Fine-tuning Vision-Language-Action Models: Optimizing Speed and Success
논문 정보
- Date: 2025-04-22
- Reviewer: 전민진
기존 openVLA의 한계(1. low frequency 2. bi-manual 불가 3. action discrete representation)을 해소하는 FT 방법론 소개
Motivation
-
기존 openVLA는 generalization에는 성공적(language following ability, semantic generalization)이었지만, 명백한 한계가 존재
-
auto-regressive generation ⇒ low frequency
-
FT해도 bi-manual 성능이 구림
-
-
최근에 생성 속도를 향상시키는 연구가 여러가지 소개되었으나, bi-manual에 취약함 ⇒ 속도도 빠르면서 만족할만한 성능을 보여주는 방법은 없음
-
본 논문에서는 OpenVLA를 베이스로 사용하여 최적의 파인튜닝 레시피 Optimized Fine-Tuning(OFT) recipe를 탐구
- different action decoding schemes, action representations, learning objectives에 대해 분석
-
여러 디자인 초이스를 바탕으로 OpenVLA-OFT를 제안, LIBERO simulation benchmark에서 OpenVLA의 성능을 효과적으로 높이면서도 26x generation throughput를 달성
- real-world evaluation에서도 OpenVLA를 bimanual ALOHA robot setting에 맞춰서 학습, 다른 VLA보다 훨씬 높은 성능을 보임
Introduction
-
최근 VLA 모델은 low-level robotic control을 위해 대량의 robot dataset에 pretrained VLM을 학습해 구축, 다양한 로봇과 태스크에서 높은 성능과 semantic generalization, language following ability를 보임
-
fine-tuning은 새로운 로봇과 태스크에 대해 VLA의 높은 성능을 위해 필수적이지만, 아직 adapation을 위해 어떤 디자인이 가장 효과적인지에 대한 탐구는 부족
- action head로 어떤 것을 사용할 것인지, next token prediction loss가 최적인지 등등
-
이전 OpenVLA 논문에서 LoRA를 활용한 FT adaptation strategy를 소개하였으나, 몇가지 한계가 존재
-
autoregressive action generation은 high-frequency control(25-50+Hz)를 하기엔 너무 느림(3-5Hz)
- hz는 1초당 action 횟수
-
LoRA와 full FT 모두 bi-manual manipulation task에서 불만족스러운 성능을 냄
-
-
최근에 더 좋은 action tokenization schemes를 통해서 efficiency를 높이는(속도를 2배에서 13배 정도 높임) 연구들이 제안되었으나, action chunk사이에 상당한 latency가 있어(최근 가장 빠른 방법 기준 750ms) 아직 high-frequency bimanual robot에 적용하기엔 한계가 존재
⇒ 속도도 빠르고 만족할 성능을 보여주는 방법론은 아직 부재
-
본 논문에선 이러한 인사이트들을 바탕으로 OFT recipe의 초안, OpenVLA-OFT를 제안
-
parallel decoding과 action chunking을 통합
-
continuous action representation
-
L1 regression objective
-
-
LIBERO simulation benchmark와 real bimanul ALOHA robot으로 실험
-
LIBERO에서는 8 action chunk사용, 26x빠른 속도로 평균 97.1%의 성능 달성
-
ALOHA task에서는 enchanced language grouding을 위해 FiLM을 레시피에 추가, 해당 모델을 OFT+라 명시
-
옷접기, 타겟 음식을 바탕으로 조작하는 태스크 등에서 높은 성능을 보임
-
25-timestep action chunck를 바탕으로 OpenVLA보다 43배 높은 throughput를 보임
-
-
Related Work
-
이전엔 language와 vision foundation모델을 사용해서 robotic capabilities를 높이는 연구들이 진행
-
robotic policy learning을 가속화하기 위해 pretrained visual representation을 사용
- robotic task에서 object localization이나 high-level planning과 reasoning 등
-
더 최근에는 VLM이 바로 low-level robotic control action을 예측하도록 하는 VLA 모델을 만드는 연구들이 제안됨
-
효과적인 OOD test condition과 unseen semantic concept에 대한 generalization을 보임
-
보통 모델 개발에 초점을 두고 연구
-
-
⇒ 본 논문에서는 이러한 모델을 FT할 때의 개발 레시피에 초점을 줌
-
VLA 모델 개발시 FT의 역할이 중요함에도 불구하고, 효과적인 레시피 탐구는 부족했음
-
이전에는 full FT와 FT with LoRA 정도
-
하지만 이조차도 single-arm에 한정적, low control frequencies로 bimanual robot에 확장은 불가능
