Impact of Fine-Tuning Methods on Memorization in Large Language Models
논문 정보
- Date: 2025-08-05
- Reviewer: hyowon Cho
많은 연구들이 LLM이 사전학습 단계에서 학습 데이터를 외우는 이슈에 대해서 보고하고 있는 한편, finetuning에 대해서 비슷한 연구는 놀라울 정도로 적다.
하지만, finetuning도 당연히 모델 대부의 업데이트와 때때로는 구조적인 변화까지도 이루어지기 때문에, finetuning의 memorization level에 대한 연구도 필요하다.
그렇다면, 존재하는 다양한 finetuning 방법에 따른 memorization of fineuning data의 영향력은 어떻게 되는가?
해당 연구는 이를 시험하기 위해 우선 finetuning 방법을 크게 두 가지로 구분한다:
-
Parameter-based finetuning: 모델 파라 바꿈
-
Prompt-based fine-tuning: 모델 파라 고정, soft token/prefix embedding…
결과적으로 두 카테고리를 고루 포함한 5가지 방법을 시험했고,
평가는 다양한 MIAs(membership inference attacks )로 했고,
데이터는 Wikitext, WebNLG, Xsum 세 가지로 했다 (좀 적긴하네요)
간단하고 빠르게 다음으로 넘어갑시다
Fine-Tuning Methods
-
Parameter-based fine-tuning
-
Model Head Tuning (FT head): fine-tunes only the final output layer
-
Low-Rank Adaptation (LoRA) (Hu et al., 2021)
-
-
Prompt-based fine-tuning: task-specific prompts only
-
Prefix Tuning
- 각 attention layer의 key/value에 학습 가능한 prefix 벡터 추가.
-
Prompt Tuning
- 모델 입력 임베딩 앞에 학습 가능한 연속형 프롬프트 임베딩 추가.
-
P-tuning
- 별도의 신경망으로 학습한 연속형 프롬프트를 입력에 삽입.
-
Memorization and MIAs
-
사용된 MIA 기법과 점수 계산 방식:
- LOSS (Yeom et al., 2018)
- Membership Score = 모델의 손실
\text{Score} = L(x, M_t)
(손실이 낮을수록 멤버일 가능성 ↑)
-
Reference-based (Ref) (Mireshghallah et al., 2022a)
- 기준 모델 MrM_rMr와 비교하여 손실 차이 계산
\text{Score} = L(x, M_t) - L(x, M_r)
-
Zlib Entropy (Zlib) (Carlini et al., 2021)
- 손실을 zlib 엔트로피로 나눈 비율
\text{Score} = \frac{L(x, M_t)}{\text{zlib}(x)}
-
Min-K% (Shi et al., 2024)
- 토큰 확률이 낮은 하위 k% 토큰들의 평균 로그 likelihood
| \text{Score} = \frac{1}{E} \sum*{x_i \in \text{Min-}K\%(x)} \log p(x_i | x*{<i}) |
Experimental Setup
-
데이터
-
Wikitext-2-raw-1
-
WebNLG
- triple로 이루어짐 (Subject-Predicate-Object)
-
Xsum: 요약
- finetuning에 5000개만 사용
-
-
평가
- training and test sets에서 샘플링
-
모델
-
LLaMA 2-7B (Touvron et al., 2023)
-
GPT2-series (Radford et al., 2019)
-
LLaMA 3-1B
-
→ 2025의 논문이라고 믿기지 않는군여!
-
Evaluation Metrics
-
PERF: validation PPL as the primary metric
-
MIA: AUC-ROC
-
-
Implementation Details
-
15 epoch
-
모든 세팅은 논문에 나온거 그대로 따라함
-
4090이랑 H100 한대 사용
-
Results and Observations
Memorization across Tuning Methods
Does the choice of finetuning strategy affect how much a model memorizes its training data for fine tuning?
Observation ♯1: (당연)
Parameter-based fine-tuning demonstrates a higher tendency to explicitly memorize training data.
