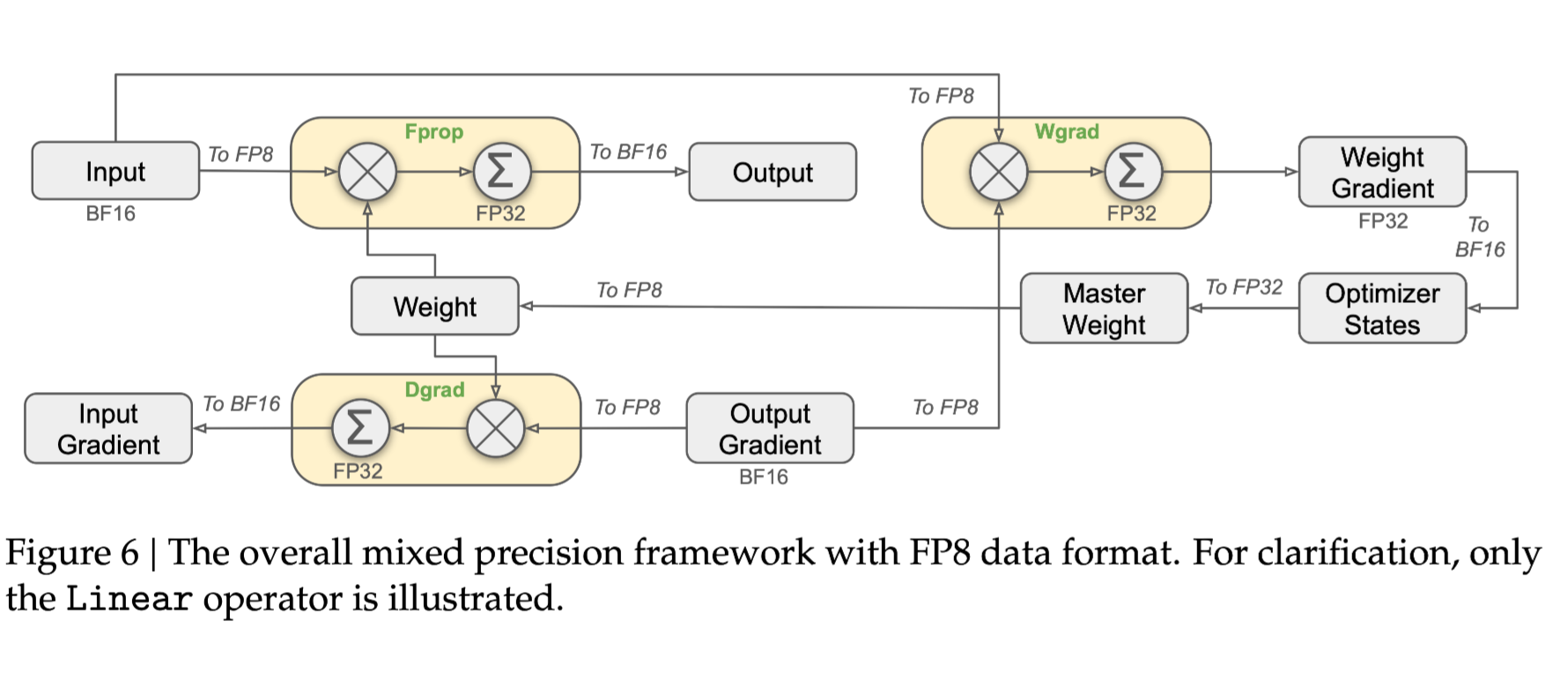
5-2. FP-8 Mixed Precision
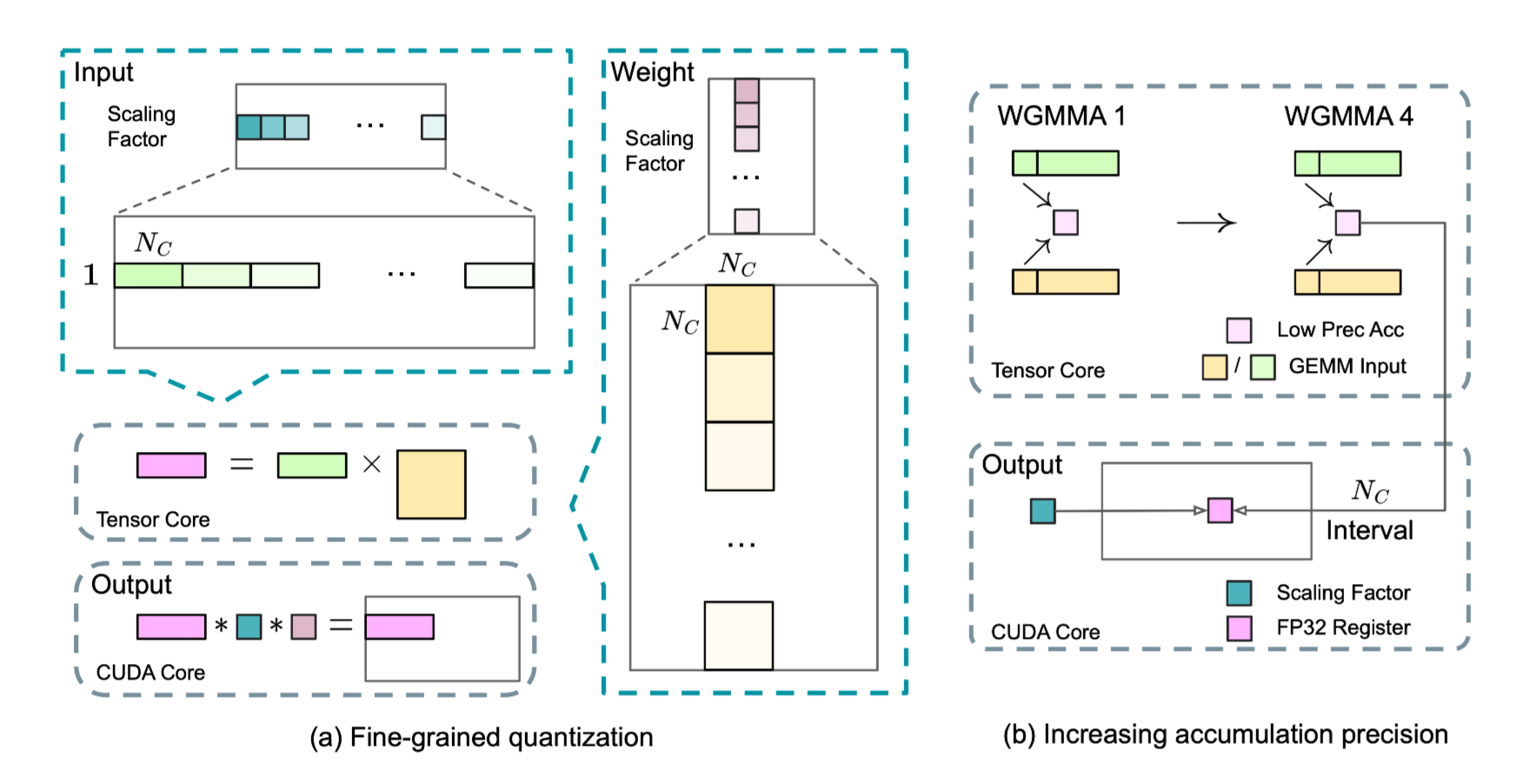
5-3. Prefilling for Deployment
-
자주 사용되는 expert들을 몰아서 하나의 노드/gpu에 넣자!
-
Communication cost 감소
5-4. Node-Limited Routing
-
각 토큰 별로 최대 M개의 노드에서만 연산 진행
-
affinity score의 합이 가장 큰 노드 선택 → 해당 노드 내 affinity score가 높은 expert 선택