ReFT: Reasoning with Reinforced Fine-Tuning
논문 정보
- Date: 2025-03-25
- Reviewer: 김재희
- Property: Reinforcement Learning, SFT
1. Intro
SFT보다 RL이 downstream task 성능 개선에 있어 좋을지도…?
preliminaries
PPO
- Original RLHF Objectives
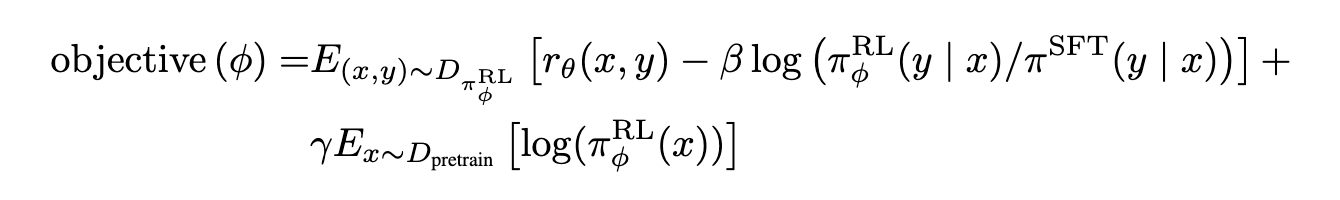
-
학습 중인 모델(policy, \pi^{RL}_\phi)의 Reward를 최대화
-
학습 전 모델(SFT, Initial Policy, \pi^{SFT})과 너무 멀어지지 않도록 제약
- 마지막 항도 비슷한 역할
⇒ 실제 학습 가능한 loss가 아님
- reward: 전체 문장에 대해 주어지는 scalar 값
- 각 토큰에 대해 어떻게 역전파 시키죠…?
- PPO Objectives
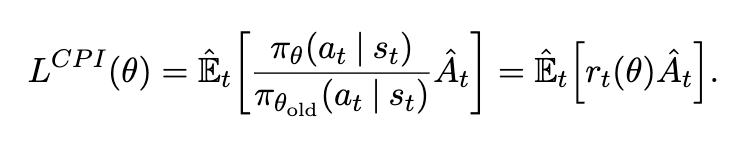
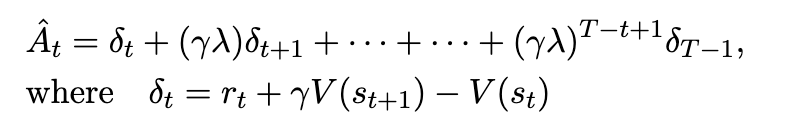
-
value function( V(.))의 도입으로 가능!
-
value function: 각 토큰 시점에서 가지고 있는 생성된 토큰들의 가치
-
high value: reward를 높이는 방향으로 미래에 생성할 가능성이 높음
-
row value: reward를 높이는 방향으로 미래에 생성할 가능성이 낮음
-
-
→ 단순히 최종 Reward를 고려하는 것이 아니라, 각 토큰의 생성 시점에서 정말 그 토큰의 reward에 대한 기여도를 확인
-
PPO 주의점
-
학습에 활용되는 모델 갯수 (4개)
-
policy model: 학습 대상 모델
-
initial model: 학습 대상 모델의 복사본 (학습 X)
-
reward model: scalar reward value를 생성하는 모델 (학습 X, 학습 signal 생성)
-
value model: 학습 대상 모델 - lm head + linear layer (다른 방식도 있는듯?)
