Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
논문 정보
- Date: 2025-06-03
- Reviewer: 준원 장
- Property: Reinforcement Learning
1. Introduction
- 대부분의 연구에서 RL 수행 시 전체 파라미터에 대한 full finetuning이 일반적으로 적용된다고 주장한다.
⇒ 해당 연구에서는 RL 기반 full finetuning에서는 실제로 모든 파라미터가 업데이트되는 것일까?에 대한 질문에 대한 해답을 찾아내고자 함
(논문은 findings/conjecture/RQ에 대한 해석을 기준으로 진행이됨)
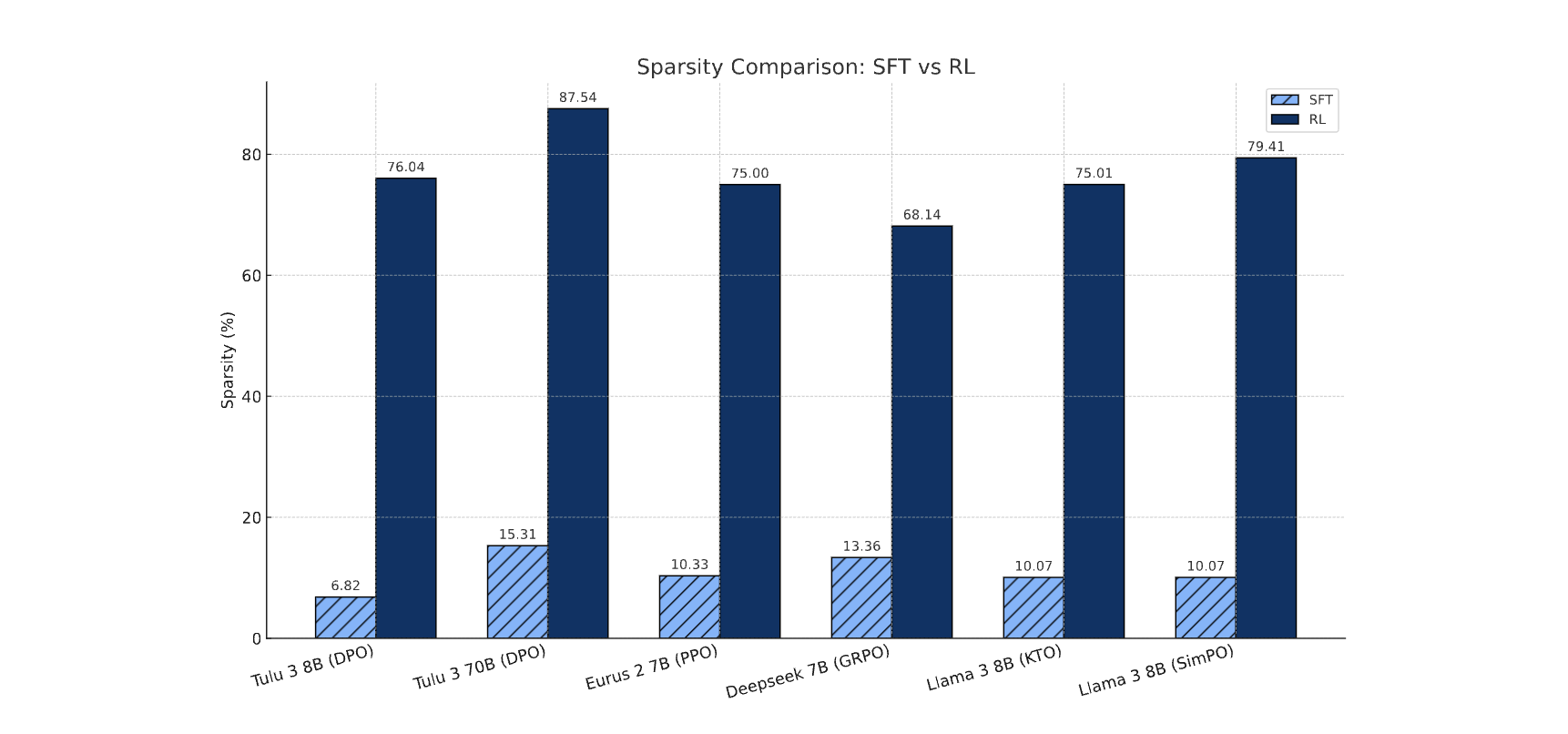
**FINDING **:RL은 pre-trained된 LLM의 소규모 subnetwork만을 업데이트하며, 나머지 대부분의 파라미터는 실질적으로 변화하지 않는다.
→ RL과 SFT단계에서 누적된 그래디언트를 비교한 것으로, RL 단계의 업데이트는 대부분 희소한 반면, SFT 단계에서는 훨씬 밀도 높은 업데이트가 발생했음을 보여준다.
(무작위 시드, 훈련 데이터 구성 및 순서, 그리고 서로 다른 RL 알고리즘에 따라 학습된 서브네트워크들 간에도 강한 일관성이 관찰)
CONJECTURE: RL 학습 종료 시점에서 식별된 나머지 파라미터는 frozen시키고 특정 subnetwork를 finetuning할 경우와, 전체 파라미터를 finetuning 모델과 거의 동일한 성능과 파라미터 값을 갖는 모델을 생성할 수 있다.
-
θ_{init}
-
θ_{full}: parameters after full RL finetuning from the initial model
-
m ∈ {0,1}^{ θ_{init} } -
mi = 1 \rightarrow (θ{init} - θ_{full})_i ≠ 0
- m ⊙ ∇θ L(θ) : θ{full}을 학습했을때와 같은 데이터로 θ{init}때와 똑같이 학습
⇒ **θ{sub} ≈ θ{full}**
VS. LoRA
-
LoRA와 달리 subspace상에서 벡터공간을 학습시키는게 아니라, 적은 수의 파라미터를 업데이트를 하지만 파라미터 행렬이 표현할 수 있는 전체 부분공간에 근접하게 학습된다는 점에서 새로운 발견을 시사한다.
