OpenVLA: An Open-Source Vision-Language-Action Model
논문 정보
- Date: 2025-01-14
- Reviewer: 전민진
Summary
-
기존의 VLA모델들은 1) closed, 2) 새로운 task에 효율적으로 FT하기 어렵다는 단점이 존재
-
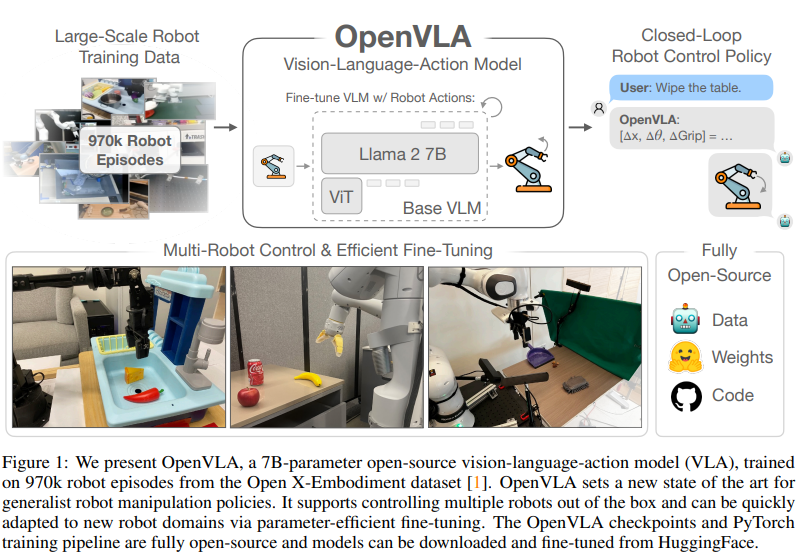
현재 공개된 public model중 최고의 성능을 내는 vision-language-action model
-
llama-2-7B모델에 visual encoder 2개(SigLIP, DINOv2)를 사용해서 970K real-world robot demonstration(Open-X-embodiment)으로 학습
-
training dataset 외의 여러 로봇을 control할 수 있음
-
-
기존의 closed model인 RT-2-X(55B)보다 훨씬 작은 크기(7B)로 훨씬 높은 성능 달성
-
29개의 task에 대해서 RT-X-2보다 7배 낮은 파라미터로 16.5% 좋은 성능을 냄
-
특히 FT에서 압도적인 성능을 보임
- LoRA로 fine-tuning이 가능하며, quantization을 해도 큰 hit ratio drop이 없음
-
-
어떻게 모델을 구상하면 좋은지에 대한 insight가 많이 나와 있음
-
모든 코드가 공개 되어 있어 이를 기반으로 연구를 시작하면 좋음
Introduction
- robotic dataset은 대량으로 구축하기가 어려움
⇒ 기존의 vision, language 모델의 능력을 사용해서 일반화가 잘 되도록 모델을 만들어보자!
-
기존 연구
-
VLM을 통합해서 robotic representation learning 학습
-
task planning, execution을 위해 modular system으로 사용
-
따로 VLA 모델을 학습하기 위해 사용
- 보통 pretrained model을 갖고 와서 PaLI처럼 바로 robot action을 생성하도록 FT
-
multi-robot dataset은 일종의 multi-ligual dataset느낌으로 접근해볼 수 있지 않을까?