-
각 token의 last representation에 별도의 linear layer 통과
-
각 토큰의 value 계산 역할 (학습 X)
-
-
-
RLHF
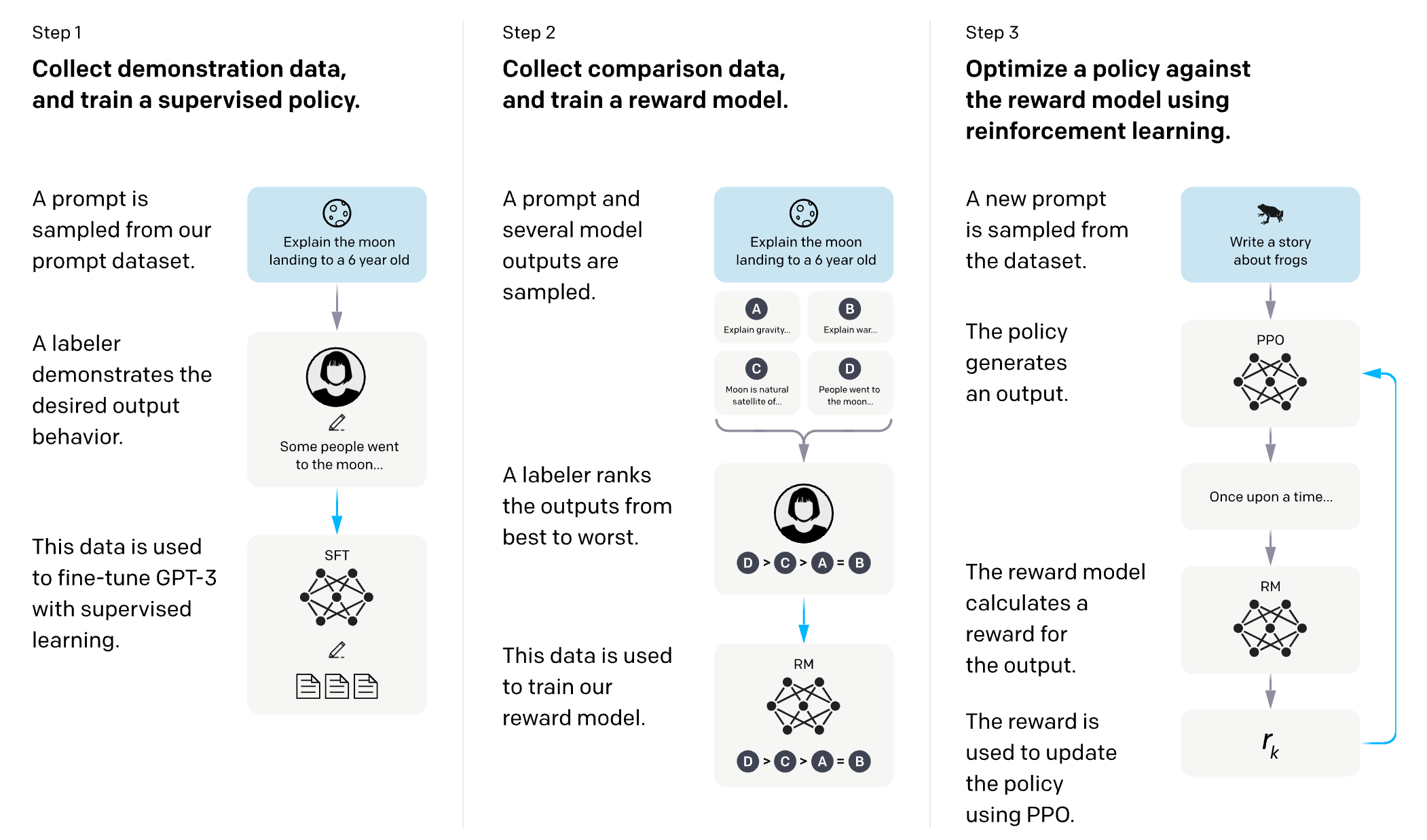
Training language models to follow instructions with human feedback
-
방법론 목표: instruction을 따르는 “안전”하고 “사실적”이며 “믿을만”한 출력을 내도록 학습
-
Safety, Alignment 목적의 학습 방법론
-
post-training 방법론으로서 널리 활용
-
What makes reinforcement learning effective in LLM paradigm?
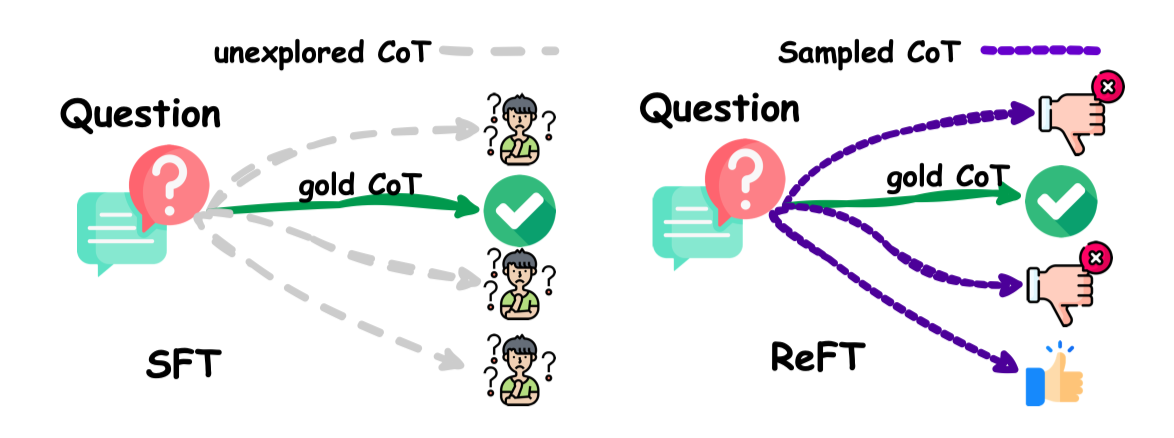
-
diversity of trajactory: 질문과 정답은 하나지만, 과정은 다양하니까.
-
질문과 답이 있다 하더라도, reasoning path는 매우 다양하게 존재할 수 있음
- annotation을 통해 모든 trajactory를 확보하는 것은 불가능
-
LLM이 일정 수준의 추론 능력을 갖추었다면, 스스로 trajactory를 explore할 수 있을 것.