-
-
최근의 연구에서는 VLA 효율성을 위해 새로운 action tokenization 방법이 고안됨
-
vector quantization 사용
-
discrete cosine transform-based compression to represent action chunk with fewer tokens than simple per-dimension binning(RT-2와 OpenVLA에서 사용되던거)
-
이러한 방법론은 기존 autoregressive VLA에 대해 2배에서 13배 정도의 속도 향상을 보여주었으나, iterative generation 특성 때매 한정적
-
본 논문의 parallel decoding은 action chunk와 함께 사용할 경우 26배에서 43배의 throughput과 훨씬 낮은 latency(0.07ms for single-arm task with one input image & 0.321ms for bimanual tasks with three input images)를 보여줌
-
-
다른 연구 라인에서는 high-frequency, bimanual manipulation을 위한 효과적인 VLA FT를 위해서 diffusion 이나 flow matching을 사용
-
diffusion 기반 VLA는 multi-step action chunks가 동시에 가능해 throughput은 높지만 학습 속도는 느림
- 각자 모델 디자인이 상이해서 어떤 요소가 성능 향상에 영향을 끼치는지는 확인하기 어려움
-
본 논문에서는 통제된 세팅에서 실험, 어떤 요소가 성능 향상에 영향을 끼치는지도 분석
-
Preliminaries
Original OpenVLA formulation
-
7B manipulation policy, Prismatic VLM을 OXE의 1M episode에 FT해서 만든 모델
-
autoregressive prediction을 활용, 각 timestep마다 7 discrete robot action token을 생성
-
3개는 position control, 3개는 orientation control, 1개는 gripper control
-
cross-entropy loss로 Next-token prediction방식으로 학습 (언어모델 하던거 그대로 가져옴)
-
Action chunking
-
이전 연구는 action chunking(중간 replanning없이 future action sequence를 예측, 실행)이 여러 manipulation task에서 policy 성공률을 높인다는 것을 보임
-
그러나, OpenVLA의 autoregressive generation scheme에서는 action chunking이 어려움
- single timestep action를 생성하는데 0.33초가 걸림(A100기준)
-
chunk size를 K, action dimensionality를 D라고 하면, OpenVLA는 KD번 forward를 해야함
Proposed Method
Studying key VLA Fine-Tuning Design Decisions
-
기존 OpenVLA의 한계를 다루기 위해서 다음 3가지 디자인에 대해 조사
-
Action generation strategy
- 기존엔 action dimension이 7이라고 하면, 하나의 액션을 생성하기 위해 7번 forward ⇒ low frequency
-
Action representation
-
기존엔 액션을 토큰으로 생성, 액션의 범위를 256개로 binning & normalization, 각각을 토큰으로 취급
-
즉, 특정 액션 토큰을 생성하면 그걸 다시 정해진 평균과 표준편차를 바탕으로 continous value로 mapping ⇒ precision이 떨어질 수밖에 없음
-
-
Learning objective
- next-token prediction으로 파인튜닝
-
⇒ 본 연구에서는 OpenVLA를 base model로 실험, OpenVLA를 500개의 demonstration에 대해 LoRA FT로 adaptation

Implementing Alternative Design Components
-
Parallel decoding with action chunking
-
여러 action sequence를 한번의 forward로 생성하기 위해서, 기존의 auto-regressive방식이 아닌 다른 방식을 사용
-
모델이 empty action embedding을 input token으로 받도록 수정, caual attention mask를 bi-directional attention으로 변경, decoder가 모든 action을 동시에 prediction하도록 함
-
⇒ 이 방식으로 D(action dimension) sequential pass를 한번의 single pass로 줄일 수 있음
-
Parallel decoding에서 action chunking으로 확장하는거는 쉬움
-
empty action embedding을 decoder의 input에 추가, 이는 future action의 chunk로 mapping됨
-
chunk size K에 대해서, 모델은 이제 KD actions을 한번의 forward로 예측할 수 있고, 최소한의 latency로 thoughput K-fold를 증가
-
thoughput K-fold: K의 rollout을 병렬로 생성했을 때의 처리량
- k번에 걸쳐 action sequence를 생성, 평가해 가장 좋은걸 고르는 방법론(?)