-
논문의 저자들이 지적하는 기존 연구의 문제점
-
current model are closed
-
새로운 로봇, 환경, 태스크에 사용하고 adapting하기에 최고의 방안을 제공하지 않음
-
-
970K의 방대한 데이터셋에 대해 pretrained된 fully open source VLA model, OpenVLA를 제안
-
FT결과 기존에 FT로 SOTA였던 Octo보다 성능이 훨씬 높음
-
multi-task setting, multi object에 대해서 성능이 크게 향상
-
Related works
-
Visually-Conditioned Language Models
-
patch을 token단위로 보고, pretrained visual transformers에서 feature를 추출, language model의 space로 project하여 사용
-
multi-resolution visual feature에서 학습된 pretrained backboen을 사용
- DINOv2에서 얻은 low-level의 spatial infomration과 SigLIP에서 얻은 higher-level semantic을 섞어서 visual generalization을 높이고자 함
-
-
Generalist Robot Policies
-
Octo - 1B밑
-
out-of-the-box의 여러 로봇 컨트롤이 가능하도록 generalist policy를 학습
-
새로운 로봇 세팅에 대해 유연한 finetuning이 가능하도록 ㅏㅎㅁ
-
pretrained language embedding과 visual encoder를 model component로 사용, model 자체는 scratch부터 학습
-
-
이외 달리, OpenVLA는 좀 더 end-to-end 느낌으로다가, robot action 생성하기 위해 VLM을 finetuning, actino을 langauge model vocab에서의 token으로 사용
-
-
Vision-Language-Action Models
-
기존의 연구들은 보통 VLM backbone에 robot control action을 fuse
-
장점 : 기존 VLM component와 align, 로봇만을 위한 모델이 아니기 때문에 VLM의 인프라를 활용할 수 있음
-
단점 : single robot 혹은 simulated setup에 한정되어 학습, 평가 ⇒ generality가 떨어지고, closed model / 모델이 크기 때문에 작은 코드 수정으로도 B단위의 policy를 다ㅣㅅ 학습해야 함
-
-
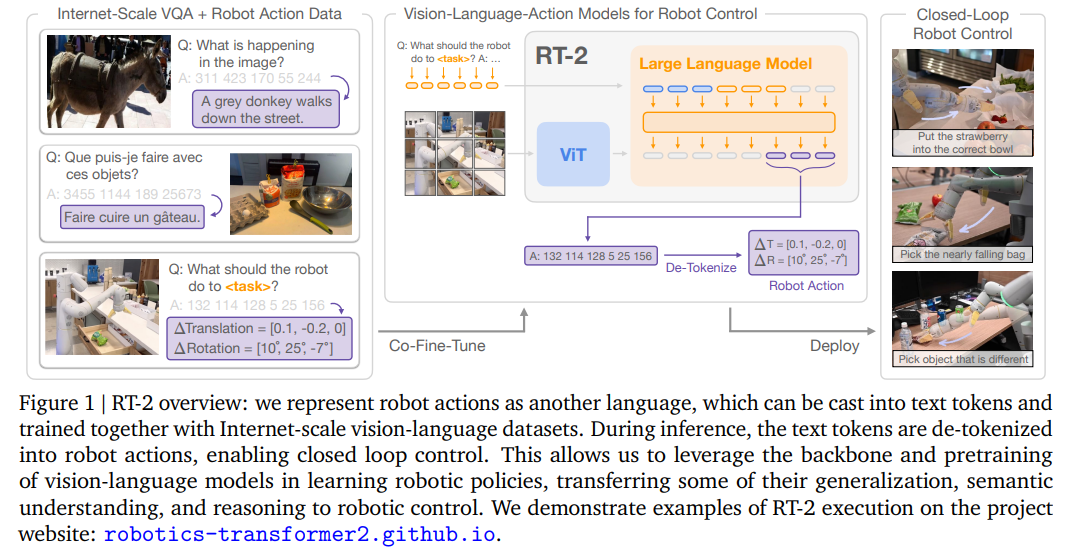
-
RT-2-X와 OpenVLA의 차이
-
작은 모델로 더 높은 성능
-
FT세팅에 대해 분석
-
PEFT가능
-
공개 모델
-
Proposed Method
-
VLA 모델 개발을 위한 자세한 practice는 아직 연구가 덜 됨
- 어떤 backbone, dataset이 좋은지, hyperparameter에 따라 성능이 어떤지..