- 우리는 좋은 trajactory를 평가하고, Signal을 주입할 수 있으면 된다.
-
2. Method
Main Research Question
RLHF를 fine-tuning에 써보면 어떻게 될까?
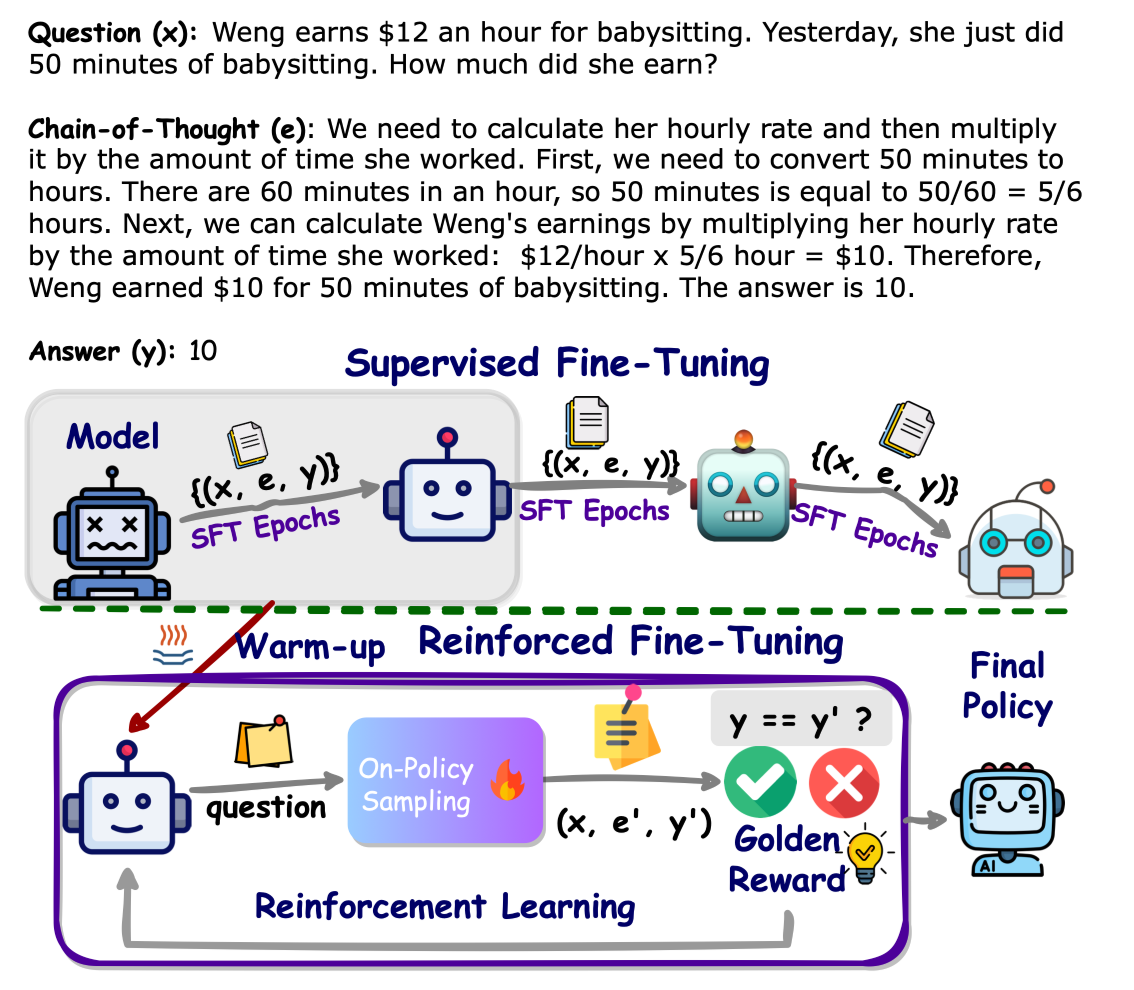
-
논문 요약
-
SFT로 warm up 학습 진행
-
RLHF를 통해 학습
- 사전에 reward function, ground truth answer 정의
- 우왁굳!
