DRA-GRPO: Exploring Diversity-Aware Reward Adjustment for R1-Zero-Like Training of Large Language Models
논문 정보
- Date: 2025-06-10
- Reviewer: 건우 김
Abstract
- 최근에 post-training을 위한 RL에서 GRPO와 같이 low-resource settings에서 가능성을 보여줌
→ GRPO는 solution-level의 scalar reward signals에 의존하는 경우가 많아, sampling된 문장들간의 semantic diversity를 제대로 반영하지 못함
→ 이는 서로 다른 reasoning path를 갖는 response들이 구분되지 않는 동일한 reward를 받는 (diversity-quality inconsistency) 문제가 있음
-
위 문제를 해결하기 위해 reward computation 과정에서 semantic diversity를 직접적으로 반영하는 방법인 Diversity-aware Reward Adjustment (DRA)를 제안함
-
DRA는 Submodular Mutual Information (SMI)를 활용하여
-
중복된 response의 reward는 감소시킴
-
diverse response의 reward는 증폭시킴
-
-
5개 Mathematical Reasoning benchmark에서 recent methods 대비 outperform 성능 보여줌
(단 7,000개 sample로만 fine-tuning을 하고, $55 training cost로 평균 acc 58.2% sota 달성)
1. Introduction
DeepSeek-R1-Zero (Guo et al., 2025)에서 기존 LLM에 SFT를 적용하는 것에서 벗어나, base LM에 바로 RL을 적용할 수 있는 R1-Zero training pipeline을 제안함.
→ Group Relative Policy Optimization (GRPO) 알고리즘 덕분에 가능한 방법
GRPO는 PPO와 다르게 critic model 없이 주어진 prompt에 대해 여러 sampling된 completions의 relative performance에 대한 advantage를 평가함.
하지만 최근에 공개된 GRPO 및 그 variants (e.g,. DR. GRPO)들은 일반적으로 정답 여부와 같은 solution-level의 scalar reward signals에만 의존하는 경향이 있어, 같은 정답이라도 diverse reasoning path의 차이를 반영하지 못함.
→ 이는 semantic하게 다른 completions들이 올바르거나 틀린 경우 모두 거의 동일한 rewards를 받아, 의미 있는 reasoning 차이를 반영하지 못하는 indistinguishable advantage estimates를 생성하는 문제가 있음
- **Example1 (Correct Reward)**
GRPO training process의 examples을 준비함. → 저자들의 key motivation of research
- LLM은 diverse answer를 생성할 수 있지만, 이런 answers들은 비슷한 수준의 reward score를 받음
→ 즉, solution-level judgements는 different reasoning paths를 구별하지 못함
아래는 question에 동일한 정답을 생성했지만 reasoning path가 완전히 다른 두가지 응답에 대한 케이스 (그럼에도 불구하고 reward는 비슷함)



- **Example2 (Incorrect Reward)**
이번 예시는 Question에 대해 두가지 응답이 모두 Incorrect인 반면, reasoning path는 서로 다름 → 그럼에도 불구하고 reward score는 둘 다 비슷하게 낮음





→ 또한, 이는 resource-constrained settings에서 더 문제가 될 수 있음
-
각 prompt당 sampling할 수 있는 completions의 개수가 적기 때문에, reward가 높은 outputs에 대한 exploitation만 reinforce하며, alternative하고 potentially valid한 reasoning paths에 대한 exploration을 유도하지 못함.
-
(비유) 선생님이 수학 문제를 모두 정확하게 푼 학생들에게 100점을 주는 케이스. 정답이 맞더라도, 학생의 이해도나 사고 방식을 드러낼 수 있는 문제를 푸는 다양한 방식은 평가되지 않고, 오답일 경우에도 그 과정에서 드러나는 다양한 추론 접근을 평가하지 않고 단순히 같은 감점을 받음.
