Inferring from Logits: Exploring Best Practices for Decoding-Free Generative Candidate Selection
논문 정보
- Date: 2025-01-02
- Reviewer: 조영재
- Property: LM
Evaluation을 할때 많은 벤치 데이터셋들은 multiple choice 형태를 갖추고 있음. 근데 아직까지 작은 모델들은 instruction following이 잘 안돼서 파싱도 맞춰줘야 하고 프롬프트도 모델에 맞게 수정해야함. 혹은 모델의 답변을 gpt 사용해서 다시 mapping 시켜줘야함. → 모델에 따라 다른 프롬프트를 사용하는게 불공평 한 것 아닌가? 모두를 통합할 수 있는 방법은 없을까? logit을 이용해 무조건 mapping 시킬 수는 없을까?
uncertainty가 조금 문제가 될수도…? 또, A라는 대답이 아니라 As, An apple 등등 A 로 시작하는 단어를 말하려던 것일수도 있겠다.. 실제 model의 답변이 첫 token step의 logit과 상관관계가 있을까? logit을 이용해 측정을 하는게 편하긴 할텐데 의미가 있을까? 어쨌든 유저가 보게 되는 것은 text인데 어떻게든 text output 형태를 고수해야 하는가? 이 eval 방식은 cot를 간과하는 것이려나?
1. Introduction
-
Motivation: While LLMs typically rely on autoregressive decoding (token-by-token generation), many real-world tasks involve selecting an answer from a candidate pool—such as multiple-choice QA or clinical decision-making.
-
Problem: Full decoding is slow and breaks gradient flow; thus, decoding-free methods are increasingly used (i.e., using initial logits only).
-
Contribution:
-
Provides the first formal definition of decoding-free generative candidate selection.
-