-
-
parallel decoding은 autoregressive approach에 비해선 이론적으로 덜 expressive하지만 여러 태스크에 실험 결과, 성능 하락을 보이진 않음
-
-
Continuous action space
-
OpenVLA는 원래 각 action dimension이 [-1,+1]로 normalized되고, 256 bin으로 uniform하게 discretized된 discrete action token을 사용
- 이 방법론은 기존의 VLM을 수정하지 않는다는 점에서는 편리하지만, fine-grained action detail을 떨어뜨림
-
본 논문에서는 크게 2가지 방식으로 continuous action space를 구현
- 1안) L1 regression 구현
-
: LLM의 끝단에 있던 output embedding layer를 빼고, 새로 4-layer MLP action head를 추가, action token을 예측하는 것이 아니라 정확한 action 값 자체를 생성하도록 함
- 2안) conditional denoising diffusion modeling
: 모델이 forward diffusion에서 action sample에 추가된 noise를 예측하는 방식으로 학습, inference시 noisy action sample을 점차 denoising하면서 real action을 예측
- 이 방식은 더 expressive action modeling을 가능하게 하지만, inference시 여러번의 forward pass가 필요(50 diffusion steps in our implementation)
- Parallel decoding을 사용해서 latency가 좀 더 커짐
-
Additional model inputs and outputs
-
orignal OpenVLA에서는 single camera view만 처리가 가능했으나, 몇몇 로봇 세팅에서는 여러 viewpoint와 추가적인 robot state information이 포함됨
-
본 논문에서는 flexible input processing pipeline을 구현
-