-
인위적으로 추가한 파라미터가 아닌, 자연스럽게 형성된 subnetwork을 finetuning함으로써 전체 모델 수준의 성능을 재현하거나 능가할 수 있음을 보여준다.
⇒ RL은 최적화를 일관되게 활성화되는 소규모 subnetwork에 집중시키며, 나머지 파라미터는 사실상 비활성 상태로 유지된다.
2. Related Work
Lottery Ticket Hypothesis (ICLR, 2019)
-
dense NN 내에 전체 모델의 성능을 단독으로 재현할 수 있는 희소한 subnetwork가 존재함을 주장
-
LLM시대에서는 모델을 재학습하지 않고도 catastrophic forgetting을 완화할 수 있는 task specific subnetwork를 식별 (e.g., ties-merging)
-
사전학습된 언어모델 내 특정 지식을 인코딩하는 데 핵심적인 sparse subnetwork가 존재한다는 것도 실험적으로 밝혀냄
-
해당 ‘winning tickets’를 활용하여 학습 효율을 향상시키려는 시도들도 이루어지고 있음
VS. LTH
-
LTH는 pruning를 통해 ‘winning tickets’을 식별하는 반면, 본 연구는 (학습을 통해) 자연적으로 발생하는 subnetwork에 주목한다.
-
LTH는 최종 모델의 성능이 재현 가능함을 보였지만, 본 연구는 성능뿐 아니라 실질적으로 동일한 파라미터 값을 가진 모델이 복원 가능함을 보여준다.
-
LTH는 초기화 상태에서 학습된 모델을 대상으로 하는 반면, 본 연구는 사전학습된 LLM을 기반으로 finetuning하는 과정에 초점을 맞춘다.
Background
Update Sparsity
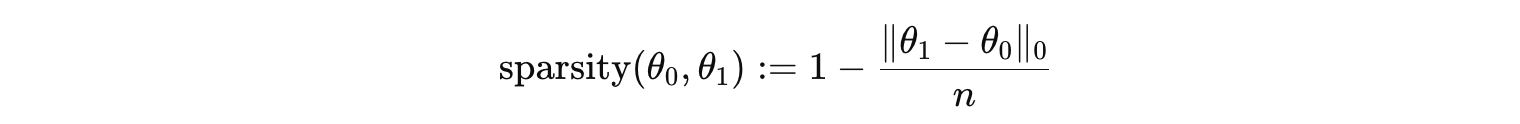
-
θ_{0}: ft 이전의 파라미터
-
θ_{1}: ft 이후의 파라미터
-
\cdot _{0}: non-zero 원소의 개수
_ bfloat16 값이 절대 차이 10⁻⁵ 이하일 경우 동일한 값으로 간주 _
⇒ 파라미터 전후 차이가 거의 없어야 sparsity가 높음
Learning from in-distribution data
-
논문에서 언급하는 ‘in-distribution’은 current policy와 분포가 유사한 data로 학습하는것
-
on-policy RL (PPO, GRPO, and PRIME)은 ‘in-distribution’ 변화하는 policy에서 계속 데이터를 수집함으로 ‘in-distribution’을 보장
-
off-policy RL (DPO, KTO)은 RL에서 사용되는 data로 SFT함으로 ‘in-distribution’이 가능하게 파라미터 분포를 바꿔놓음
-
⇒ 논문에서 SFT가 RL의 update sparsity의 원인임을 규명
KL-divergence regularization and gradient clipping in RL
-
policy model이 reference 모델로부터 과도하게 이탈하는 것을 방지하기 위해 널리 사용되는 두 가지 기법KL Regularization 및 Gradient Clipping
-
둘다 PPO, GRPO, PRIME에 차용되나 Update Sparsity에 미치는 영향은 제한적
3. RL Induces Sparse but Full-rank Updates; SFT Induces Dense Ones
RQ1: RL은 파라미터 업데이트에 어느 정도의 희소성을 유도하며, 이 업데이트는 모델의 어느 위치에서 발생하는가? 그리고 이와 비교하여 SFT는 어떤 양상을 보이는가?