Performs a comprehensive empirical evaluation across diverse tasks (QA + clinical).
-
Compares 5 decoding-free methods, full decoding, and dense retrieval.
-
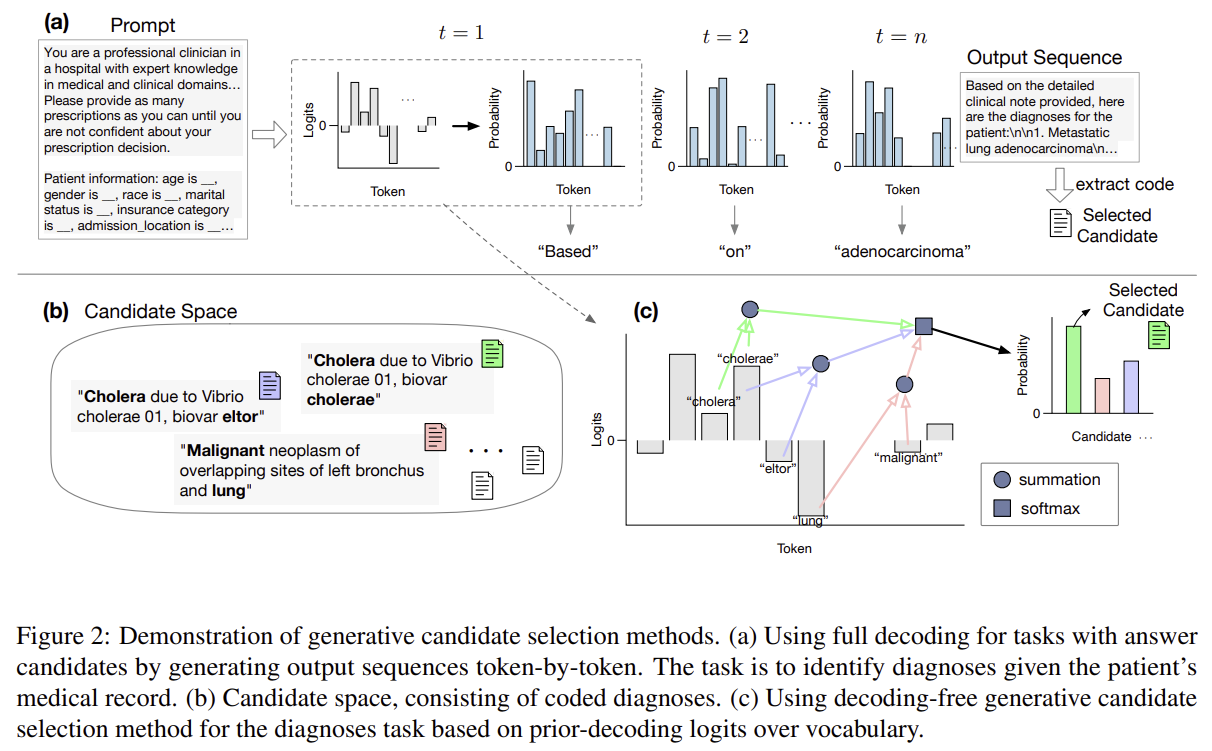
2. Problem Formulation
2.1 Generative LMs
- traditional full decoding
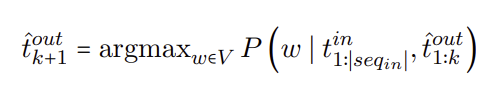
- full decoding with Cand. Selection
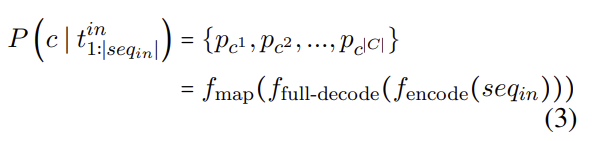
2.4 Decoding-Free Generative Candidate Selection
- Goal: Estimate the candidate probabilities directly from the first-step logits without generating tokens.
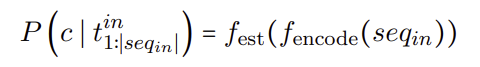
- Uses only the raw logits and candidate token representations.
3. Candidate Selection Methods
3.1 Estimation via Logits
-
First-token logit: Use logits of first token in candidate
-
Last-token logit
-
Average logits: Mean over all candidate token logits
-
Sum logits: Sum over all candidate token logits
-
Sample Avg.: Average logits of sampled tokens (used for long candidates)
logits of k-th token(4) Averaged token logits (5) Sum of token logits (6)
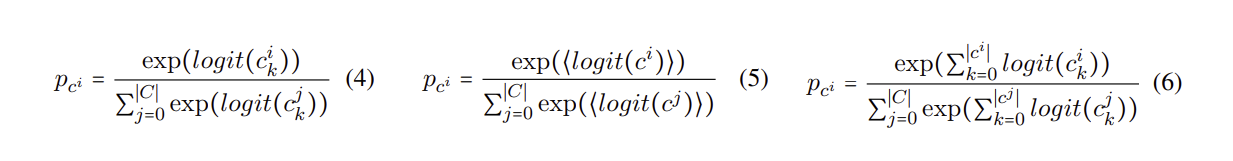
3.2 Baselines
-
Full decoding: Followed by mapping output to candidate
-
