Scaling Reasoning, Losing Control: Evaluating Instruction Following in Large Reasoning Models
논문 정보
- Date: 2025-07-15
- Reviewer: 전민진
Abstract
-
최근의 reasoning oriented model(LRM)은 여러 수학 데이터셋에서 높은 성능 달성을 보이나, natural instruction following에 대한 성능은 분석되지 않음
-
본 논문에서는 이러한 LRM들의 instruction following 능력을 분석하기 위해 MathIF라는 데이터셋을 제안, math 도메인에서의 instruction following 성능을 평가
-
실험 결과, reasoning을 효과적으로 하는 모델이 user direction에 따르는 것을 어려워 하는 현상 발견
-
긴 CoT dataset에 SFT하거나 RL로 학습한 모델이 답변 길이가 길어질수록 instruction following 능력이 떨어지는 현상 발견
-
간단한 개입(CoT 마지막 부분에 instruction을 다시 붙여서 넣어줌)으로 instruction following 성능을 향상시킬 수 있음을 보임
-
Introduction
-
CoT reasoning을 scaling하는 것은 reasoning ability를 향상시킴
- SFT or RLVR 사용
-
LRM의 경우 간단한 instruction도 following하는 것을 어려워 한다는 것을 발견
⇒ reasoning-oriented learning을 하면 모델 자체의 reasoning ability는 향상돼도 controllability는 떨어지는게 아닐까?
- 하지만 현재는 범용 목적의 instruction following(IF) 벤치마크만 존재
⇒ 수학 도메인에서의 IF 벤치마크를 만들고 평가해보자!
-
실험 결과, instruction following과 reasoning capability사이의 일종의 trade-off가 존재
-
즉, SFT 혹은 RL로 reasoning ability를 향상시킨 모델은 reasoning 성능은 올라도 IF 성능은 떨어짐
-
특히, CoT 길이가 길어질수록 IF 성능이 악화됨
-
-
contribution
-
MathIF, 첫번째로 수학 도메인에서 instruction following 능력을 시스템적으로 측정하는 벤치마크 데이터셋 도입
-
23개의 LRM를 해당 벤치마크에 대해서 평가
-
reasoning performance와 instruction-following사이의 trade-off가 있음을 실험적으로 보임
-
Related Work
-
LRM
-
high-quality long CoT by distilling from more capable LRMs or combining primitive reasoning actions
-
s1 : 적은 양의 CoT data로도 reasoning ability를 향상시킴
-
LIMO : 관련 도메인이 이미 pre-training때 포함되어 있다면, 최소한의 cognitive process를 담은 demonstration으로 reasoning capabilities를 발생시킬 수 있다고 서술
-
-
cold-RL
-
deepseek-R1-zero로 주목 받게 된 방법론
-
SFT와 달리, cold-RL은 긴 CoT dataset에 의존하지 않고, final outcome으로 reward를 받아서 학습
-
RL과정을 간단, 가속화 하기 위해서 dynamic sampling, process-reward, off-policy guidance, CoT preference optimziation 등이 제안됨
-
-
-
Instruction-followiwng benchmark
-
이전의 벤치마크는 보통 user query의 completeness에 초점, proprietary language model에 의존해서 win rate를 측정하는 식으로 평가
-
format constraint, multi-turn instruction, refutation instruction, compositional instruction을 따르는지를 평가
-
하지만 대부분의 IF 벤치마크는 일반적인 도메인에 집중, 상대적으로 직관적인 query를 사용
-
→ 이러한 도메인 차이와 long CoT의 부재는 LRM을 평가하는데에 방해가 됨
MathIF
-
Overview
- toy experiment로 IFEval과 FollowBench에 대한 LRM과 Instruct 모델 성능 비교
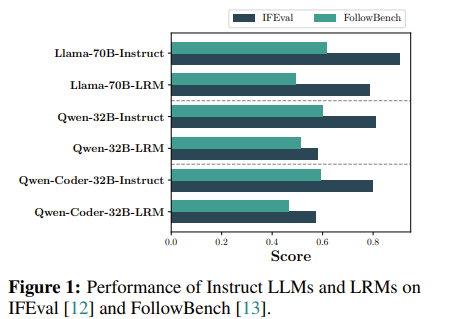
- 확실히 LRM의 성능이 상대적으로 낮으나, 낮은 원인이 domain shift때문인지 IF성능 때문인지는 분명하지 않음
⇒ 수학 도메인의 IF benchmark를 만들자!