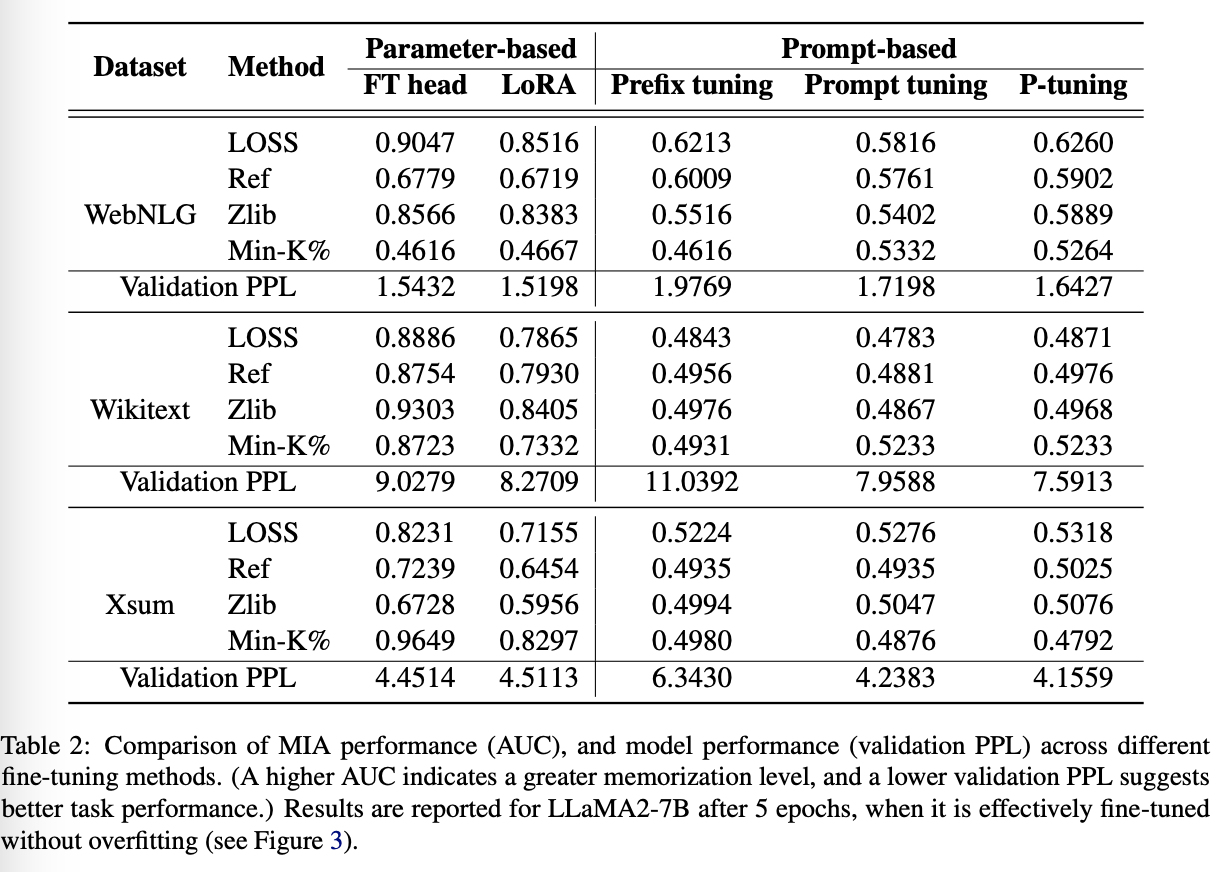
모든 방법론은 validation PPL기준으로 성능 좋았음.
하지만, prompt-based methods 는 parameter-based 보다 외우는 성능 떨어짐 (당연)
Observation ♯2:
Parameter-based fine-tuning exhibits increasing memorization over training epochs, while prompt-based fine-tuning maintains consistently low memorization throughout training.