camera image는 OpenVLA와 같은 dual vision encoder를 통해 view마다 256개의 patch embedding으로 추출, language embedding space으로 projection
-
low-dimensional robot state input에 대해서는 separate projection network를 사용해서 같은 embedding space로 mapping, 하나의 input embedding으로 변환해 사용
-
-
모든 input embedding(visual features, robot state, language token)을 concat해서 decoder에 들어감
-
⇒ 이러한 unified latent representation은 모델이 action을 생성할 때, 모든 이용가능한 정보에 접근할 수 있게 함
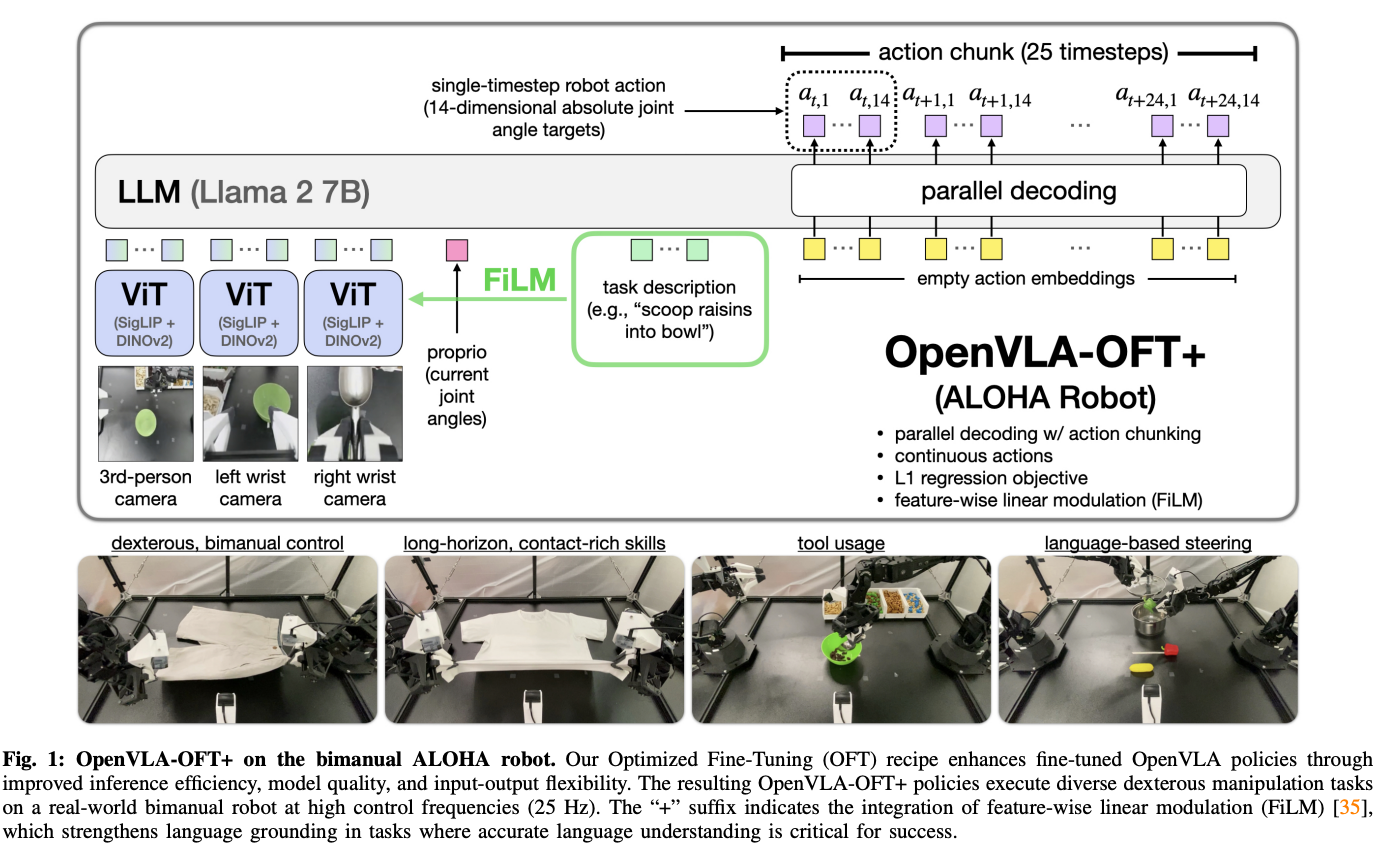
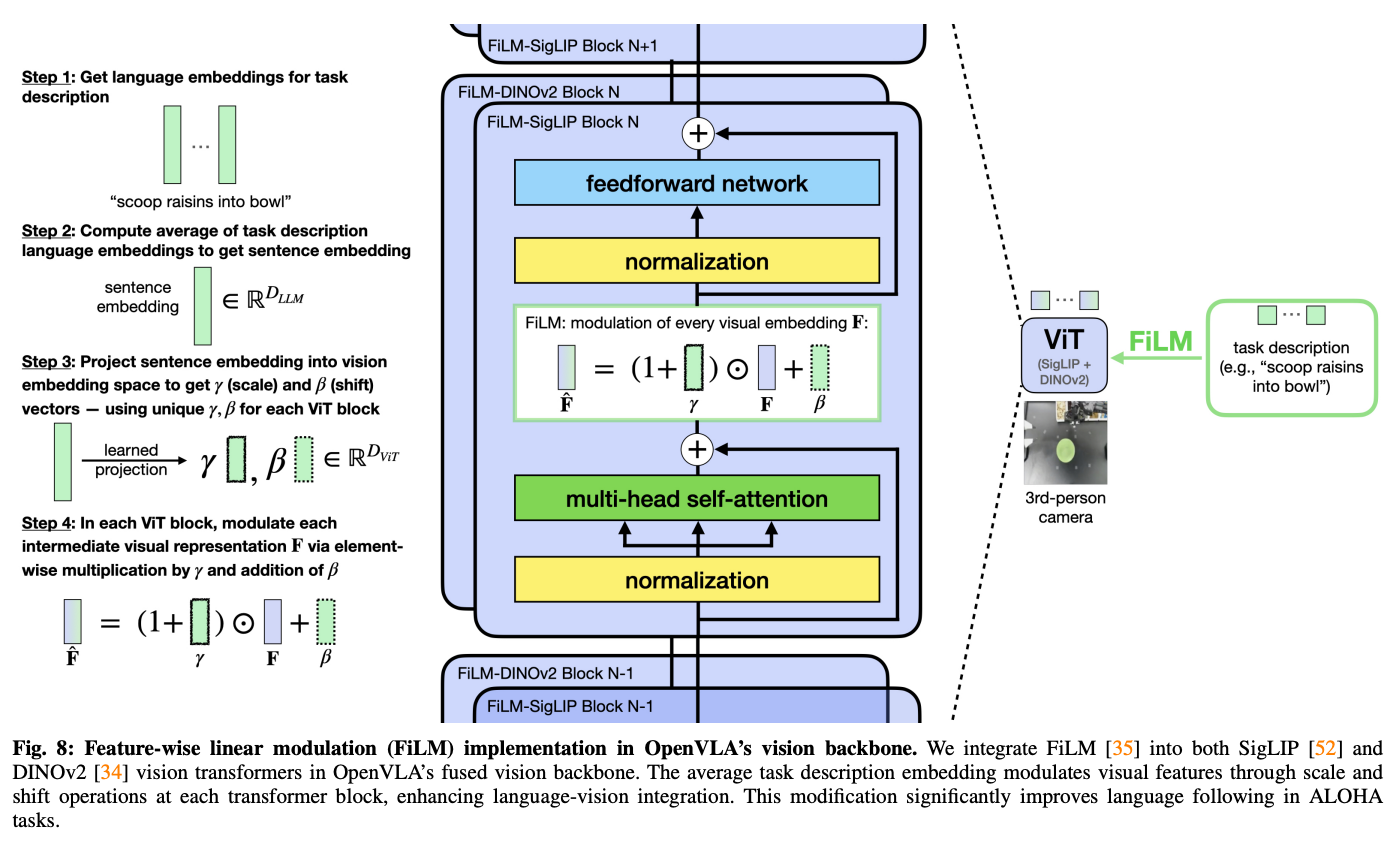
Augmenting OpenVLA-OFT with FiLM for Enchanced Language Grounding
- bimanual에서는 input image가 3개(3rd person view, wrist-mounted cameras)
⇒ visual input간의 spurious correlation때문에 language following에 어려움을 겪음
-
그래서 bi-manual에서는 language following ability향상을 위해서 ViT에 FiLM을 추가
- 각 image patch마다 다른 scaling, shift factor를 적용했더니 langauge following이 안좋아서 같은 scaling, shift factor를 사용한다고 함
⇒ 모든 patch에 같은 \gamma,\beta가 적용되지만 각 차원별로는 다른 scaling과 shift가 적용
- scaling, shift factor의 크기는 D_ViT
- D_ViT는 visual patch embedding에서 hidden dimension의 크기
-
FiLM은 각 ViT block에서 self-attention layer와 FFN사이에 적용, 각 블록마다 다른 proejctor사용
-
FiLM은 ALOHA experiment에서만 사용!

Experiment