-
Preliminaries: Vision-Lnaguage Models
[보통의 VLM 구조]
-
visual encoder : image을 patch 단위로 임베딩
-
projector : image embedding을 language space로 mapping
-
LLM : 보통 학습은 paired 또는 interleaved VL data에 대해 next token perdiction으로 진행
-
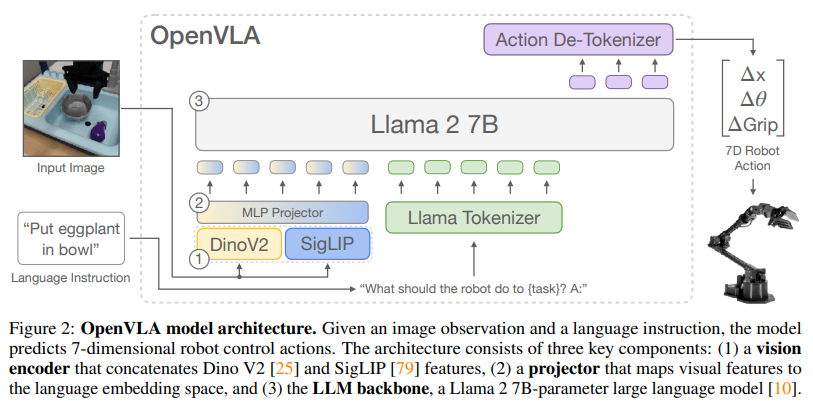
본 논문에서 사용한 backbone VLM은 Prismatic-7B VLM
-
Prismatic-7B : 600M visual encoder, 2-layer MLP projector, 7B llama2 LM
-
2파트의 visual encoder사용 : SigLIP, DINOv2
-
LLaVA 1.5 data mixture로 FT됨
- 1M image-text and text-only data samples from open sources
-
-
-
OpenVLA training procedure
-
action prediction을 vision-language task로 formatting
- image, text를 input으로 넣어서 string of robot action을 생성하도록 함
-
continous robot action을 discrete token action으로 mapping
-
로봇 action의 각 차원을 256 bin으로 쪼갬
-
각 action 차원에 대해서 bin width를 일정하게 설정(1st, 99th quntile에 있는 train dataset에 있는 actino 분포 기반)
-
256개의 새로운 token을 vocab에 추가함(부족한 슬롯은 잘 안쓰는 token에 overwriting)
-
-
-
Training data
-
Open X dataset을 알맞게 curation
-
모든 데이터셋에 대해 일관된 input, output space 사용
- 한손로봇, 1/3 person camera data반 활용
-
embodiment 비율 조정
- sampling시 많으면 down weight, 적으면 upweight 활용
-
Octo 출시 이후 추가된 DROID dataset도 같이 섞어서 학습해봤으나 별로 도움 안됐다고 함(10%라 큰 영향이 없는거 같다고 함)
-
-
-
OpenVLA Design decision
: BridgeDataV2로 미리 디자인 관련 실험을 함
-
VLM Backbone
-
IDEFICS-1과 LLaVA, Prismatic으로 실험
-
prismatic : visually conditioned LM(LLaVA보다 높은 성능, visual encoder는 freeze, projector와 LM만 학습)
-
IDEFICS < LLaVA < Prismatic 순의 성능을 보임
-
IDEFICS와 LLaVA는 장면에 하나의 object가 있을 때는 잘됨
-
LLaVA가 I에 비해서 좀 더 language grounding이 잘 되긴 함
-
Prismatic이 성능이 잘 나온 이유는 SigLIP-DINOv2 backbone때문인걸로 추정
-
-
-
-
Image resolution
- 저화질(224224)이나 고화질(384384)이나 큰 성능 차이는 없으나 고화질이 학습시간 3배 더 소요
-
Fine-tuning vision encoder
-
VLM학습할 때는 visual encoder를 학습하지 않음
-
하지만 VLA에서는 visual encoder를 FT하는게 매우 중요
-
⇒ 기존 비전 태스크에서 중요한 포인트와 다르기 때문.. 이라 추정
-
Training epochs
-
많이 돌릴수록 real robot performance가 지속적으로 향상
-
27번 돌림
-
-
Learning rate
- 2e-5(VLM사전 학습할 때와 같은 learning rate)
-
Intrastructure for trainign and inference
-
64대 A100으로 14일, 21500 A100 Hours, batch size는 2048
-
inference시 OpenVLA는 15GB의 GPU mem필요(bf16), RTX 4090 GPU기준 6Hz의 속도
-
remote VLA inference도 코드 있다고 함
-
Experiments
-
Research question
-
OpenVLA가 기존 모델들에 비해 여러 로봇과 다양한 조건의 generalization에서 성능이 어떤가?
-
OpenVLA를 새로운 로봇 세팅과 태스크에 대해 효과적으로 FT할 수 있는가
-
OpenVLA의 학습과 inference시 PEFT와 quantization방법론을 적용해 computational cost를 줄일 수 있는가?