-
Notations
- CoT ( \textbf{e}): CoT trajactory including final answer
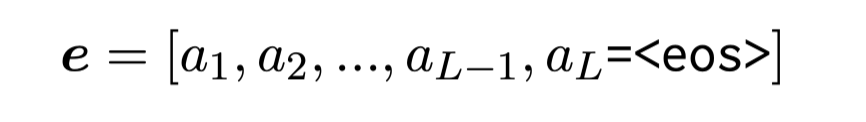
- state: all tokens including question and generated so far
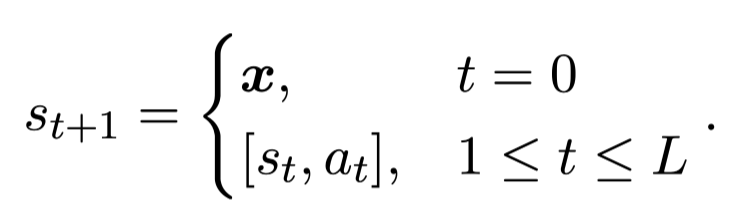
- policy model( \pi_\theta): 학습 대상 모델
Objectives
- SFT
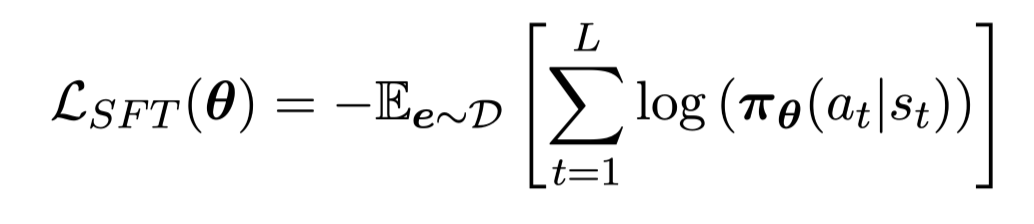
- RL: RLHF 수식과 동일합니다.
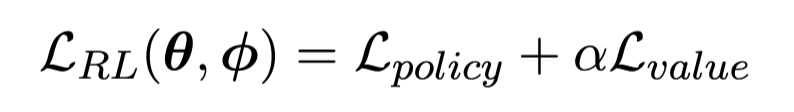
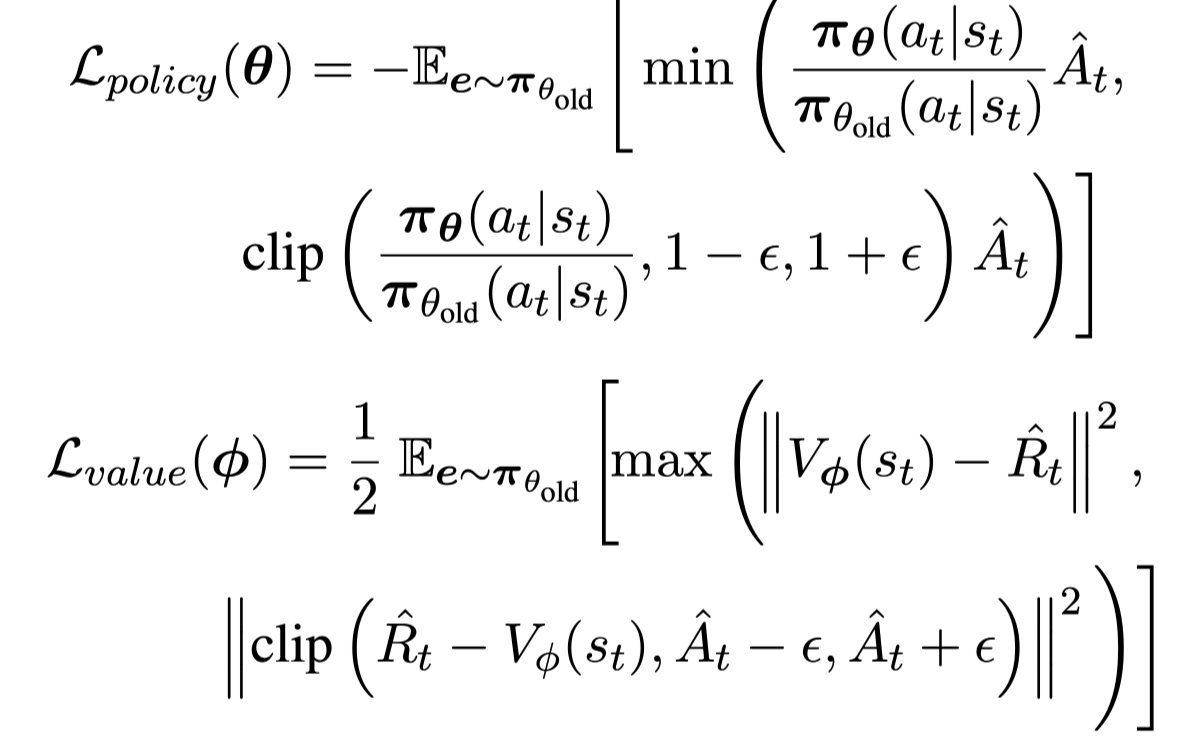
- value loss: Value model의 linear 학습을 위해 쓰이는듯
Algorithm

Dataset
-
SFT 때 활용된 데이터를 그대로 활용 가능
-
SFT: (query, reasoning, answer)를 사용
-
RL: (query, answer)를 이용
-
RL의 경우 매 epoch마다 서로 다른 reasoning이 생성될 수 있으므로 SFT 데이터를 그대로 이용하여도 문제가 될 것은 없다.