Research Question
RQ1. How does each design decision affect the fine-tuned policy’s success rate on downstream tasks?
RQ2. How does each design decisions affect model inference efficiency (action generation throughput and latency)?
RQ3. How do alternative fine-tuning formulations affect flexibility in model input-output specifications?
LIBERO
-
Experiment setup
-
Franka Emika Panda arm기반의 simulator, camera images, robot state, task annotation, and delta end-effector pose actions이 포함되어 있음
-
본 논문에서는 4가지 task를 사용 - LIBERO-Spatial, Object, Goal, Long
- policy generalization을 평가하기 위해 각각 500개의 expert demonstration을 제공
-

-
OpenVLA에서는 unsucessful demonstration을 필터링하고 각 task마다 따로 LoRA로 FT
-
본 논문에서는 non-diffulsion method는 50-150K gradient step학습, diffusion method는 100-250K gradient step을 학습
- batch size 64-128, A100/H100 8대 사용
-
특별한 언급이 없으면, policy는 하나의 third-person image와 language instruction을 input으로 받음
-
action chunk size K=8로 설정, replanning전에 full chunk 실행
-
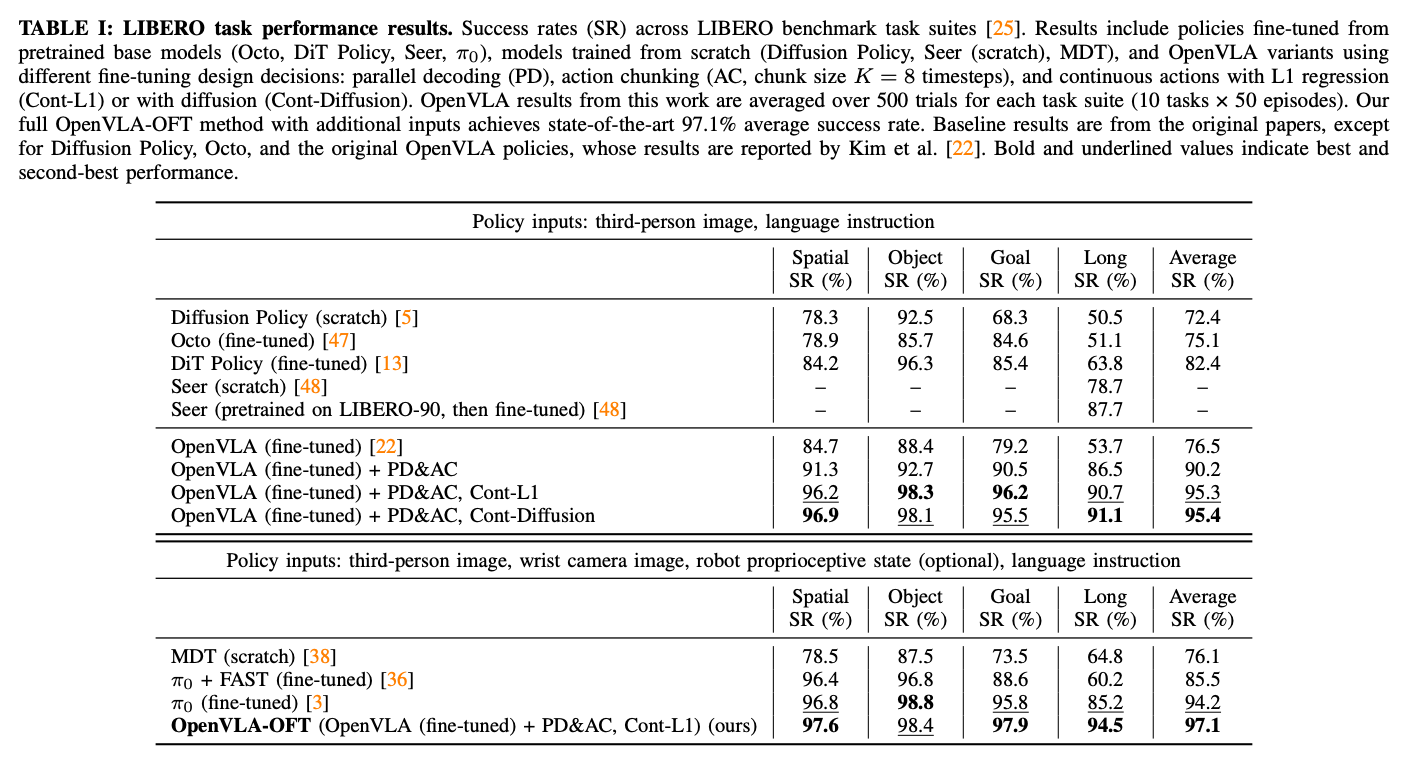
Task performance comparisons
-
우선 LIBERO benchmakr에 영향을 끼치는 design decision에 대해 평가
-