Experiment Setup
-
Hugging Face에서 공개한 다양한 모델에 대해 RL 수행 전후의 Update Sparsity을 정량적으로 측정
-
사전학습 → 지도학습 기반 파인튜닝(SFT) → RL의 3단계 파이프라인을 따르는 LLM의 ‘RL과 SFT’ 단계 분석 (DeepSeek-R1-Zero처럼 사전학습에서 RL로 바로 학습하는 LLM도 포함)
-
Tulu 8B/70B
-
Eurus 7B
-
DeepSeek Math 7B
-
Result
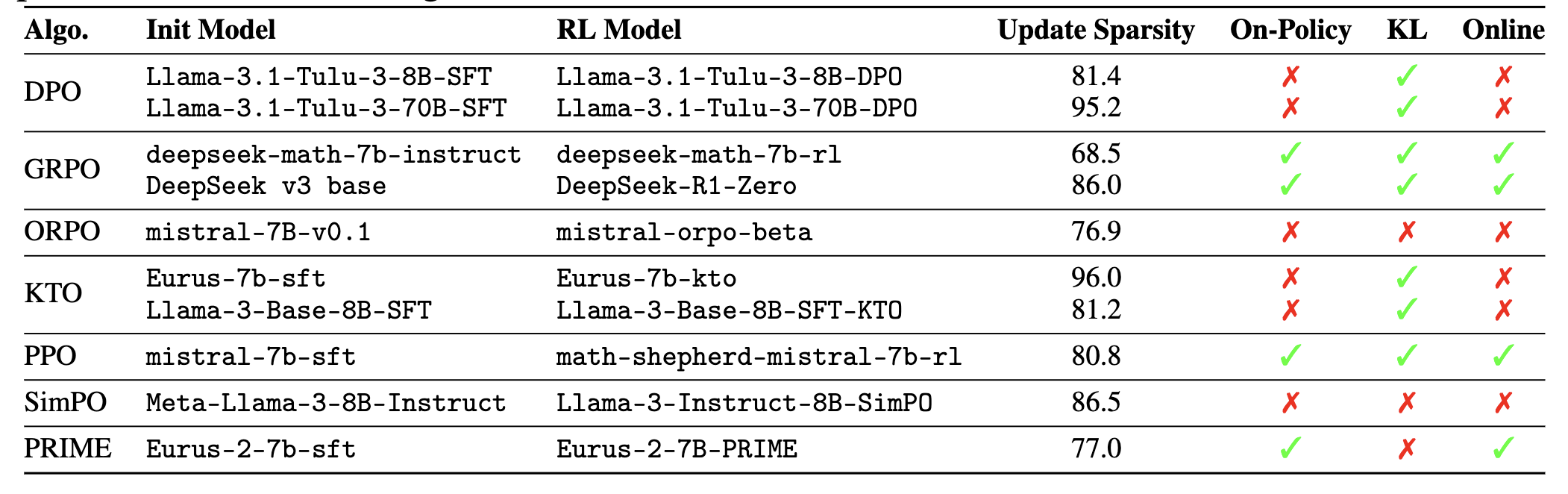
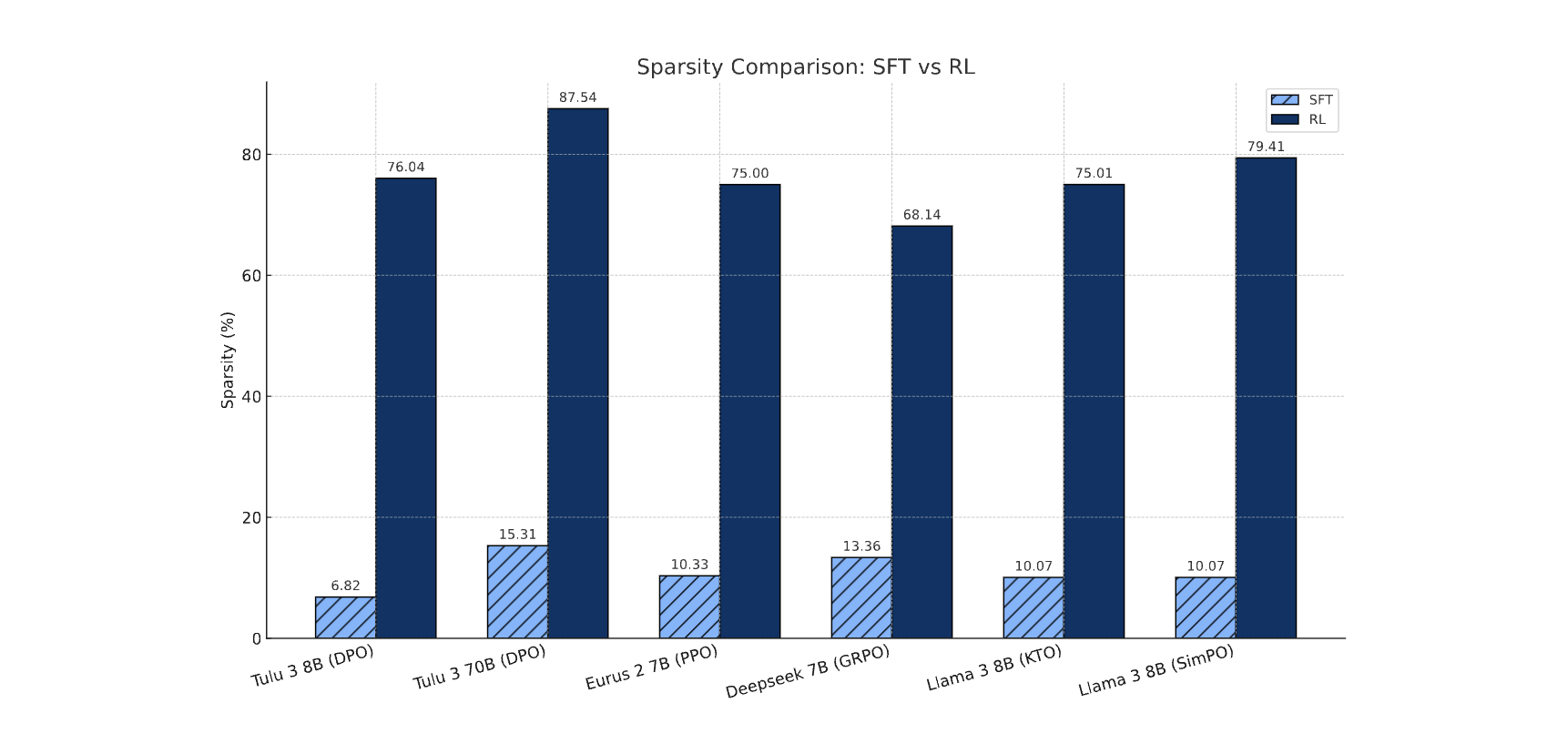
다양한 RL 알고리즘에서의 파라미터 업데이트 희소성
-
모든 모델에 대해 최소 68.5% 이상의 파라미터가 변경되지 않은 채 유지되었으며, 일부 모델에서는 그 비율이 95%를 초과
-
DeepSeek-R1-Zero는 사전학습된 기본 모델로부터 직접 RL(ZERO)만 수행했음에도 불구하고 86.0%의 파라미터가 안바뀜
-
(LLaMA, DS기준) 같은 모델 계열 내에서는 모델 크기가 클수록 희소성이 더 높아지는 경향
-
(accumulated gradients로 측정이 살짝 다르긴 하지만) SFT는 6%-15% sparsity를 보임
-
이전 연구들에서 밝혀낸 바와 동일한 결론에 이름
⇒ RL이 사전학습된 능력을 SFT보다 더 잘 보존한다. 그 이유는 RL이 훨씬 적은 수의 파라미터만을 업데이트하기 때문일 수 있다.