-
RL Fine-tuning을 위한 추가 데이터 확보 필요성 X
-
-
Reward function
-
fine-tuning을 위해 가장 중요한 설계 요소
-
논문에서는 단순하게 접근
-
실험 데이터: 수학문제
-
reward function: 최종 예측값의 정답 유무
- 더 fine-grained reward를 주기위해 partial reward 사용
-

- 생성된 예측값이 숫자인 경우 0.1의 reward 부여
틀렸지만 어쨋든 숫자 예측했으니까!
Training Reward Model
(학습을 위한 reward model이 아닙니다. )
-
best SFT checkpoint를 initial model로 선택
-
linear
Reranking & Majority Voting
학습된 모델에 대한 추가적인 성능 개선 방법론
-
Reranking: test query 당 100개의 generation 진행
- reward model의 점수가 가장 높은 생성문을 최종 생성문으로 선택
-
majority voting: test query 당 100개의 generation 진행
- 100개의 정답 후보 중 가장 많이 생성된 값을 최종 정답으로 선택
3. Baselines
-
SFT: 기존에 마련된 학습 데이터를 활용하여 SFT 학습
-
Offline Self-training: SFT (warm up) 학습이 된 모델 이용
-
각 query마다 100개 generation 진행
-
전체 generation 중 정답을 맞춘 generation만 선택
-
선택된 generation 중 10개를 샘플링하여 SFT 추가 학습 진행
-
-
Online Self-training: 학습 과정 중인 모델에 대해 offline과 동일하게 생성 → filtering → SFT 진행
- 차이점: inital model을 이용한 SFT 데이터 생성 여부
Hyperparameters
ReFT
-
8 x A100 80GB
- Zero 2
-
SFT epoch: 2
-