-
-
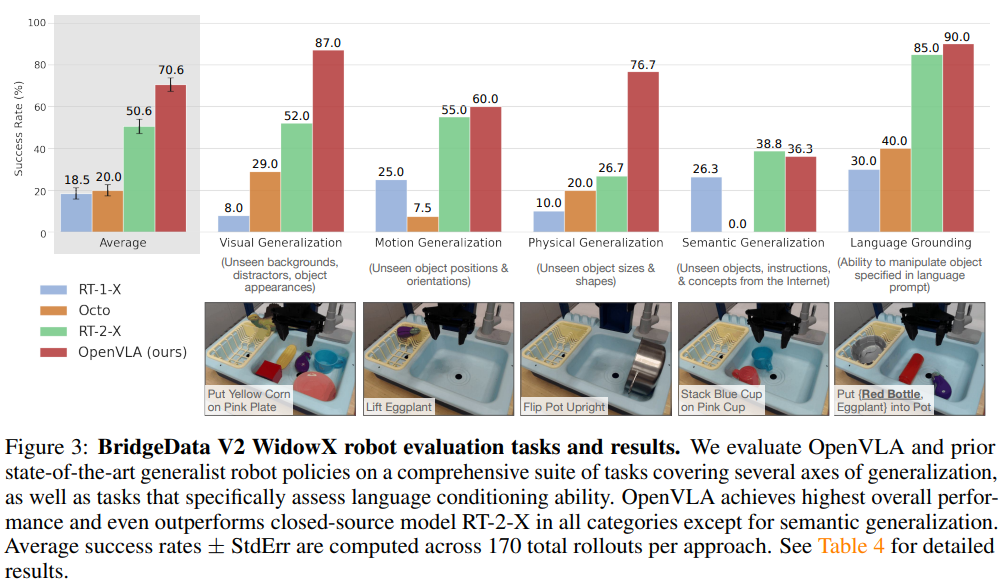
Direct Evaluation on Multiple Robot Platforms
-
Robot setups and task
-
unseen robot : WinowX from BridgeData V2, mobile manipulation robot from RT-2 and RT-2 evaluation(Google robot)
-
generalization axes
-
visual : 색, 배경, distractor
-
motion : 위치, 시작점
-
physical : 크기, 모양
-
semantic : 모르는 target object, instruction
-
-
-
Comparision
-
RT-1-X(35M)
-
RT-2-X(55B)
-
Octo(93M)
-
-
OpenVLA의 압도적인 성능
- 더 큰 robot action dataset + dataset cleaning, SigLIP과 DINOv2를 같이 썼기 때문인걸로 추정
-
RT-2-X는 그래도 어느정도 일반화 성능을 보임
- 큰 범위의 internet pretraining + robot action과 internet pretraining data를 같이 학습
-
RT-1-X와 Octo는 distractor가 나타나면 갈피를 못잡음
-
Octo 논문에서는 octo가 RT-2-X보다 잘하는거 같았는데, 여기서는 아님
-
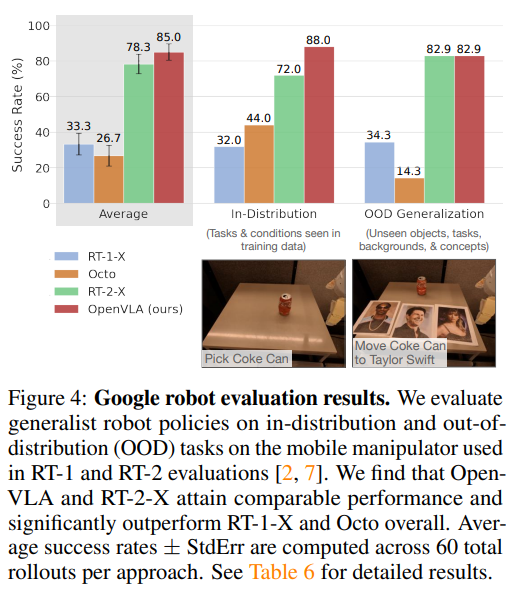
-
Data-Efficient Adaptation to New Robot Setups
-
실험 세팅
-
10-150개의 demonstration으로 이뤄진 target dataset에 대해서 full FT
-
Franka-Tabletop : 책상에 7-DoF robot arm 꽂아 놓고 실험
-
Franka-DROID : 모션데스크에서 실험
-
비교군
-