Takeaway-1:
RL은 일관되게 희소한 파라미터 업데이트를 유도한다(대개 70% 이상의 희소성), 반면 SFT는 dense 업데이트를 생성한다. RL 파인튜닝은 LLM에서 희소성이라는 고유한 특성을 나타낸다.
Almost all transformer layers receive similarly sparse updates.
-
대부분의 layer는 유사한 수준의 희소한 업데이트를 받으며, layer normalization layer의 파라미터는 거의 업데이트되지 않는다. (아마 PT때 역할을 완성?)
-
Q, K, V projection 등 다양한 구성요소에 걸쳐 업데이트가 분산되어 있으며, 특정 모듈에 국한되지 않기 때문에 RL로 원하는 모델 행위를 이끌어 내려면 일부 파라미터라도 전체 레이어에 걸쳐 업데이트를 시켜야 함
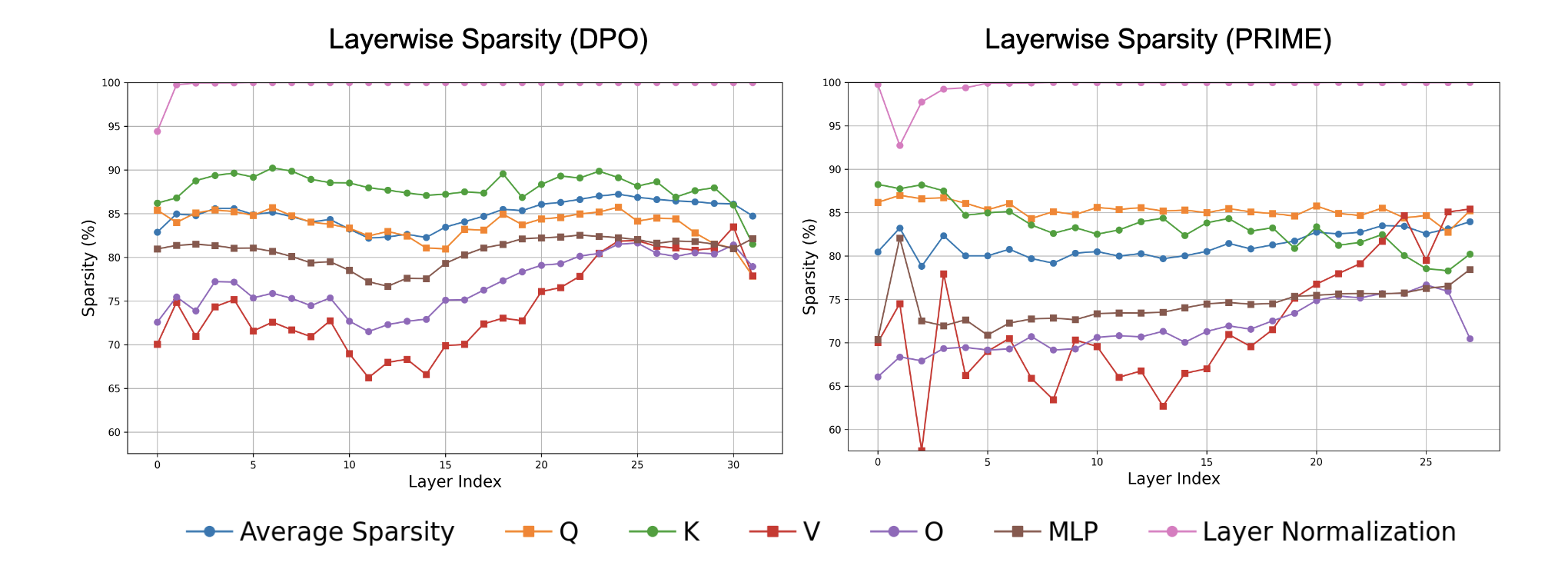
-
위의 실험으로 자연스러운 질문은 이러한 업데이트가 low-rank 인지 여부일텐덴데,
- low-rank는 파라미터 공간의 특정 부분공간(subspace) 내에서만 학습이 이루어졌음을 의미하는 반면, sparse update는 소수의 파라미터가 전체 공간을 거의 포괄함을 의미한다.
-
DPO, PRIME, GRPO 등 다양한 모델에서 각 레이어의 업데이트 행렬 (\Delta \theta)의 평균 rank를 구한결과, 대부분의 업데이트 행렬이 거의 (>99%)를 보이며, 이는 sparse update임에도 업데이트가 모델의 전체 표현력 공간을 거의 포괄한다는 사실을 증명

Takeaway-2:
거의 모든 layer 및 파라미터 행렬은 유사한 수준의 sparse update를 받으며, layer normalization layer만은 예외적으로 거의 업데이트되지 않는다.
4. Finetuning the Subnetwork Alone Can Reproduce the Full-finetuned Model
- RL이 주로 소규모 subnetwork을 finetuning한다는 점에서, 해당 연구는 다음 두 가지 연구 질문에 대해, 기존의 Lottery Ticket Hypothesis을 확장하는 형태로 고찰:
RQ2: subnetwork을 독립적으로 finetuning함으로써, 전체 모델의 성능을 회복할 수 있는가?
RQ3: subnetwork을 finetuning해도 전체 RL finetuning과 동일한 파라미터 값을 재현할 수 있는가? (↔ 유사한 network로 training시킬 수 있는가?)