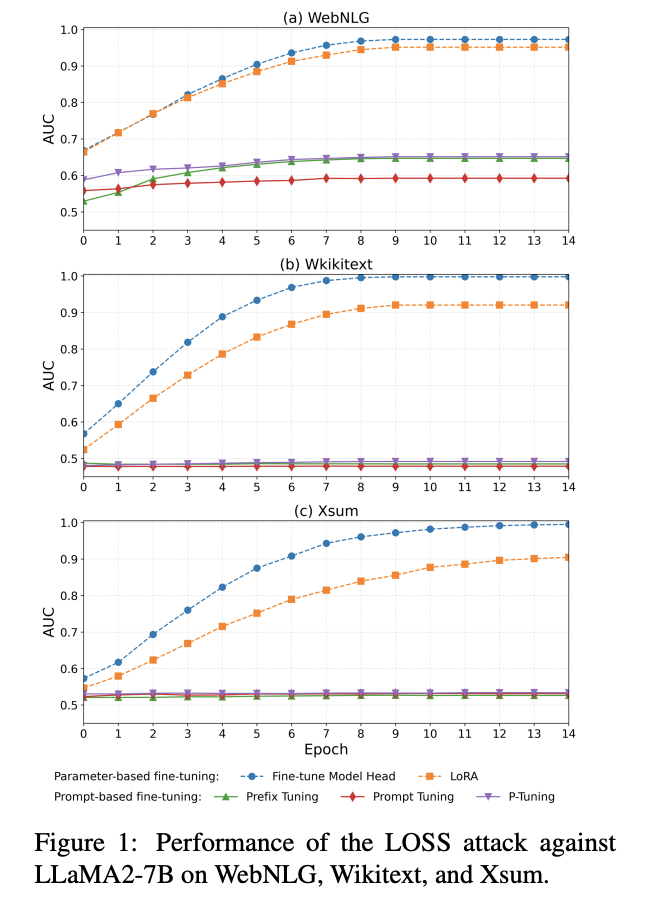
Why Prompt-Based Fine-Tuning Exhibits Low Memorization
prompt-based fine-tuning introduces a bias into the model’s attention mechanism indirectly via the soft prompt or prefix, rather than altering the attention mechanism itself.
- Prefix Tuning 수식 (Petrov et al., 2024)
t^{pt}i = A^{pt}{i0} WV S_1 + (1 - A^{pt}{i0})\; t_i
-
soft-prefix가 어텐션 가중치 A^{pt}를 ‘어디를 볼지’만 재조정, 본래 토큰 간 상대 분포는 그대로.
-
즉 새로운 attention 패턴을 학습하기보다는 기존 능력을 재활용.
-
결과적으로 표현 공간의 이동(shift) < 적음 → 학습, 비학습 샘플 분포 차이가 작아 MIA가 어렵다.
- Petrov et al. (2024) prove that the presence of a prefix does not alter the relative distribution of the input but only shifts the attention to different content.
이 가설을 확인하기 위해:
distributions of non-membership and membership examples on the LLaMA2-7B를 세 세팅에서 비교함:
-
pre-trained model,
-
fine-tuned with LoRA
-
fine-tuned with prefix tuning
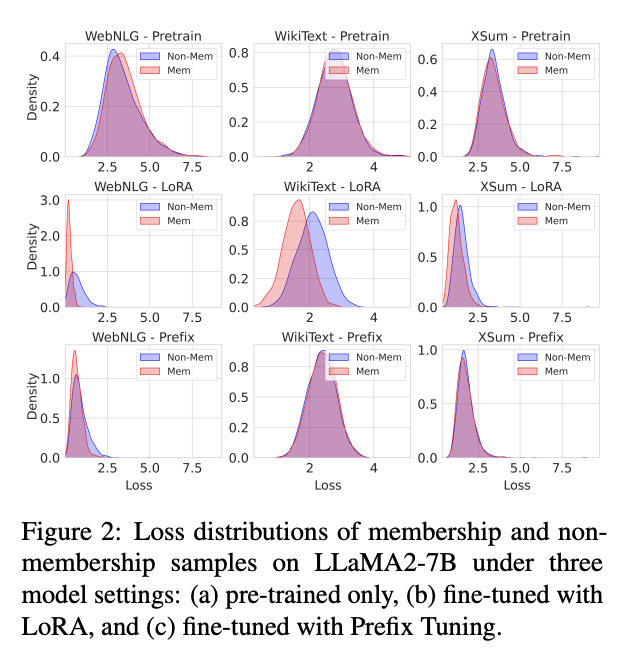
LoRA는 membership and non-membership samples 사이 분포 차이가 큰데, prefix tuning은 미미하다는 것을 알 수 있음