- python으로 검증 가능한 constraint를 고려, 2-3개의 constraint를 합쳐서 instruction으로 부여하는 방안을 고려
- contraint를 얼마나 만족했는지를 평가하기 위해 Hard accuracy(HAcc), Soft accruacy(SAcc)로 측정
-
Constraint type
-
length, lexical, format, affix로 크게 4가지 type으로 분류, 그 안에 sub-type을 명시
-
proprietary language model에 의존하지 않기 위해서 python으로 제약을 만족했는지 검증 가능하도록 설계
-


-
Compositional Constraint
-
2-3개의 constraint를 조합해서 compositional constraint를 구축
-
같이 존재할 수 없는 constraint나 같은 subtype끼리 있으면 filtering, 그 외의 조합에서 random sampling해서 데이터셋을 구축
-
이러한 과정을 통해 30개의 dual-constraint와 15개의 triple-constraint를 구축
-
-
Math problem collection
-
GSM8K, MATH-500, Minerva, Olympiad에서 90개씩 sampling
- 초등학교부터 올림피아드 수준의 문제까지 아우르도록 함
-
각 데이터에 대해서 single, dual, triple constraint를 적용
-
sanity check를 위해 사람이 직접 검수, math problem에 추가된 constraint가 모순되지 않는지 더블췍
-

-
Evaluation metric
-
HAcc : constraint다 만족해야 1
-
SAcc : contraint 개당 만족하면 1 아니면 0으로 계산, 평균
-
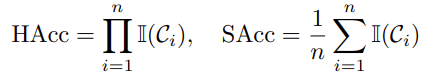