Experiment Setup
-
θ: Tulu
-
θ_{full}: parameters after full RL finetuning from the initial model
-
θ_{sub}: parameters after subnetwork RL finetuning from the initial model
-
RL
-
DPO (off-policy); evaluation - subset from orig. paper
-
PRIME (on-policy); evaluation - subset from orig. paper
-
Result
-
DPO → θ{full} & θ{sub} : 94.0% 파라미터 동일
-
PRIME → θ{full} & θ{sub} : 90.5% 파라미터 동일
-
허용 오차 기준을 10⁻⁴로 완화할 경우, 두 모델은 100% 동일한 파라미터 값을 가짐
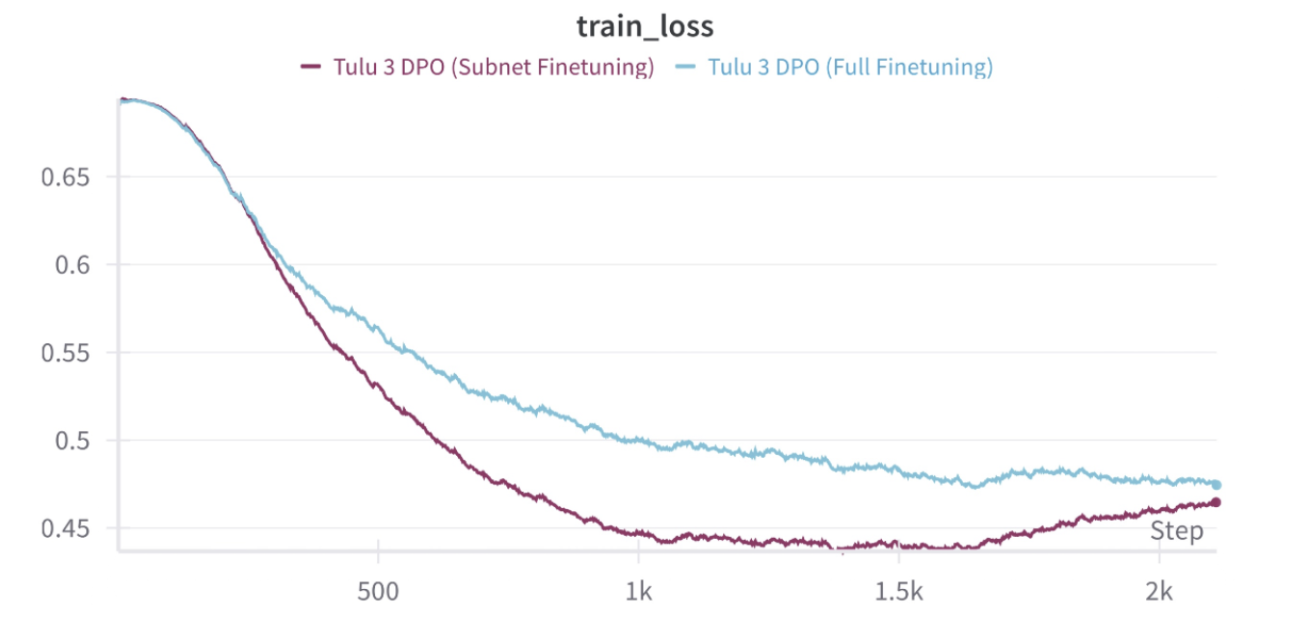
DPO에서 subnetwork만 finetuning한 경우와 전체 finetuning을 수행한 경우의 학습 손실 비교를 보여준다. 서브네트워크만 학습한 경우, 일관되게 더 낮은 학습 손실을 기록
θ_{sub}**는 모든 task에서 **θ_{full}**과 동등하거나 더 우수한 성능을 보임.** 이는 subnetwork외 파라미터가 최적화 과정에서 거의 기여하지 않으며, 오히려 고정함으로써 성능이 개선될 여지도 있음을 시사.
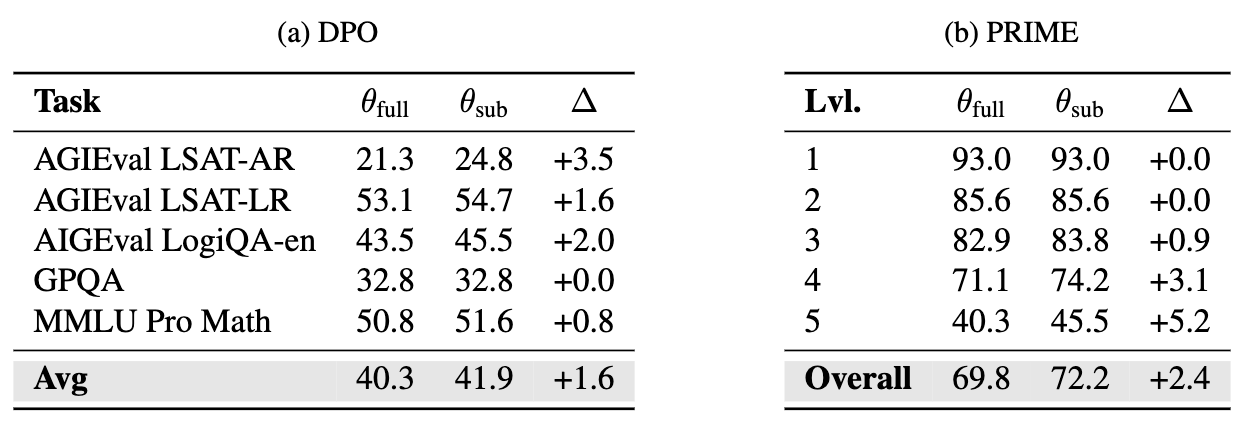
⇒ 논문 서두에서 언급한 conjecture를 실험적으로 완벽하게 증명하며, RL 훈련에서의 sparse update을 명시적으로 활용한 효율적인 학습 전략에 대한 가능성을 열어둠.