실험 결과 PD(parallel decoding)과 AC(action chunking)를 동시에 써야 high-frequency control이 가능했음.
-
실험 결과, PD&AC는 쓰는 것이 더 좋았고, Cont-L1과 diffusion을 비교하면, 성능이 유사하나 latency측면에서 Cont-L1이 더 좋음(아래 나옴)
- 특히 PD&AC의 효과는 LIBERO-Long에서 가장 뛰어남
-
-
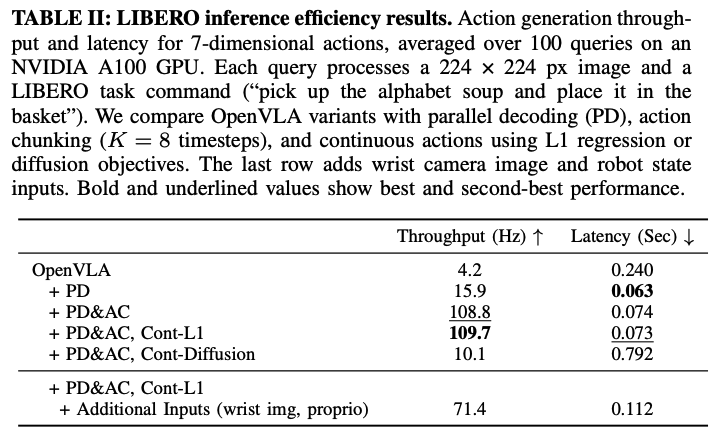
Inference Efficiency comparisons
-
하나의 robot action 혹은 action chunk를 생성하는데 걸리는 평균 시간을 측정
-
Cont-L1의 경우 그냥 PD&AC와 거의 차이가 안남(MLP action head는 최소한의 computational cost가 추가됨)
-
diffusion의 경우 denoising process가 있어 시간이 좀 더 걸림에도 불구하고 기존 OpenVLA보다는 2-3배 느림
-
-
Model input-output flexibility
-
위의 표(table2)를 보면 additional input을 추가해도 기존 모델보단 훨씬 빠름
-
table 1을 보면 additional input을 넣었을 때, 모든 모델들이 전반적으로 성능이 향상되었으나, 각 모델의 복잡한 학습 구조(\pi_0 은 MDT(multi-modal diffusion transformer)와 flow-matching 사용)를 고려해봤을 때, openvla-oft가 굉장히 간단한 방법으로 높은 성능을 보임
-
-
Optimized Fine-tuning recipe
- 위의 실험 결과를 봤을 때, 최적의 design choice는 다음과 같음
-
parallel decoding with action chunking
-
continuous action representation
-
L1 regression objective
⇒ 이제 이 구조의 모델을 OpenVLA-OFT라 명명
-
Additional experiments
-
FT formulation을 바꾸면서, base VLA pretrain과 finetuning사이에 큰 distribution shift가 일어났을 수밖에 없음
- 정말 base VLA의 지식이 도움이 됐을까?