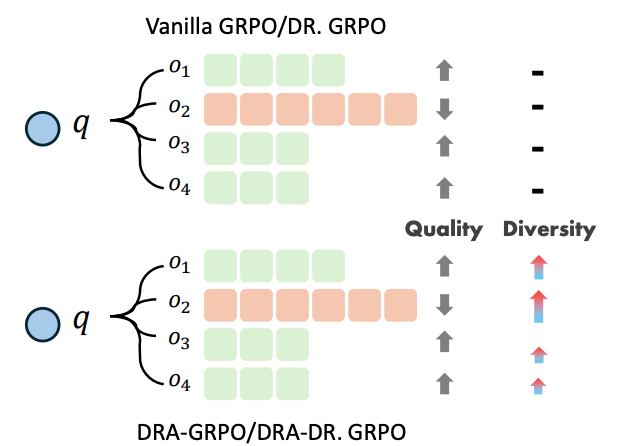
이 문제를 해결하기 위해서 저자들은 Diversity-aware Reward Adjustment (DRA)를 제안함.
이는 학습 과정에서 sampling된 completions 간의 semantic diversity를 직접적으로 모델링하는 방식으로 그룹 내 다른 completions과의 semantic similarity를 기반으로 각 output의 reward를 reweight함.
- diverse completions에는 더 높은 weight, 중복된 completion에는 더 낮은 weight 부여
2. Method
Preliminary
LM의 generation은 token-level Markov Decision Process로 볼 수 있음. 각 generation step t에서 state st는 input question q와 지금까지 생성된 partial output sequence o{<t}의 concatenation이기에, sates는 다음과 같음 st=[q;o{<t}].
| policy \pi*{\theta}(. | s_t)는 vocab set A에서 next token o_t를 선택하고, 이는 deterministic transition을 유도하여 next state s*{t+1}=[s_t;o_t]로 이동함. |
GRPO는 각 question q에 대해 여러 개의 responses C={o_1,…o_G}를 sampling하고, 각 response에 대해 reward를 계산함 R={R(q,o_1), … , R(q,o_G)}
계산된 reward R을 이용해 advantage A_{i,t}를 아래와 같이 계산함 (normalize)
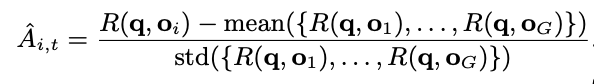
GRPO의 objective function J{GRPO}(\pi{\theta})를 optimize함
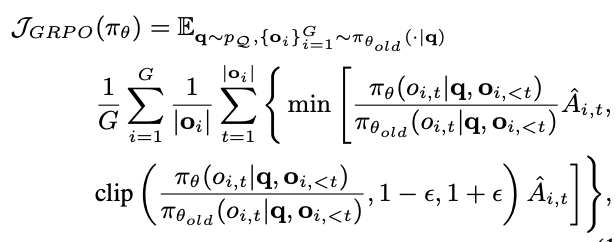
이후 연구인 DR.GRPO (Liu et al., 2025)에서는 token efficiency를 개선하기 위해 GRPO의 objective function에서 ‘response length’ term과 Advantage에서 std로 normalize해주는 term을 지움
- DR.GRPO (Zichen Liu, et al 2025)

GRPO의 두 가지 편향
-
Response-level length bias
-
각 response에 대해 평균을 구할때, 1/ o_i 가 곱해지는데, -
Correct response인 경우 advantage가 양수이면 shorter response에 대해서 greater gradient updates를 야기함 → 이 Policy는 correct answer에 대해 brevity favor있음
-
Incorrect response인 경우 advantage가 음수 longer response는 o_i 가 커지기 때문에 penalized를 더 받음 → 이 Policy는 Incorrect answer에 대해 길게 말하는 favor 있음
| ⇒ 쉽게 말하면 GRPO의 개별 advantage를 A_{i,t}/ | o_i | 로 보면 |