(post hoc으로 찾아낸 sparse parameter를 미리 알아내는건 future work!)
5. Consistency of Subnetworks Across Seeds, Data, and Algorithms
RQ4: RL으로 업데이트된 subnetwork는 무작위 시드, 학습 데이터, RL 알고리즘 등 학습 조건이 달라질 경우에도 일관성을 유지하는가?
⇒ subnetwork가 일관성 있는 결과를 보인다면, 해당 subnetwork가 특정 학습 조건에 의한 우연의 결과가 아니라, 사전학습 모델에 내재된 일반화 가능하고 RL로 transfer 가능한 구조임을 시사
Experiment Setup
-
I_1, I_2: 업데이트된 파라미터의 인덱스 집합
-
o_1=\frac{∣I_1 \cap I_2∣}{∣I_1∣}=\frac{∣I_1 \cap I_2∣}{1-s_1}: I_1의 업데이트된 파라미터 중에서, I_2도 함께 업데이트한 비율
-
o_2=\frac{∣I_1 \cap I_2∣}{∣I_2∣}=\frac{∣I_1 \cap I_2∣}{1-s_2}: I_2의 업데이트된 파라미터 중에서, I_1도 함께 업데이트한 비율
-
Tulu-3-8B, Enrus-2-7B-SFT 사용
⇒ RL에서 학습된 모델들이 어떤 특정 파라미터만 반복적으로 업데이트한다면, 일종의 구조적 sparsity를 가진 중요한 subnetwork이 존재한다는 것
(이를 무작위로 동일 수의 파라미터를 선택하는 경우의 랜덤 베이스라인도 포함해서 비교)
- random guessing baseline
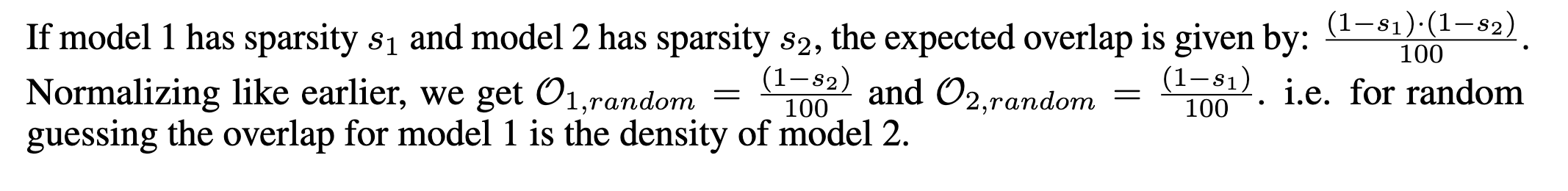
**Result **
-
seed만 변화
-
training data만 변화
-
**seed, training data, RL algorithm 모두 변화 (stress test) **
→ seed, data, RL이 서로 달라졌음에도 불구하고, subnetwork는 무작위 baseline을 상회하는 유의미한 중첩도를 보인다.
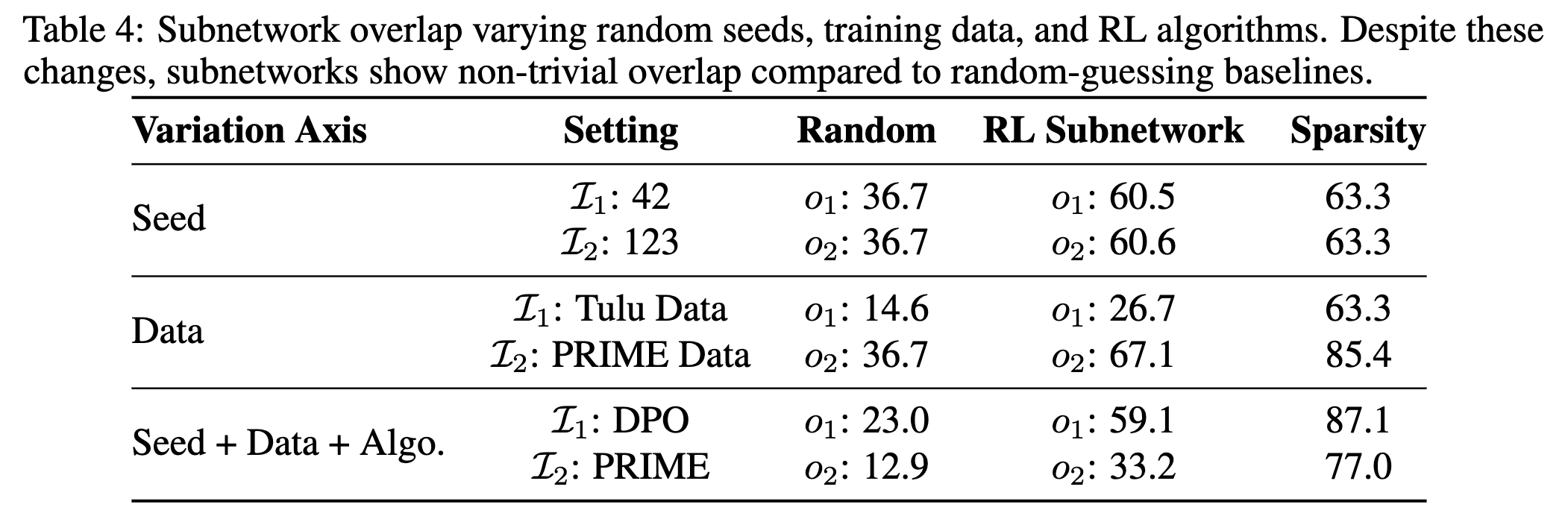
Takeaway-3:
동일한 사전학습 모델에 대해, seed, data, RL 알고리즘이 서로 다른 경우에도, RL로 학습된 subnetwork는 무작위 추정보다 훨씬 높은 중첩도를 보인다. 이는 다양한 훈련 조건에 걸쳐 일관적이고 부분적으로 전이 가능한 subnetwork 구조가 (적어도 transformer에서는) 존재함을 시사한다.