Dense retrieval: Facebook DPR embeddings with cosine similarity
4. Evaluation Settings
4.1 Tasks
-
Limited-candidate tasks (3–5 options):
- CommonsenseQA, MMLU, GPQA, BIG-Bench, ARC
-
Massive-candidate tasks (1K–94K options):
- Diagnosis (ICD-10), Procedures (ICD-10-PCS), Lab Orders (LOINC), Prescriptions (ATC)
4.2 Base LMs
-
Decoder-only: LLaMA3 (8B), Mistral (7.3B)
-
Encoder-decoder: Flan-T5 XL (11B)
-
Variants with and without instruction tuning used
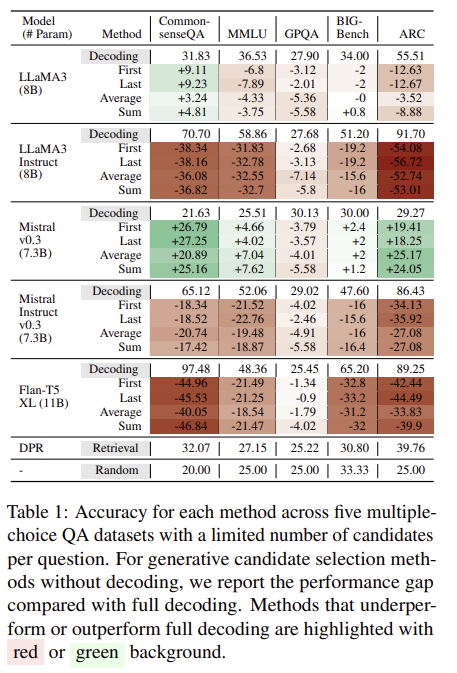
5. Experimental Results
Key Insights
-
Insight 1: Estimation methods are strong when full decoding fails (e.g., weak models or hard tasks like GPQA)
- GPQA 처럼 점수 낮은 task에선 비슷하더라
-
Insight 2: When full decoding works well, estimation methods fall short
- 점수가 높은 task에선 잘 못하더라
-
Insight 3: Instruction tuning helps full decoding but not decoding-free estimation
- instructinon tuning을 하건 안하건 점수를 확인해보면 비슷하다 (31.83 + 9.11 vs 70.70 - 38.34)
-
Insight 4: Method effectiveness varies with model and dataset
- 모델마다, 데이터셋마다 매우 다르다.
-
Insight 5: Decoding-free estimation is far more efficient (up to 57.6× speedup)
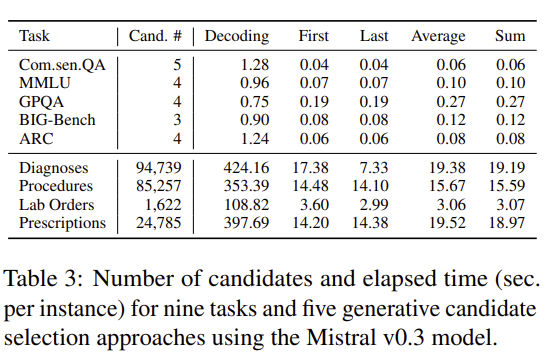
Detailed Analyses
- 5.2 Output step: (a)