- positive advantage 에 대해서는 동일한 reward라도 |o_i|가 작을수록 update가 커지기에 짧은 response에 강한 signal을 주고
- negative advantage 에 대해서 역시 동일한 reward라도 |o_i|가 클수록 update가 작아지기 때문에 긴 response에 강한 signal을 줌 (=긴 오답은 under-penalized)
→ 즉, GRPO는 정답은 짧게, 오답은 길게 말하게끔 biased policy를 유도함
-
Question-level difficulty bias
-
advantage를 특정 question 내의 group average와 std로 normalization을 하기 때문에, std가 작으면 상대적으로 해당 question에 대한 training signal (weight update)가 과도하게 커짐
→ 일반적인 RL에서는 batch 단위로 normalization되어 bias를 상쇄시키지만, GRPO는 question 단위로 처리되어 그렇지 못함
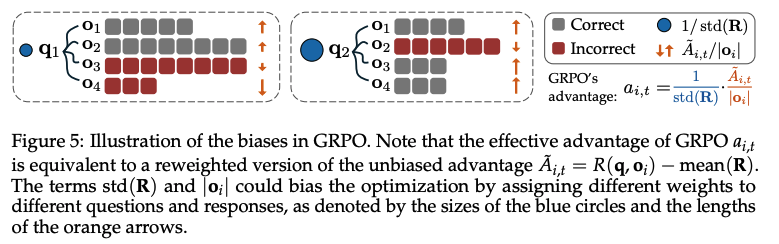
⇒ 위와 같은 문제는 LM의 response가 길어지는 이유가 reasoning capability 때문인지 아니면 bias 때문인지 구분하기가 어려워짐. 이에 따라 unbiased optimization method인 DR.GRPO 소개함
Question1: 위에서 분명 Correct response에 대해서는 짧아지는데 왜 response가 길어진다고 표현하는지?
⇒ (건피셜) Correct response 개수보다 Incorrect response의 수가 더 많기에, 대부분의 response는 RL training에서 오답이라 길게 생성하는 경향이 생김
Question2: GRPO를 보면 학습이 진행될수록 reasoning accuracy가 올라가는데, 그러면 bias에 따라 response length가 짧아져야 하는거 아닌가?
⇒ (건피셜) complex tasks에서는 아무리 오래 학습시켜도 높은 acc에 도달하는 모델이 없어서 그렇지 않을까..?
DR.GRPO는 GRPO의 optimization bias를 없애기 위해 아래 두가지 terms을 없앰
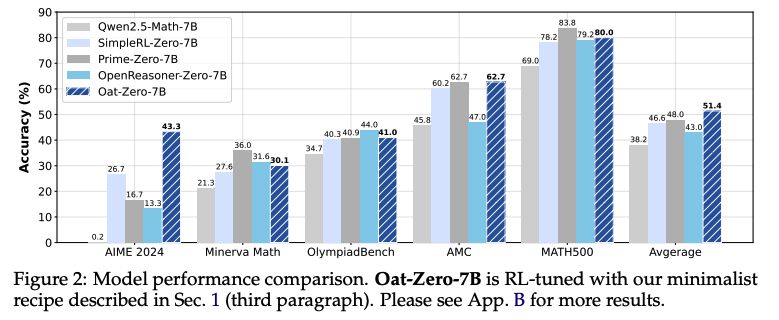
R1-Zero와 비슷한 minimal recipe로 학습한 Oat-Zero-7B 성능
-
minimal recipe
-
base model: Qwen2.5-Math-7B
-
training dataset: MATH dataset의 level3~5
-
GPU: 8xA100 27hrs
-
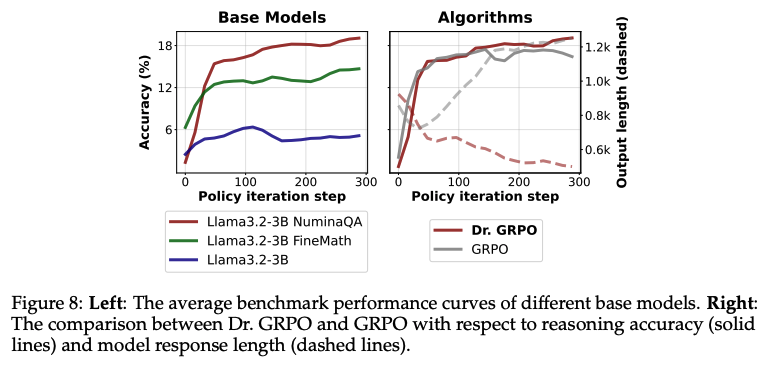
아래 (우측) 그림을 보면
-
(solid lines) DR.GRPO는 reasoning accuracy가 지속적으로 오르는 반면에, GRPO는 그렇지 않음 (불안정함)
-
(dashed lines) DR.GRPO는 response length가 짧고 안정적인 반면에, GRPO는 response length가 계속 길어짐
Diversity-Quality Inconsistency
GRPO와 DR.GRPO의 reward signal은 solution-level correctness만 사용하기 때문에, 각 completion에 대해 sparse scalar judgement를 계산함.