diffusion policy : SOTA data-efficient imitation learning 방법
-
diffusion policy : 3개 보고 8개 예측
-
diffusion policy(matched) : 1개 보고 1개 예측
-
-
Octo : target task에 대해서 FT
-
OpenVLA도 하나 넣어서 하나 예측하는걸로 알고 있음
-
-
-
결과
- pretrained model에 FT하는게 성능이 높았음
-
⇒ 언어 기반으로 다양한 태스크에 잘 adapt되도록 함
- 다른 애들은 narrow single instruction(diffusion policy) or diversity instruction 둘 중 하나만 잘하는데, openVLA는 다 잘함
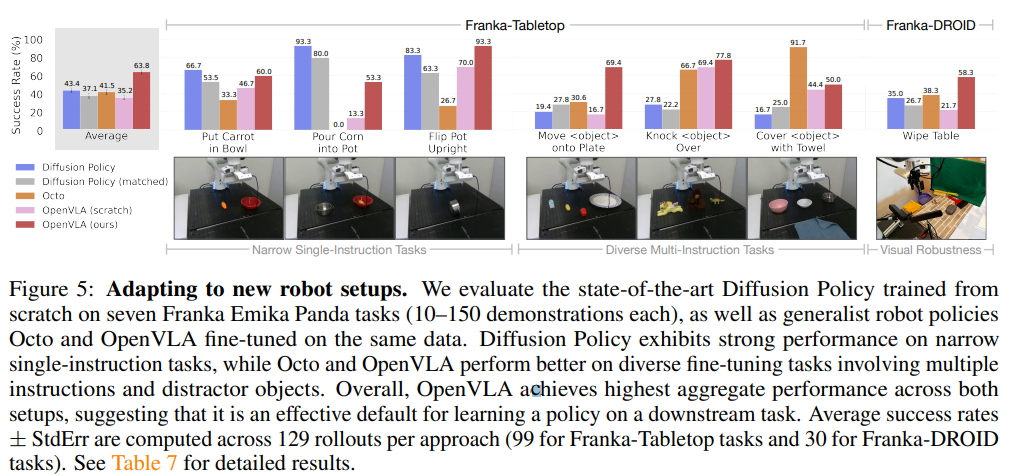
-
Parameter-Efficient Fine-tuning
-
비교군
-
Full FT
-
last layer only : transformer backbone의 마지막 레이어만 학습
-
sandwich FT : visual encoder, token embedding matrix, last layer만 학습
-
LoRA
-
-
실험 결과
-
LoRA가 짱!
- A100 한대 10-15시간이면 학습 가능, full FT에 대해서 computation 8배 단축
-
-
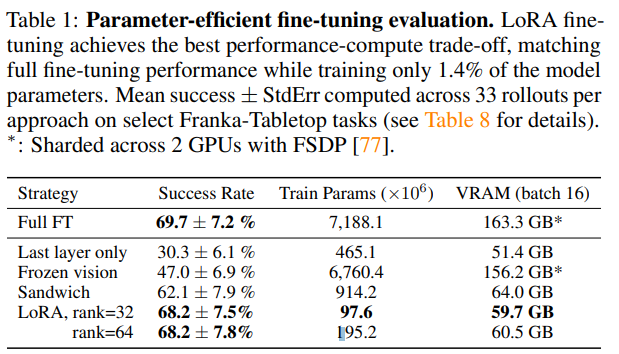
-
Memory-Efficient Inference via quantization
- 4bit quantization을 사용하면 GPU mem은 반절, 성능 유사, Hz는 향상(bf16과 비교시)
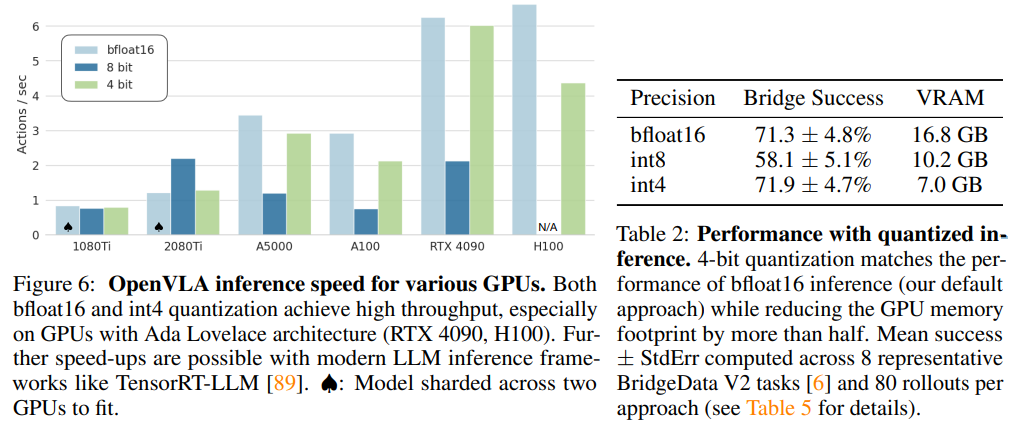
Discussion and Limitation
-
single-image observations만 지원
-
throughtput을 향상시키는게 중요
-
성능 향상의 여지는 있음 - 아직 90%도 달성하지 못함