Performance in Different Tuning Paradigms
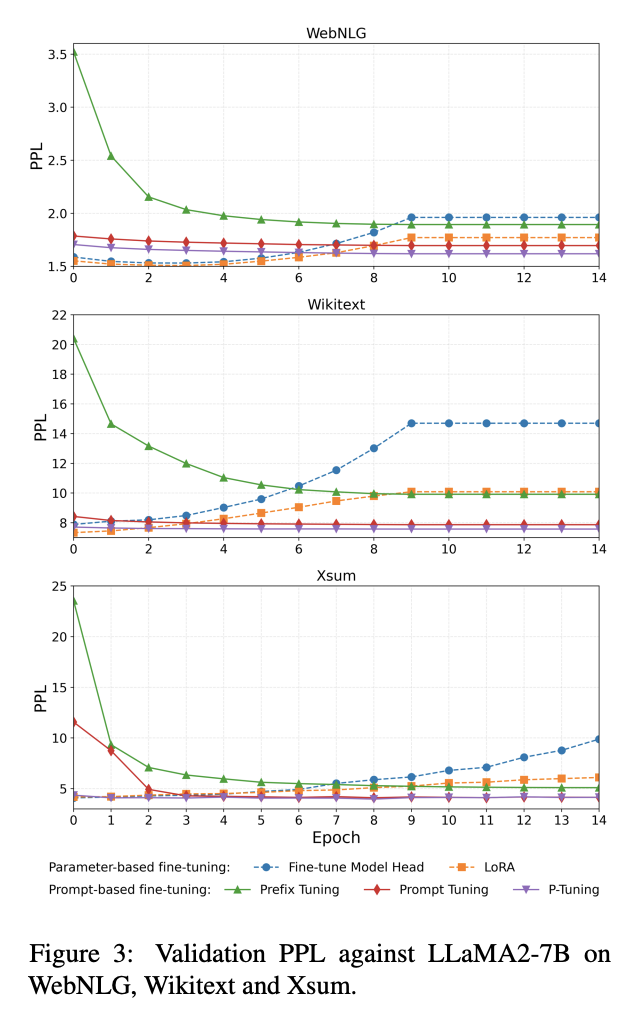
두 방법론이 최종적으로는 비슷한 PPL을 가졌음에도 불구하고, Learning trajactories는 꽤나 달랐음
parameterbased fine-tuning:
-
decreases over the first few epochs
-
later increases due to overfitting, before eventually converging
prompt-based fine-tuning:
-
slightly decreasing validation PPL throughout training,
-
converging without the overfitting-induced rise
이는 아까도 이야기 했듯이, 후자가 internal sample distribution of the model을 바꾸는 것이 아니라 단순히 다운스트림 태스크에 쪼끔 더 나은 bias를 추가하는 정도임을 다시한번 보인다
Discussion
Regarding Model Scale
모델 사이즈가 memorization에 중요한 영향력을 줄 것임.
→ To what extent does model size influence memorization under different fine-tuning strategies?
Observation ♯3
Model size significantly enhances memorization in parameter-based fine-tuning methods, while prompt-based methods show minimal sensitivity and maintain consistently low memorization.
four variants of the GPT-2 architecture:
-
GPT-2 (124M),
-
GPT-2 Medium (345M),
-
GPT2 Large (762M),
-
GPT-2 XL (1.5B).