→ 이러한 scalar reward는 동일하거나 유사한 결과를 산출하는 diverse reasoning-path를 고려하지 않기 때문에, Diversity-Quality Inconsistency가 발생함.
위에 Example 말고, 보다 실증적인 방식으로 다음 statement (”reward alone fails to reflect the underlying variability in reasoning strategies”) 를 검증하기 위해 embedding distances로 측정된 completions의 structural dissimilarity를 계산함.
-
Spearman’s rank correlation을 사용하여 sampled completions 사이에서 reward difference와 semantic distance를 측정함 →semantic distance가 커질수록 reward 차이도 커지는가?
- 3000개 prompt 뽑아서 p-value 측정
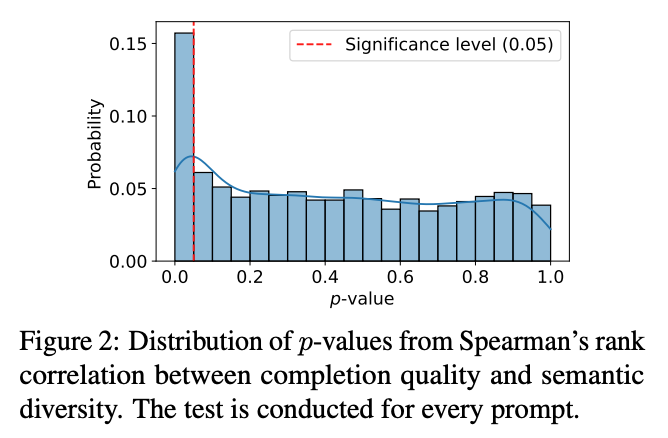
- Figure2는 Spearman’s rank correlation의 p-values의 분포를 보여주는데, 대부분의 p-value가 significance level인 0.05 보다 큰 값을 보여주며, 실제로 80% 이상의 prompt에 대해 statistically significant correlation이 없음을 확인할 수 있음
→ 즉, reward가 semantic diversity와 상관이 없다는 것을 실험적으로 보여줌
\tilde{a} \text{이렇게}
Diversity-aware Reward Adjustment
Diversity-Quality Inconsistency 문제를 해결하기 위해, 각 sample의 relative diversity/redundancy에 따라 reward를 reweight하는 방법을 제안함.
→ diverse completions은 더 높은 weight, 중복된 response는 낮은 weight
먼저 기존의 reward R(q,o_i)를 diversity-aware adjusted reward \tilde{R}(q,o_i) (틸다 표시 어떻게 하나요…) 으로 대체함
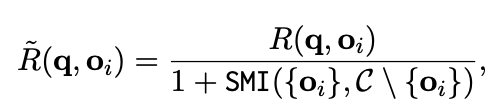
-
SMI({o_i},C \ {o_i})는 completion o_i와 나머지 group C \ o_i 간의 Submodular Mutual Information을 나타냄
-
Submodular functions은 diminishing returns 특성을 갖으며, diversity와 redundancy를 모델링할 수 있음
- *diminishing returns**: 어떤 집합에 요소를 하나씩 더 추가할 때, 이미 비슷한 요소가 많을 수록 그 요소가 추가로 가져오는 가치(정보 기여도)는 줄어드는 성질*
-
SMI는 두 집합 간의 shared information을 정량화하며 (Iyer et al., 2021a,b)에서는 아래와 같이 정의함
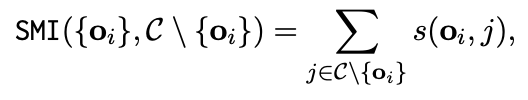
-
s(o_i,j)=s(j,o_i)라고 가정하며, SMI({o_i},C \ {o_i})는 o_i와 나머지 elements간의 total semmetric simialrity를 계산함
-
즉, o_i가 나머지 completions과 유사할수록 SMI가 커져 reward 값이 낮게 reweight되고, o_i가 다를수록 SMI가 작아져 reward 값이 크게 reweight 됨.