* overlap이 100%에 도달하지는 않았으나, partial reuse만으로도 충분히 실용적 이점을 제공. 예를 들어, **하이퍼파라미터 탐색이나 ablation 연구와 같이 반복적으로 수행되는 RL 학습 과정 (실제로 optimal 조합찾는데 대부분의 시간이 소요)에서, 이전 실험에서 도출된 subnetwork의 일부를 재사용함으로써 중복 계산을 줄일 수 있음. 또한, DPO와 같은 계산 비용이 적은 알고리즘으로 subnetwork를 도출한 뒤, 이를 PPO와 같은 고비용 알고리즘에 전이하여 사용할 경우, 성능을 손상시키지 않으면서 학습 비용을 대폭 절감할 수 있다. ***
6. Why Do the Subnetworks Emerge?
RQ5: RL finetuning에서 관찰된 파라미터 update sparsity는 어떤 요인으로 인해 발생하는가?
- 논문에서는 4가지 요인을 중점적으로 분석
-
gradient clipping
-
reference policy에 대한 KL regularization
-
RL 이전 SFT 수행의 유무
-
총 RL 업데이트 스텝 수
⇒ 결론부터 말하면, update sparsity의 가장 지배적인 요인은 학습 데이터 분포가 current policy와 얼마나 유사한지이다.
-
Gradient clipping and KL regularization
-
위 두 기법은 기본적으로 policy 모델이 reference 모델로부터 지나치게 벗어나는 것을 방지하기 위한 보편적인 기법. 다시 말해, 명시적으로 큰 파라미터 업데이트를 억제하므로, RL에서 관찰된 업데이트 희소성의 원인일 수 있다.
-
Qwen-2.5-7B-Instruct에 GRPO variant를 적용한 결과
- (w/ KL) 69.8% vs. 68.8% (w/o KL)
-
-
Performing SFT before RL
- SFT를 전혀 수행하지 않은 DeepSeek-R1-Zero와 같은 모델에서도 높은 update sparsity이 관찰
⇒ (표본이 적긴하지만) SFT의 유무와는 무관하다는 적은 근거를 제시
-
Training duration
-
그래디언트 스텝이 많아질수록, 모델은 초기 상태로부터 더 멀어질 것으로 기대됨
-
PRIME의 경우 학습이 진행됨에 따라 sparsity은 점진적으로 감소하지만, 약 80% 수준에서 수렴
-
(DeepSeek-R1-Zero는 GRPO를 사용하여 8천 스텝에 이르는 학습을 수행하였음에도 비슷한 수치인 86.0%의 높은 sparsity 유지)
⇒ 초기 단계에서는 학습량이 sparsity에 큰 영향을 미치지만, 학습이 진행될수록 그 영향은 점차 감소
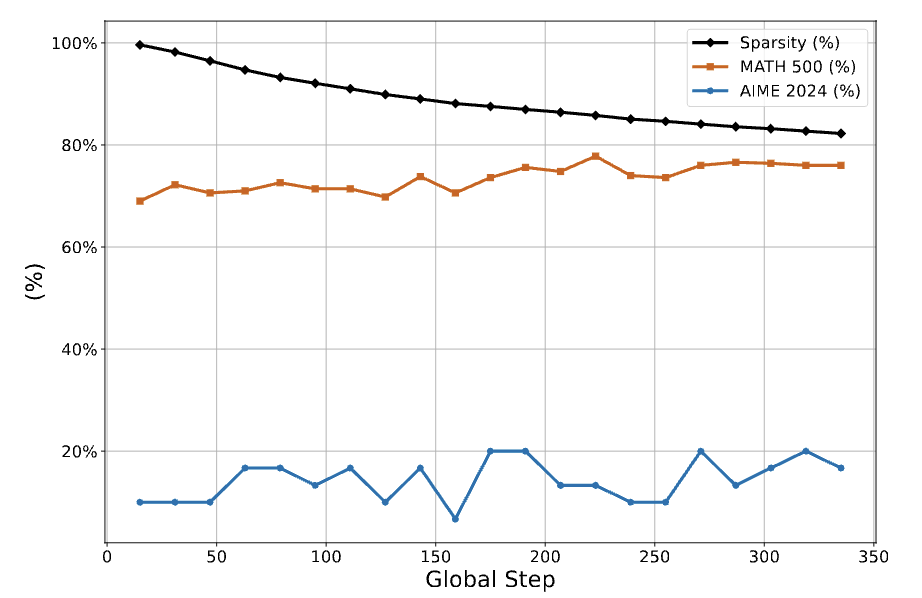
- 학습 초기에는 파이널 subnetwork 외부의 파라미터도 일부 업데이트되나, 시간이 지나면서 대부분 사라짐