RLHF epoch: 300 → 지속적으로 성능이 개선되어서 학습을 오래 시켰다고 표현
SFT
- epoch: 40 → 성능 개선이 없어 여기서 중단했다고 표현
Offline Self-training
-
SFT epoch: 40
-
self-training epoch: 20 → 성능 개선이 없어 여기서 중단했다고 표현
4. Experiments
Reasoning type
-
N-CoT: reasoning을 자연어로 진행
-
P-CoT: reasoning을 코드로 진행
Answer Type
-
GSM8K, SVAMP: numeric, 실제 정답 숫자 예측 태스크
-
MathQA: multiple choice, 4지선다
Main Result
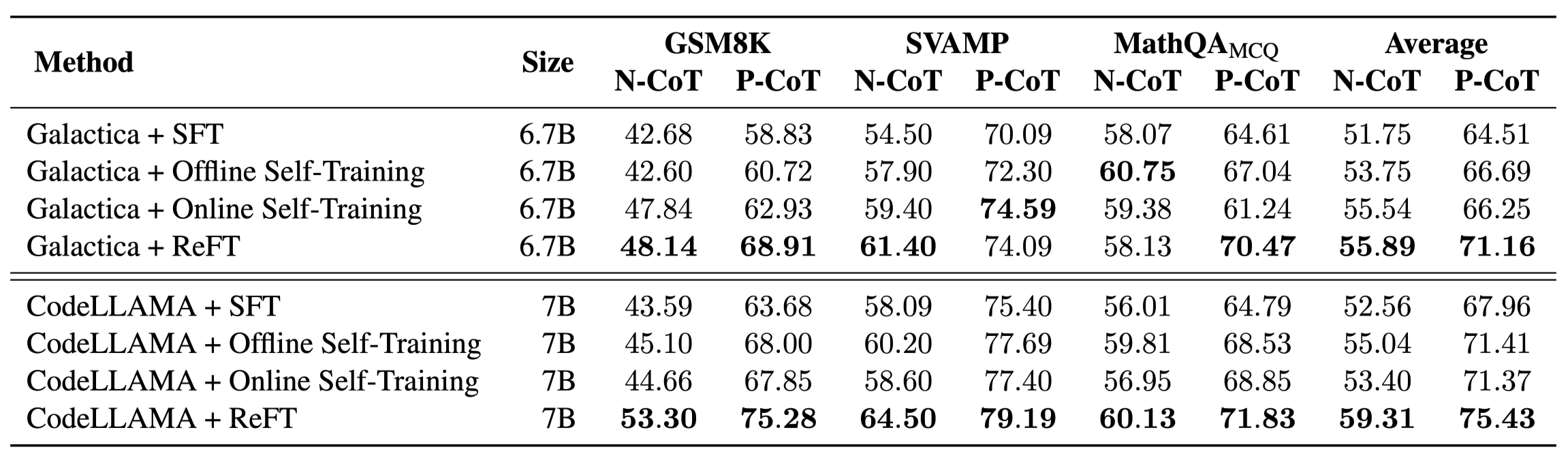
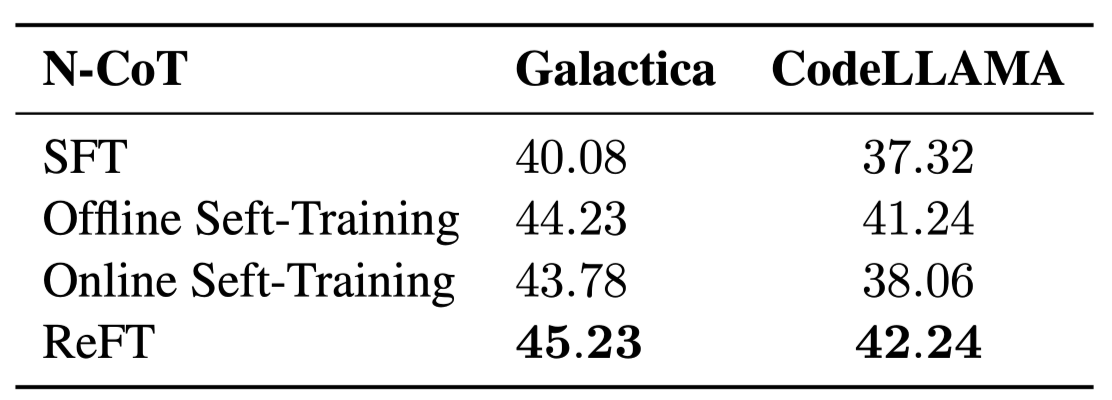
on-policy sampling과 RL이 성능 향상에 기여
-
ReFT
-
대부분의 벤치마크에서 ReFT가 가장 좋은 성능 달성 (MathQA 예외)
-
추가적인 annotated data나 reward model 없이도 높은 성능 달성
-
-
Self-training
-
offline: SFT 대비 성능 개선 확인, LLaMA 2 이후의 다양한 논문에서 확인된 내용
-
ReFT 대비 성능 개선 폭 제한적
-
→ *exploring *작업이 매우 중요함 확인
-
online: 여전히 ReFT 대비 성능 저하 확인
-
exploring은 진행되지만, 잘못된 예측을 학습에 활용 X → MLE 학습이 진행되니까
-
하지만 ReFT는 잘못된 예측도 학습에 관여
- 잘못된 예측 → low reward → model update
-
Reward Hacking for MathQA
-
MathQA: 4지선다 예측 문제
- 학습 중인 모델의 reasoning을 통해 reward hacking 문제 확인

-
모델의 추론 과정 중 잘못된 답을 도출하였음에도, 4지선다에서는 정답으로 예측해버림
-
reward 상으로는 맞추었다고 signal이 발생