-
각 completion의 embedding은 small LM으로 얻고, s()는 cosine similarity를 사용함
-
SMI를 쉽게 말하면 “특정 completion 하나가 group 내 다른 completion과 얼마나 겹치는가”를 수치로 나타내는 값
-
중복이 많으면 (high redundancy) → SMI가 큼 → reward가 작아짐
-
중복이 적으면 (high diversity) → SMI가 작음 → reward가 커짐
-
-
Submodular 함수는 수학 개념으로 “새로운 element가 기존에 비슷한게 많을수록 기여도가 줄어드는 성질”을 갖고 있음
ex) 유사한 completions이 9개가 있는 상황에서, 10번째 비슷한 completion은 information을 별로 추가하지 않음. 반면, 완전히 다른 completion이 등장하면 information 기여도가 커짐
→ 이렇게 새로운 reward를 구하는 연산은 Pytorch에서 효과적으로 처리될 수 있음
- \Sigma{L_{ij}} term이 simiarlity matrix L의 ith row의 합
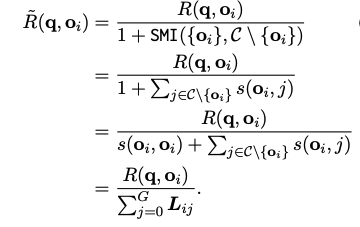
- Pytorch Code for DAR

3. Experiment
3.1 Experimental Setup
**Training Dataset: **
- s1 dataset + DeepScaleR dataset with mixed problem difficulties
**Evaluation Dataset: **
- five mathematical reasoning benchmarks (AIME24, MATH-500, AMC23, Minerva, OlympiadBench)
Baselines:
-
general purpose large model: Llama-3.1-70B-Instruct, o1-preivew
-
Mathematics-focused 7B models: Qwen-2.5-Math-7B-Instruct, rStar-Math-7B, Eurus-2-7B-PRIME, Qwen2.5-7B-SimpleRL