LLaMA2-7B vs LLaMA3-1B
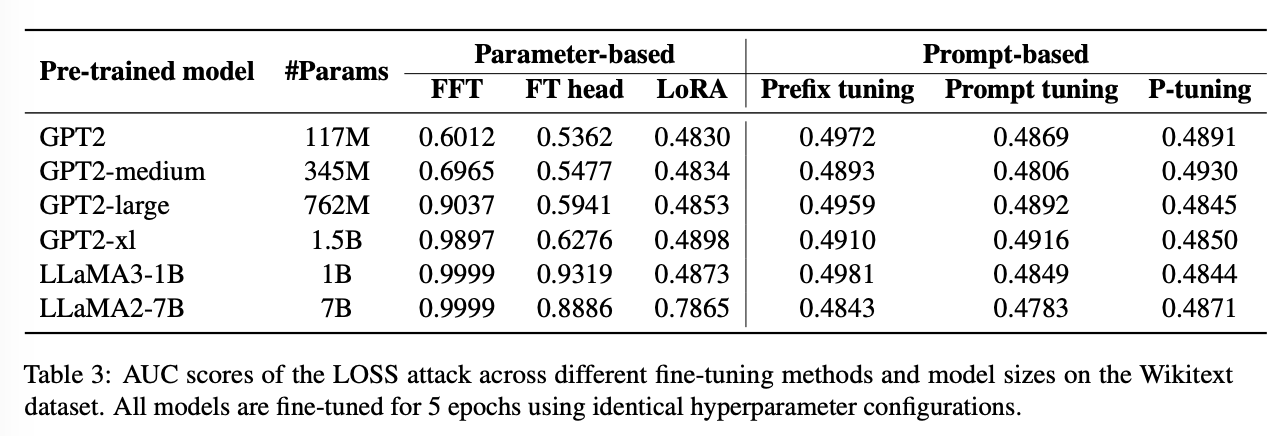
요약: 파라미터 바꾸는 애들은 모델 크기 커질수록 더 잘 외웠는데 반대는 미미하더라 (low sensitivity of prompt tuning to model scale)
특히, gpt2의 경우나 1B 스케일에서 LoRA는 사실상 거의 못외움
Impact of Downstream Tasks
Observation ♯4 Prompt-based tuning leads to stronger memorization in structured tasks than in other downstream tasks.
다운스트림 태스크의 종류에 따라서도 다를 수 있음. 이를 위 LLaMA2-7B를 다양한 방법을 통해 학습시키고 LOSS attack against에 대해서 각각을 평가해봄
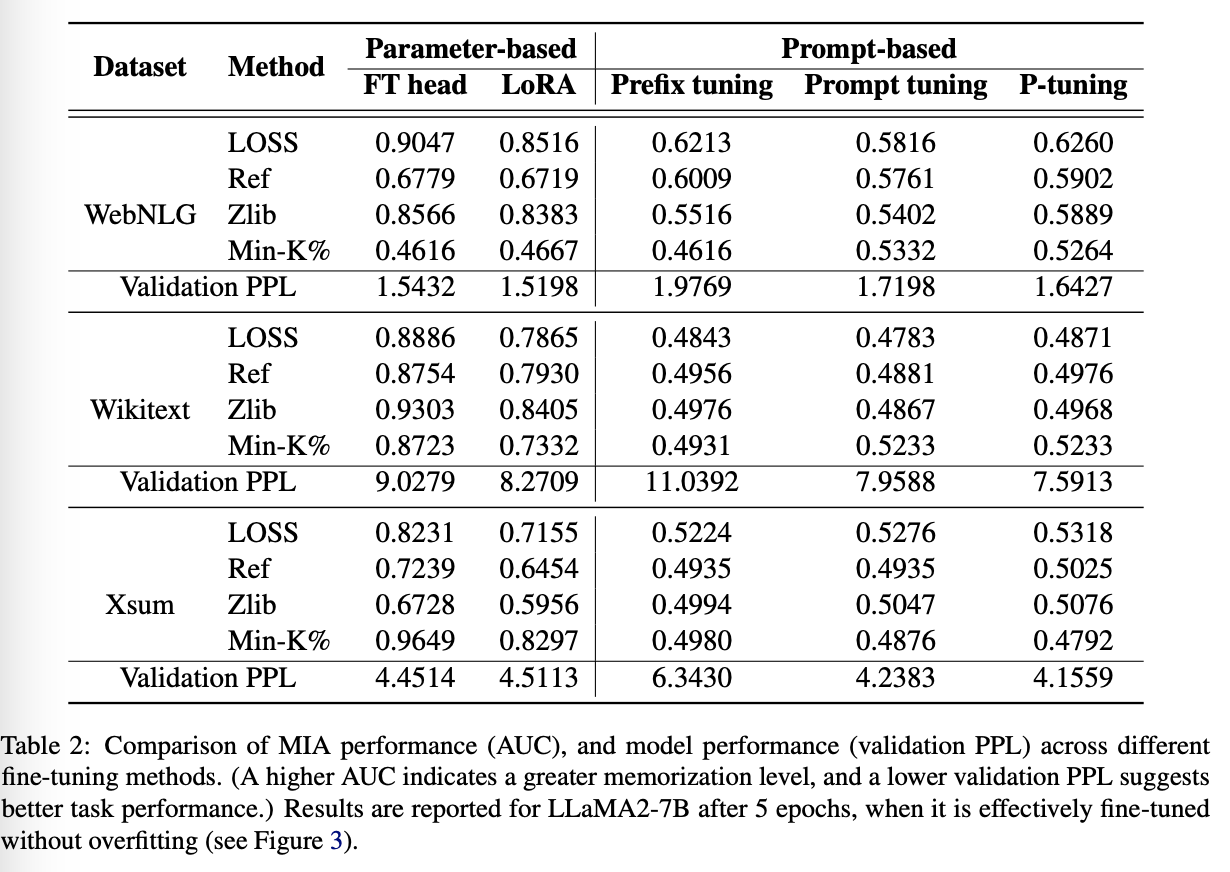
Prompt-based 만 봤을 때, WebNLG가 다른 것들에 비해서 성능이 높다
아마도 구조화된 pattern학습에는 유리한 것 같다
Impact of LoRA Placement on Memorization
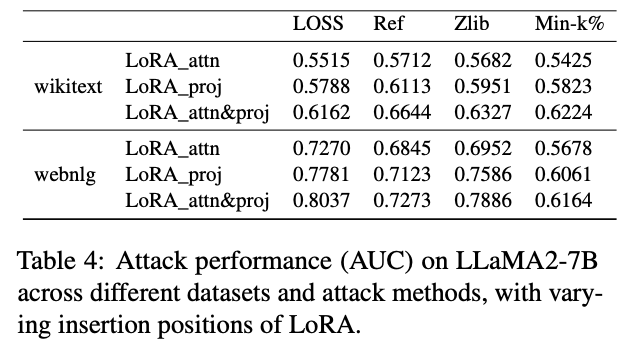