-

- 크진 않지만 도움이 됨!
Real-World ALOHA Robot
- : 이전까지는 simulation에서의 성능을 봤다면, 이번 파트는 실제 로봇에 적용해봤을 때의 성능
-
OpenVLA의 경우 pretraining때 bimanual data를 본 적이 없음
-
여기서는 OpenVLA-OFT에 FiLM을 추가한 OpenVLA-OFT+로 성능 평가
-
Setup
-
ALOHA platform은 2대의 ViperX 300 S arms, 3대의 카메라 viewpoint(하나는 top-down, 두대는 wrist-mounted), robot state input(14 dimensional joint angles)
-
25Hz로 작동, 각 action은 target absolute joint angle를 표현
-
⇒ 이 세팅은 OpenVLA pretraining때와 매우 다름
-
크게 4개의 task를 선택
-
fold shorts : 흰 반바지 접기, 20개의 demon으로 학습, 평가는 10번
-
fold shirt : 흰 티 접기, 30개의 demon으로 학습, 평가는 10번
-
scoop X into bowl : 왼손으로 table의 중앙으로 그릇을 움직이고, 오른손으로 특정 재료를 퍼서 담음, 45개 demon(재료당 15개)으로 학습, 12번(재료당 4번) 평가
-
put X into pot : 왼손으로 냄비 뚜껑 열어서 오른손으로 특정 아이템을 넣음, 300 demon으로 학습(아이템당 100번), 24번 평가(12번는 학습 아이템, 12번은 ood)
-
-
OpenVLA를 각 task에 따로따로 50-150K gradient step정도 FT
- action chunk size K=25, inference시에 바로 풀 action chunk실행
-
Method in Comparison
-
ALOHA는 OpenVLA가 adaptation하기가 어려움, 그래서 더 최근 VLA-RDT-1B, \pi_0과 비교
- 둘은 bimanual manipulation data로 pretrain됨
-
각 모델은 각 저자의 레시피로 FT하고 평가함
-