-
Mathematics-focused 1.5B models: DeepScaleR-1.5B-Preview, Still-3-1.5B-Preview, Open-RS
Implementations:
-
본 연구는 DRA의 proof-of-concept만 검증하는 것이 목적이기에 DeepSeek-R1-Distill-Qwen-1.5B를 base model로 두어 학습시킴
-
4 x A100 (40GB) GPUs
3.2 Empirical Analysis
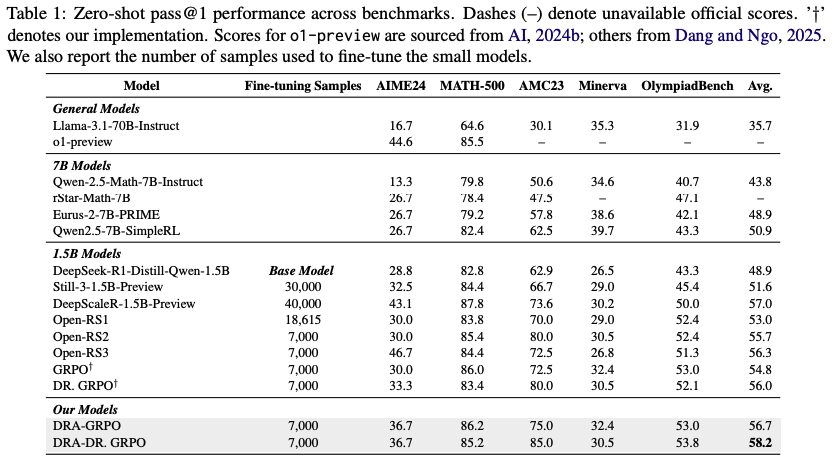
Main Results
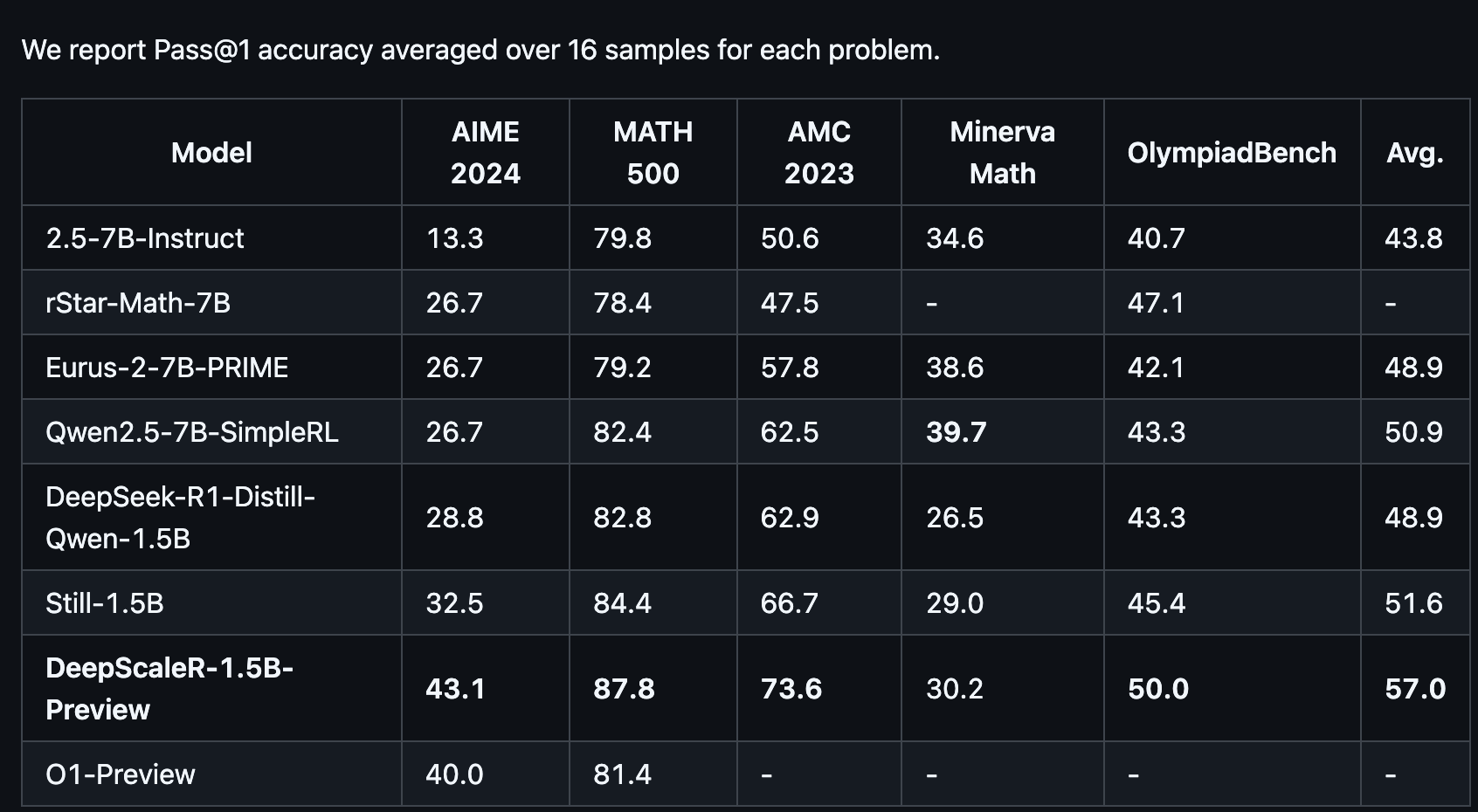
-
DRA-DR.GRPO는 avg acc가 58.2%로 가장 높게 나옴 (DRA-GRPO역시 비슷한 수준으로 높게 나옴)
- AMC23에서 특히 높은 성능을 보여줌 (85.0%)
-
DRA-GRPO와 DRA-DR.GRPO는 fine-tuning samples을 7,000개 밖에 사용하지 않았음에도 불구하고 40,000개 사용한 DeepScaleR-1.5B-preview보다 높은 성능 보여줌
→ Low-resource settings에서도 효과적임
- DeepScaleR-1.5B-preview
나름 GOAT급의 성능 보여주는 잘나가는 모델
Untitled
Ablation Study
- Base model인 DeepSeek-R1-Distill-Qwen-1.5B와 비교하여 DRA-GRPO, DRA-DR.GRPO는 각각 7.8%, 9.3% 성능 향상되고 단순 RL (GRPO, DR.GRPO) 대비 1.9%, 2.2% 향상
→ 이게 왜 Ablation study라 말하는거지ㅋㅋ
Efficiency
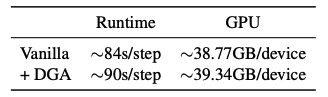
DRA는 completions을 encoding 해야하기에 over-head가 존재하지만, 별로 크지 않음.