- 구체적인 언급 없으면 correctness는 contraint가 있는 상태에서 나온 답변으로 계산
Experiment
- 모든 LRM은 nucleus sampling(T=1.0, p=0.95)로 디코딩, 최대 답변 길이 16,384 토큰, vLLM 사용
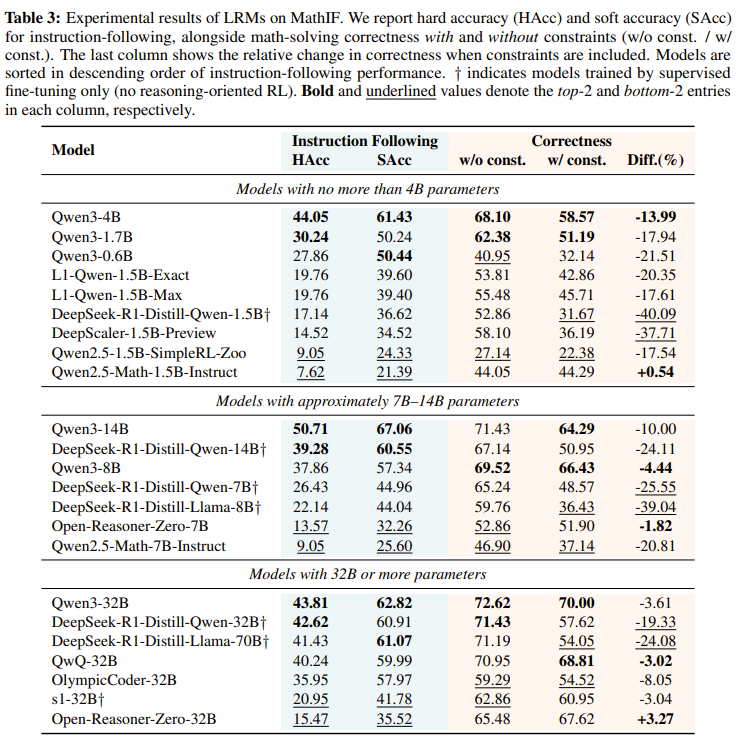
-
모든 LRM은 IF성능이 하락함
-
최고 성능을 낸 Qwen3-14B마저도 50.71밖에 안됨
-
특히 deepseek-R1-distill-llama-70B나 open-reasonser-zero-32B의 경우 모델 크기에 비해서 매우 낮은 IF 성능을 보임
-
-
Qwen3 시리즈가 그나마 높은 IF 성능을 보임
-
모델 크기가 IF 성능을 결정하진 않음
- 같은 계열에서는 종종 경향성이 있으나, 다른 계열까지 한번에 봤을 때는 크기가 크다고 IF 성능이 보장되진 않음
-
명시적인 reasoning seperation (
, )가 있는 모델이 전반적으로 IF 성능이 높음- Qwen2.5-Math-1.5B, 7B-Instruct, Qwen2.5-1.5B, 7B-SimpleRL-Zoo 친구들이 명시적인 reasoning token 없는 애들 ⇒ 성능이 쏘 처참
-
instruction-following과 mathematical reasoning사이에 trade-off가 존재
- Diff를 보면 대부분의 모델이 constraint가 있을 때와 없을 때의 correctness차이가 큼
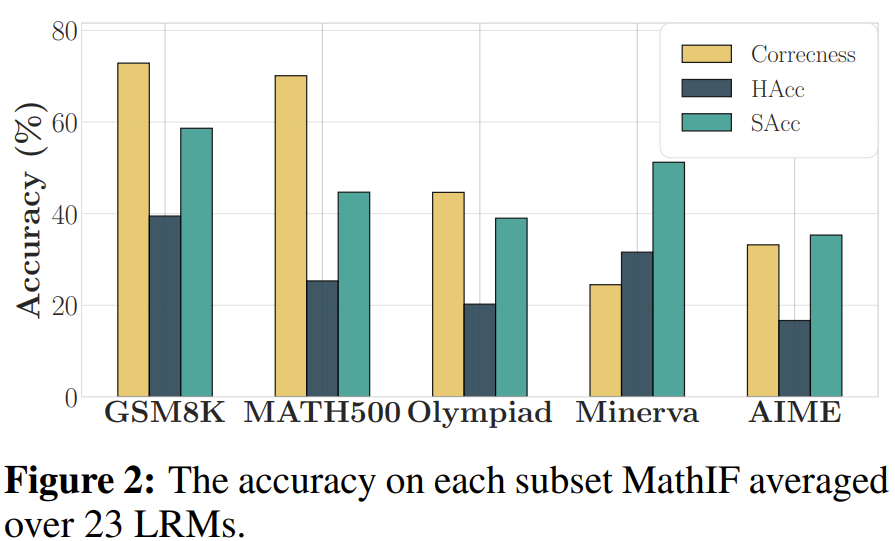
-
LRM모델이 constraint를 잘 따르는게 문제 난이도와 연관이 있는지를 살펴보기 위해 데이터셋 별로 IF성능을 표현
-
문제가 어려울수록 constraint를 잘 만족하지 못한다는 것을 알 수 있음
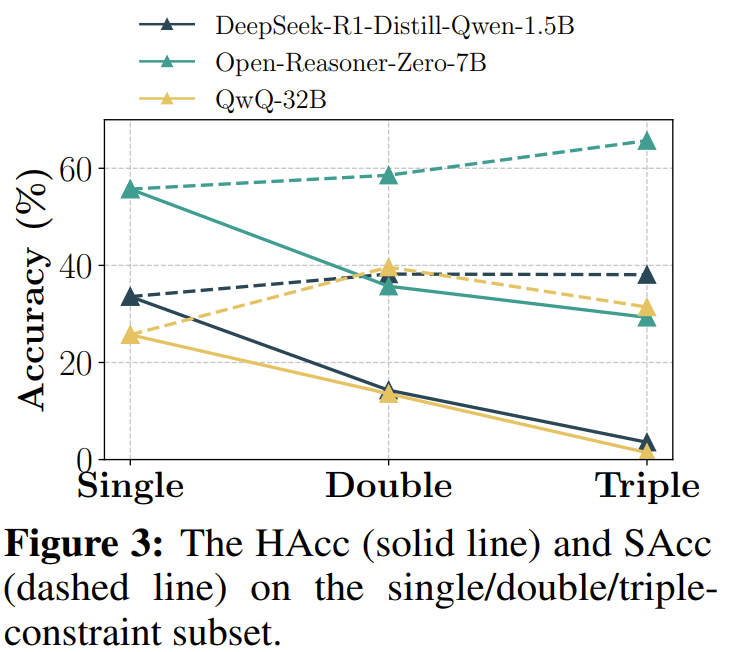
- 제약이 많아질수록 IF 성능 하락, 특히 2개이상부터 크게 하락..