-
모델: 잘못 예측하고 정답을 맞추는 것이 좋은 reasoning 이구나!
-
-
MathQA를 직접 정답 숫자 예측 문제로 전환하여 실험 진행
-
Main result와 다르게 ReFT가 가장 좋은 성능을 보임
- reward hacking을 방지하는 것이 RL에서 매우 중요함
-
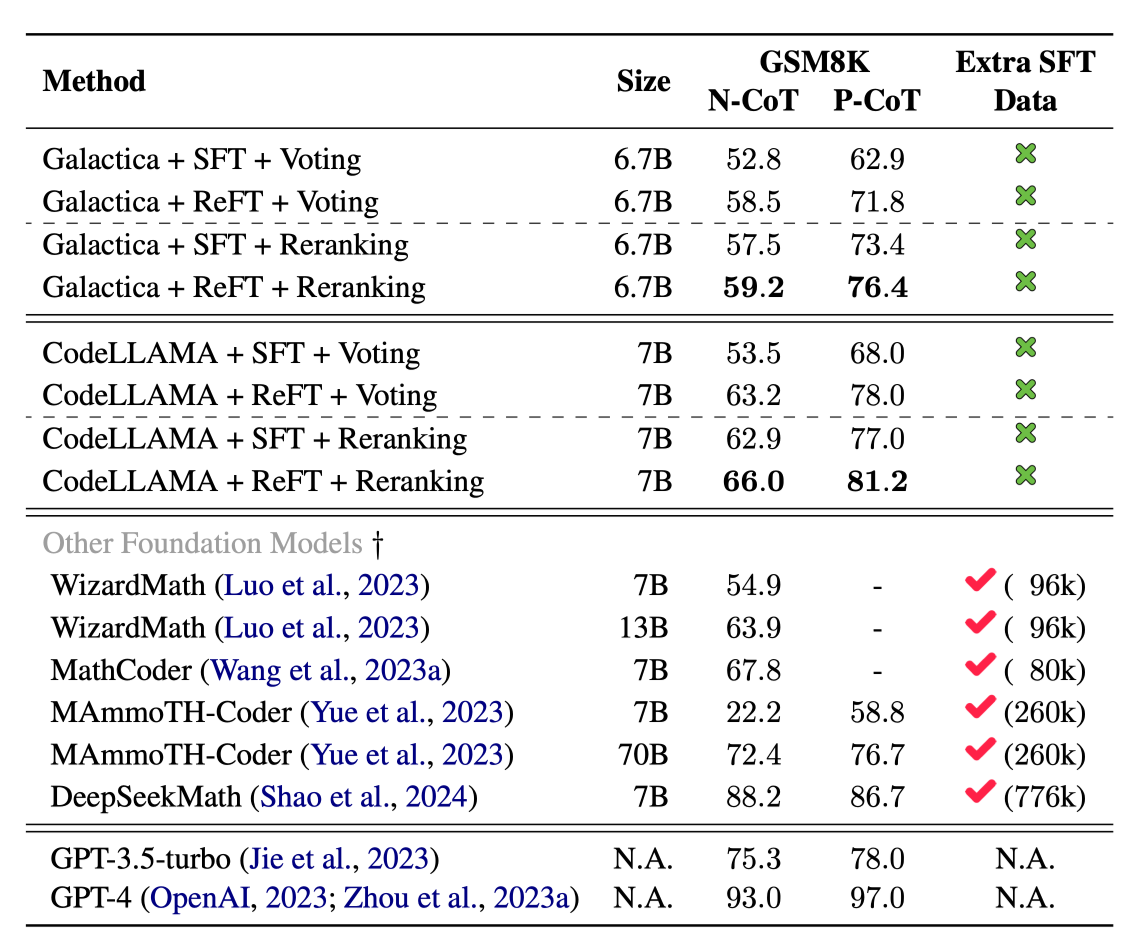
Majority Voting & Reward Reranking
-
추가 데이터 annotation을 이용하지 않고도 annotated data를 활용하는 방법론들과 유사한 성능 도출
- P-CoT에서 특히 높은 성능 확인
ReFT w/ small models
-
RLHF 프레임워크의 핵심
- policy model이 적절하게 exploration 할 수 있는가? → 작은 모델의 경우 정답 근처로도 exploration을 하지 못할 수 있음
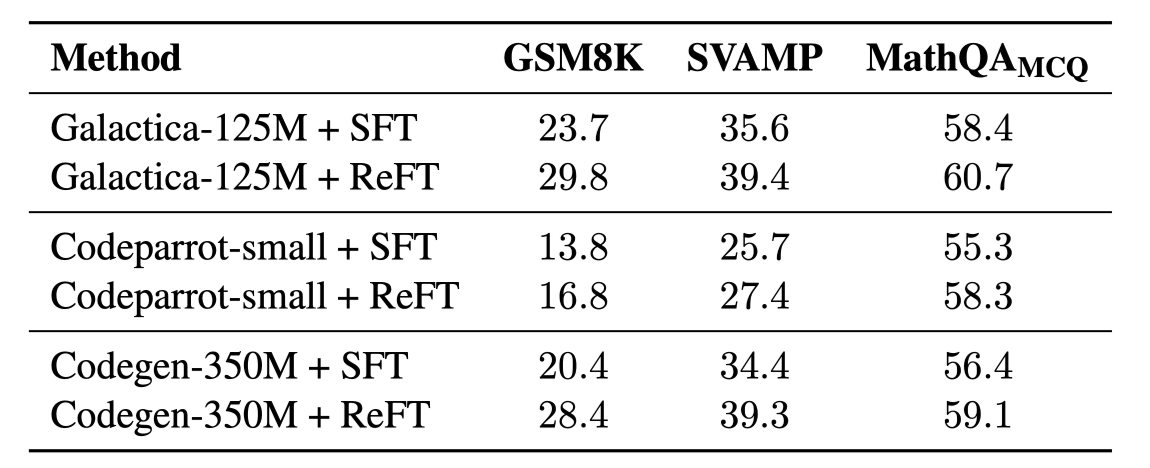
-
작은 모델들에 대해서도 SFT보다 높은 성능 도출이 가능함 확인
- 작은 모델들도 충분한 exploration 능력을 가지고 있음
Ablation Study
-
KL coefficient 를 지우면 LLM의 본래 파라미터에서 멀어져서 학습이 실패
-
별도의 value model을 사용하는 경우 더 빠르게 모델이 수렴하는 것을 확인
- 하지만 추가적인 연산/메모리 사용량 발생

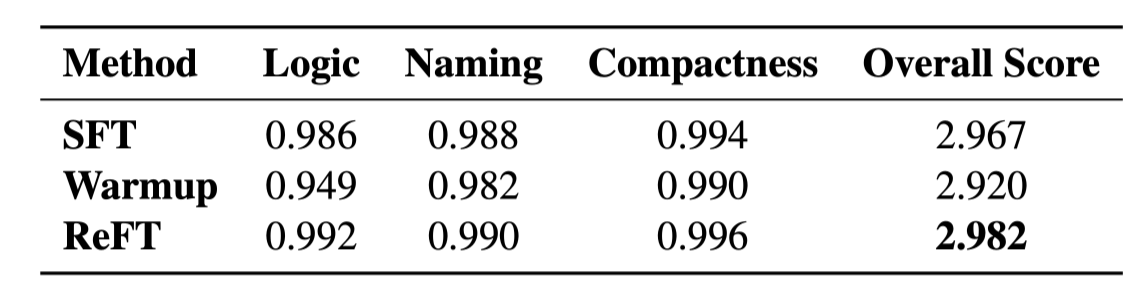
Human Evaluation
-
reasoning의 품질이 얼마나 좋은지 3가지 척도(Logic, Naming, Compactness)로 평가 진행
-
SFT data: 사람이 3가지 척도를 지키도록 만들어진 데이터
- SFT로 학습할 경우 자연스레 human evaluation 결과도 좋아질 수 밖에 없음
-
-
ReFT가 더 나은 모습을 보임
- 모델 스스로 좋은 Reasoning을 만들 수 있음 확인
When ReFT surpasses SFT?