→ 저자들이 실험에 사용한 GPU스펙인 (A100-40GB)에서는 어차피 DRA 없이도 mini-batch를 늘리는 것이 불가능해서 DRA 적용하는 것이 별 문제가 되지 않다고 하는데…. → 🐶 🔊 라고 생각합니다
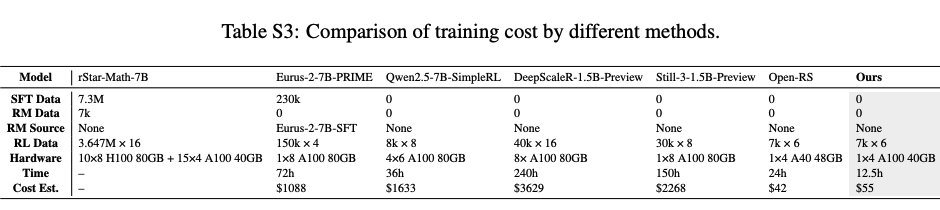
Training Cost
500 steps 학습시켜 12.5hr 소요됨 ⇒ $55 비용
→ 다른 방법대비 효율적임
3.3 Discussion
Exploration-exploitation Balance
DRA는 Exploration-exploitation balance를 policy gradient 안에 직접 통합하여 적용함
- Base reward는 high score를 받는 completion을 reinforce함
→ Exploitation 유도
- Diversity weighting은 semantically novel completion에 learning signal을 amplify
→ Exploration 유도
이러한 탐색은 low-resource settings (prompt당 sampling할 수 있는 응답 수가 제한 적인 경우)에서 중요함
→ DRA는 mode collapse를 방지하고 더 넓은 reasoning strategies를 유도함
Ad-hoc vs Post-hoc Diversity
generated completions간의 diversity를 모델링하는 방법은 크게 Ad-hoc, Post-hoc 방식이 있음
-
Ad-hoc
-
generation 단계에서 다양성을 유도함 (temperature 조절, decoding 설정 변경)
-
이렇게 하면 각 completion이 독립적으로 sampling되어 → 응답 간 correlation을 명시적으로 모델링할 수 없음 (completion이 서로 얼마나 다른지 명시적으로 알 수 없음)
-
Post-hoc (본 연구에서 채택한 방법)
-
diversity를 reward signal에 바로 통합
-
Semantic redundancy를 평가하여 policy가 효율적으로 learning을 조정할 수 있게 해줌
4. Conclusion
- GRPO 형식의 RL에서 completions 간의 semantic diversity를 모델링할 수 있는 DRA 알고리즘 제안함
→ 기존 scalar reward의 문제인 exploration-exploitation imbalance issue를 효과적으로 완화함
-
두가지 한계점이 있음
-
small-scale models (1.5B) / small group sizes (e.g 6 completions per prompt)
-
diversity를 측정할 때 사용된 sentence embeddings은 외부 model에 의존하는 구조
-
-
이런 쪽도 재밌다!ㅋㅋ