computational efficiency를 평가하기 위해 기존의 imitation learning baseline, ACT와 Diffusion policy를 scratch로 각 task에 학습해 사용
-
각 baseline method의 language following을 위해서, language-conditioned implementation을 사용
- ACT는 EfficientNet-B0를 수정, Diffusion Policy는 DROID dataset 구현을 사용(DistillBERT language embedding에 기반해 action denoising진행)
-
-
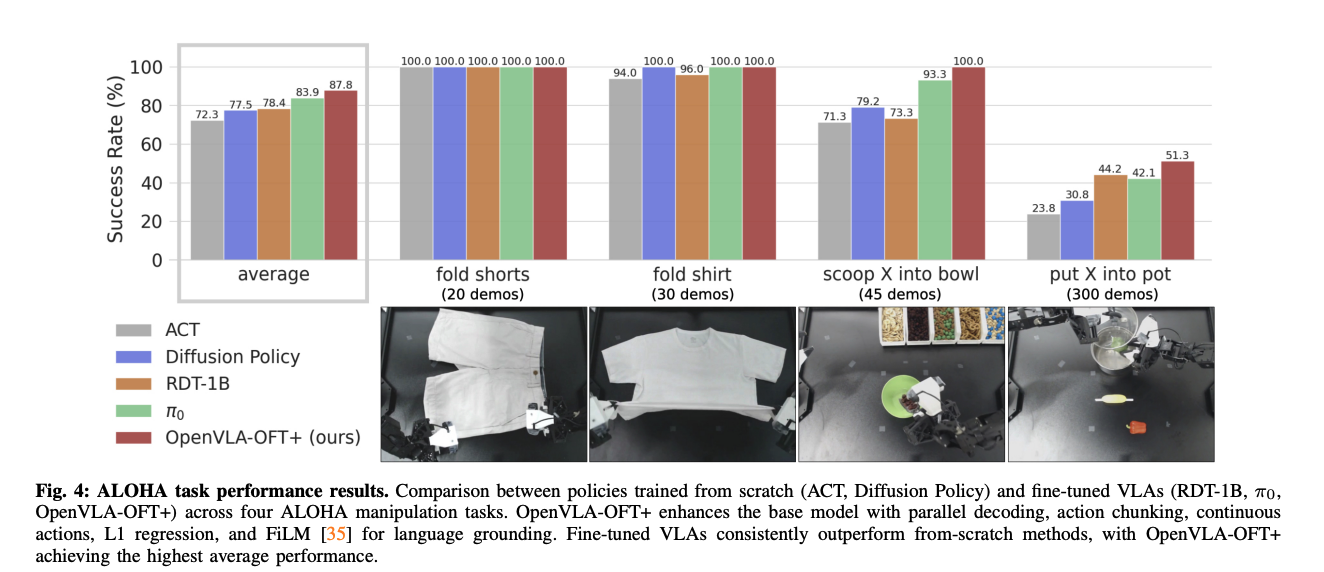
ALOHA Task Performance Results
-
실험 결과, pretrain때 본 데이터와 전혀 다름에도 매우 높은 성능을 보여줌
-
scratch부터 학습한 ACT, Diffusion policy의 경우 language understanding이 필요한 Scoop X, put X task에서 저조한 성능을 보임
-
finetuend-VLA는 비교적 잘하나, visual feedback에 대해 과하게 의지하는 경향을 보임
-
-


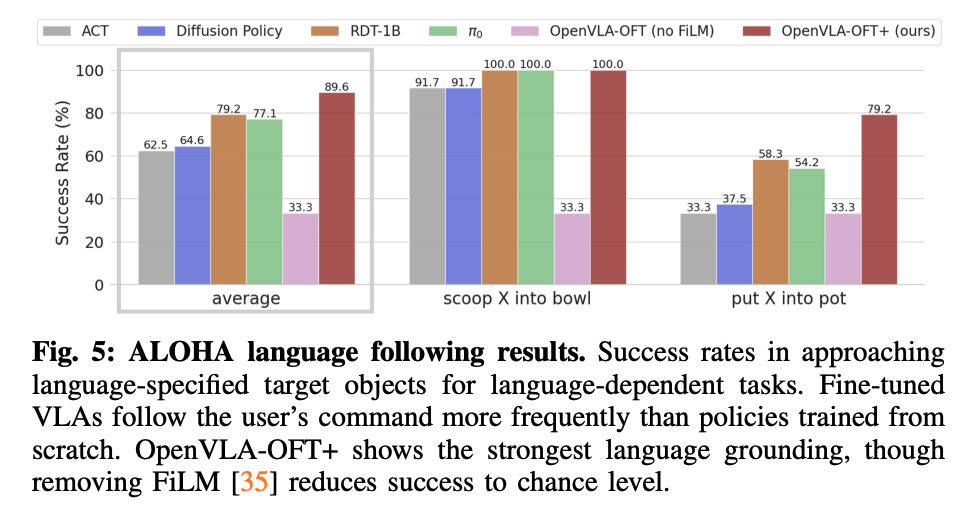
- FiLM이 language following을 위해 매우 중요함을 보여줌
-
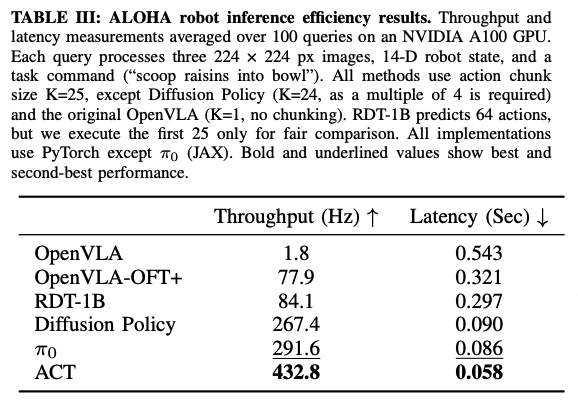
ALOHA Inference Efficiency Comparison
- 다른 finetuned VLA과 비교해서 훨씬 높은 efficiency를 보임
Limitations
-
Handling multimodal demonstrations
- L1 loss로는 robot data특유의 multi-modal를 포착할 수 없음
-
Pretraining versus fine-tuning
- 본 논문은 FT에만 집중, pretraining의 효과에 대한 분석은 부족
-
Inconsistent language grounding
-
LIBERO에서는 문제가 없었으나, ALOHA에서는 FiLM없이는 성능이 하락
- 일관성이 떨어짐
-