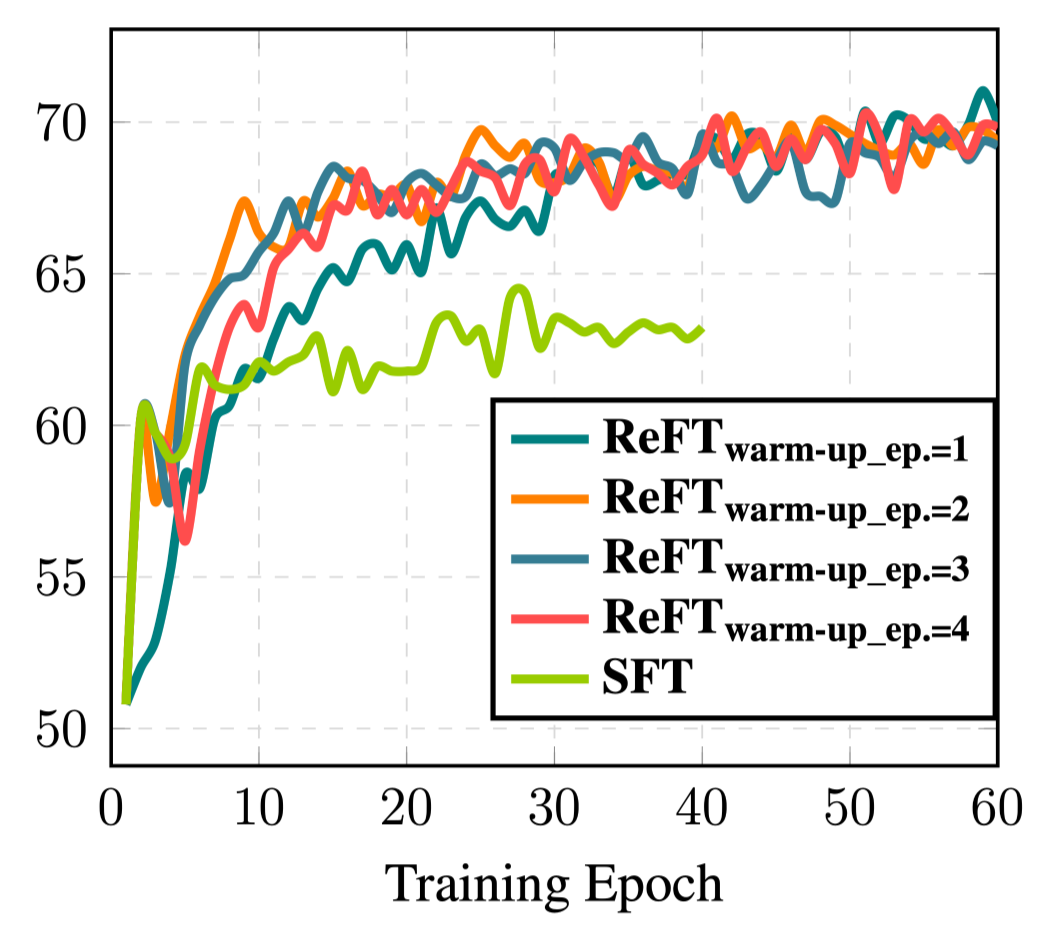
-
SFT warmup step을 달리하며 실험 진행
-
일관된 결과 확인
-
warmup 종료 후 RL stage에서 첫 2 epoch은 오히려 성능 저하 관찰
-
value model의 linear layer가 random init이므로 좋은 value model이 갖추어질 때까지 시간 필요
-
30 epoch 이후 SFT는 성능이 개선되지 않음
-
warmup epoch과 관계없이 ReFT는 비슷한 수준으로 성능이 수렴 and 지속적으로 개선
-
7. Conclusion
-
DeepSeek 등의 최근 연구들이 원본 느낌
-
근데 general domain에서 reward function 어떻게 해요…?
- 최근에는 reward model을 통해 하는듯
reward function 만 정의할 수 있다면, 충분한 gpu가 있다면, SFT보단 RL이 더 좋다!
SFT Memorises, RL Generalizes