-
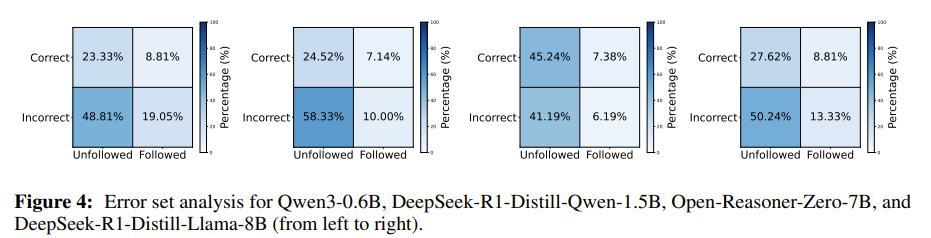
제약조건을 만족하면서 문제를 맞추는 경우는 크지 않음
-
보통 제약조건 혹은 문제 하나만을 만족함 + 즉, 제약조건을 걸면 문제 풀이 성능이 하락
-
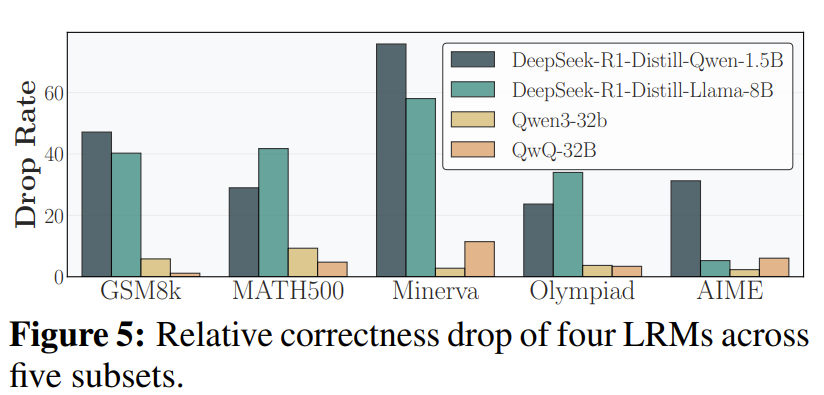
constraint가 있을 때와 없을 때의 성능 차이
-
특히, GSM8K, Minerva에서 극심 ⇒ 문제 난이도와 상관 없이 contraint가 있으면 reasoning ability가 하락
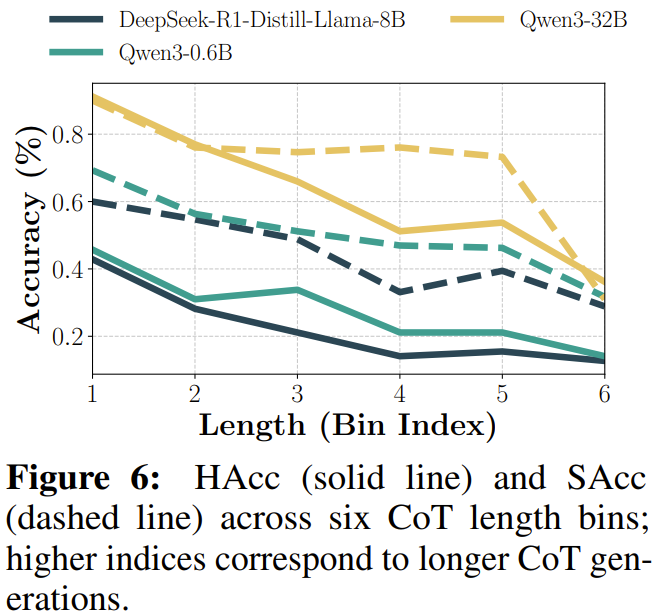
- CoT가 길수록 IF 성능 하락
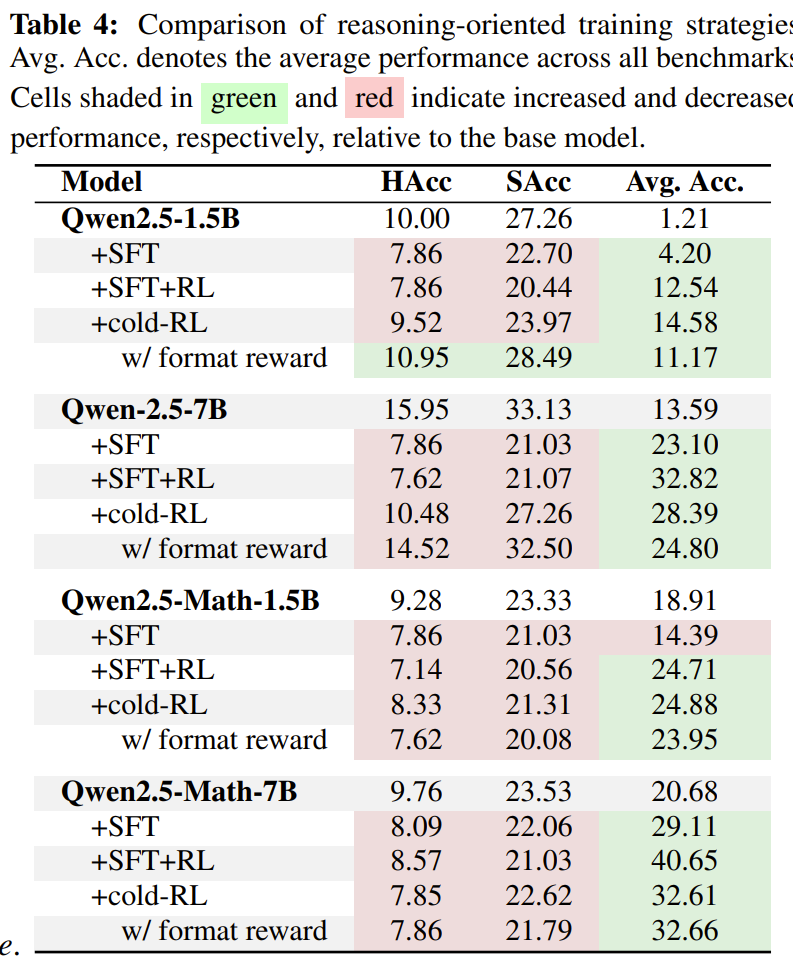
-
IF가 낮았던 Qwen2.5를 대상으로 실험, 데이터는 deepscalar를 사용, QwQ로 CoT생성, 정답을 맞추면서 너무 길지 않은 애들만 필터링해서 학습에 사용