⇒ (실험했던 PRIME이겠지?) 최종적으로 전체 파라미터 중 약 8.5%가 학습 중 일시적으로 업데이트되었으나 최종 subnetwork 포함 X (+ grad → -grad → no change weight)
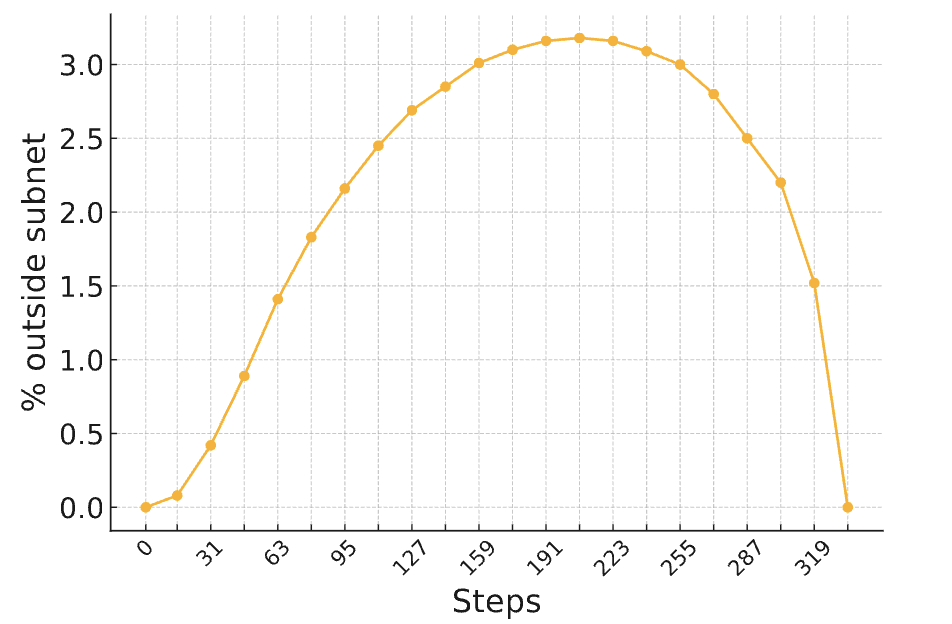
⇒ 이렇게 학습을 했는데도 undertraining된거 아니냐!라고 주장할 수 있지만, 기본적인 RL골자가 과적합을 방지하고 일반화 성능을 향상시키는거라 함부로 논의를 꺼낼 수 없다는 입장
- Training on in-distribution data
직관적으로, policy가 이미 높은 확률을 부여하는 sequence에 대해 그래디언트가 계산되면, 파라미터에 대한 변화가 거의 필요 없다.
-
rejection sampling을 통해 생성된 in-distribution 데이터에 대한 SFT
- section03에서 SFT data는 out-of-distribution이었는데 강제로 in-distribution으로 맞춰줌
-
SFT 없이 out-of-distribution 데이터에 대해 수행된 DPO
- SFT없이 DPO하면 out-of-distribution
_ 학습방법론이 아닌 데이터 분포 차이에 의해서 sparsity가 발현되는지 검증하기 위함 _
In-Distribution vs Out-of-Distribution
in-distribution 데이터에서의 SFT는 sparse update를 생성하며, 반대로 out-of-distribution 데이터에서의 DPO는 dense update를 생성
-
Qwen2.5-Math-7B에서 rejection sampling 기반 in-distribution 데이터로 수행한 SFT(RFT)는 약 91.2%의 sparsity, RAFT++는 69.4%.
-
out-of-distribution 데이터에서 수행된 DPO는 Zephyr-7B-Beta는 **7.7% **dense update
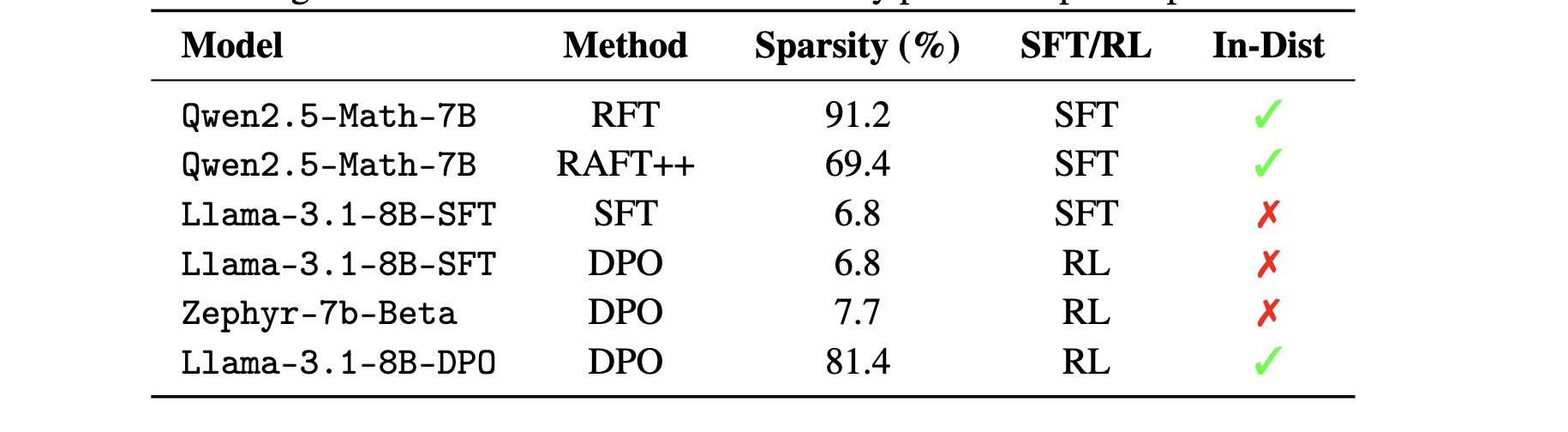
Takeaway-4:
policy와 in-distribution된 데이터에 대한 학습은 파라미터 sparse update의 주요 원인이다. 반면, KL regularization 및 gradient clipping은 그 영향이 제한적이다.
5. Limitation & Conclusion
- 단일변수를 통일해서 실험했기에, 복합적인 상호작용에 효과를 조사해보진 않음
(공개된 체크포인트를 활용, 적은 표본으로 실험한 것도 마찬가지)
-
subnetwork 조기식별, 이를 바탕으로 RL 학습효율제고가 좋은 연구 방향
-
RL시 regularization or structural constraints없이 자연적으로 발생하는 내재된 특성 발견