AUC↑ ⇒ 기억(privacy risk)↑
- Projection > Attention
- LoRA를 projection layer에만 적용할 때, 두 데이터셋 모두 네 가지 MIA 지표에서 AUC가 일관되게 상승 → 기억이 더 강해짐.
- Both layers = 기억 제일 강함
- Attention + Projection 동시 적용 시 가장 높은 AUC → 최대 수준의 memorization.
- 메커니즘 해석
-
Projection layer는 특징 변환, 정보 압축을 담당 → 학습 데이터의 구체적 패턴을 더 잘 ‘붙잡아 두는’ 위치.
-
결과는 Meng et al. (ROME)의 Transformer 기억은 주로 projection 층에 집중한다는 가설을 재확인.
Practical한 관점에서…
-
프라이버시에 민감한 애플리케이션에서는 LoRA를 attention 층에만 삽입하거나 rank를 낮추어 위험을 완화.
-
성능과의 트레이드오프가 필요할 때, 삽입 위치(attn vs proj)와 범위(단일 vs 복합 층)를 주요 조절 변수로 활용하면 효과적일 수 있겠다!
Limitation
너무 많죠..하지만 저자가 이야기한 것만 말해보겠습니다.
-
larger model
-
MoE 같은 다른 구조
-
데이터 적음