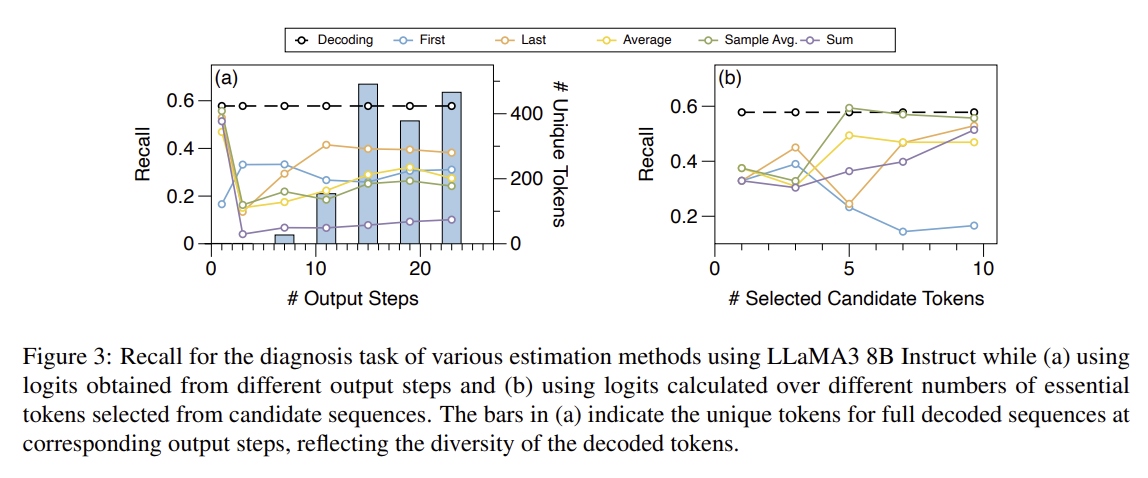
-
First-step logits are the most informative and performant
-
5.3 Candidate token selection: (b)
-
GPT를 이용해 토큰 중에 중요한 토큰만 남겨
-
Using the entire sequence is better than selecting keywords
-
-
5.4 Sensitivity:
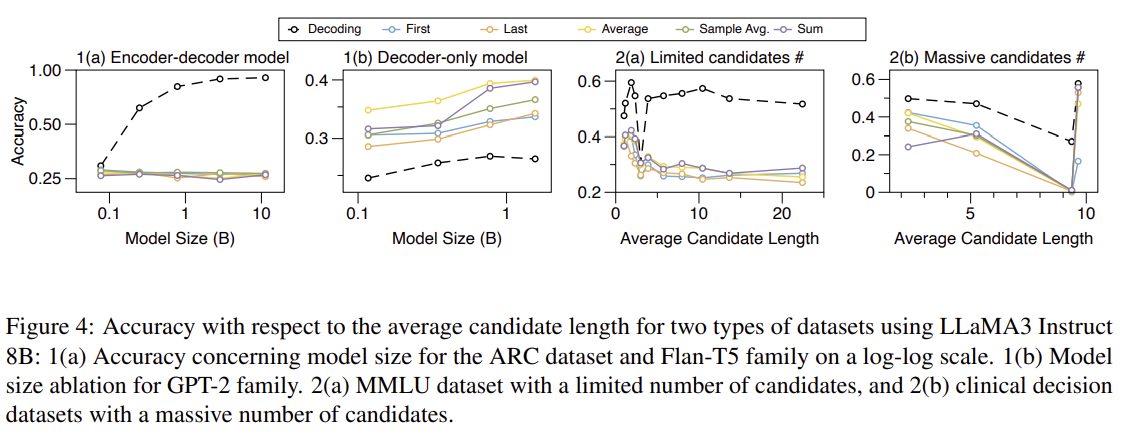
-
Decoder-only models benefit from increased size
-
Longer candidate sequences reduce performance
6. Related Work
-
Classification-based methods require retraining and don’t generalize to dynamic candidates.
-
Retrieval models struggle with reasoning tasks.
-
This is the first systematic evaluation of decoding-free methods.
7. Conclusion & Future Work
-
Main findings:
-
Estimation from logits is a viable alternative, especially when full decoding is brittle.
-
First-step logits are optimal.
-
Simple heuristics like token averaging or summing provide robust approximations.
-
-
Future directions:
-
Use multiple output steps for estimation.
-
Compress candidate sequences into key tokens using LLMs.
-
Improve efficiency using techniques like PagedAttention.
-
Appendix
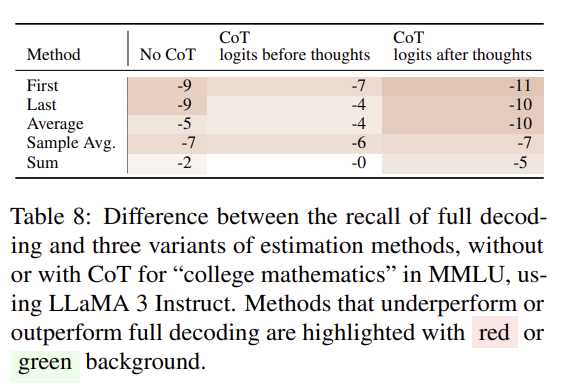
full decoding 성능 대비 logit estimation (with cot and without cot) MMLU 수학 성능표.