- format reward는 think token를 포함하는지 여부로 포함하면 답이 틀려도 0.1점 줌
-
실험 결과, reasoning-orienteed 방법론이 reasoning성능은 향상시키지만 IF는 하락하는 것을 볼 수 있음
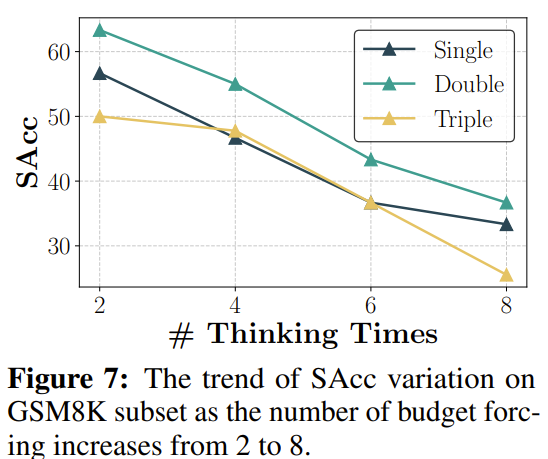
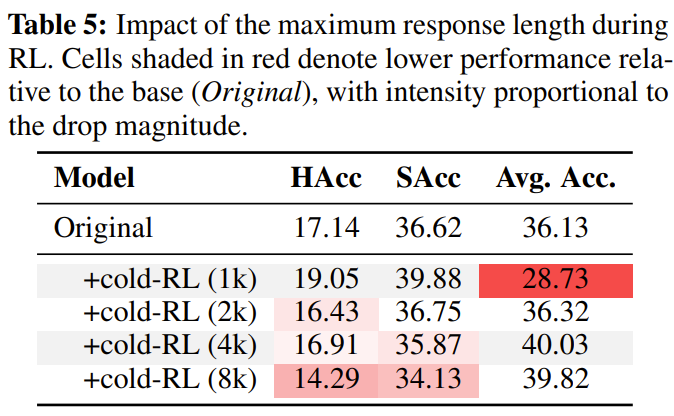
Figure 7
-
모델이 reasonign path를 종료하려고 할 때마다 wait를 걸어서 강제로 CoT길이를 늘림
-
CoT길이가 길어질수록 constraint instruction과 멀어져서 constraint에 대한 acc가 떨어지는 것으로 추론
Table 5
- cold-RL에서 roll-out 길이를 조정하며 학습, 길어질수록 reasoning은 향상되나 IF는 떨어짐
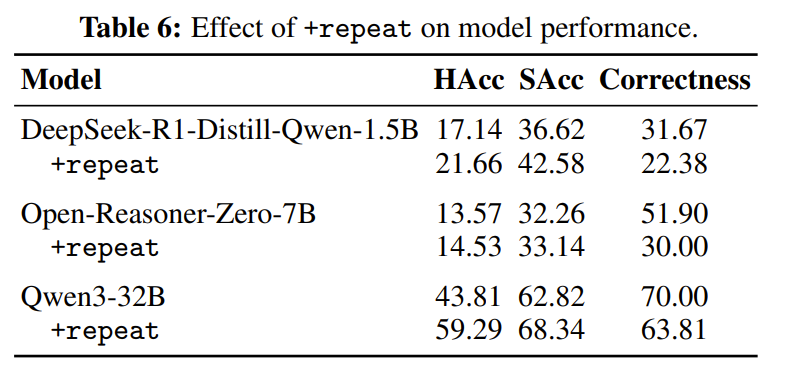
-
간단하게 reasoning이 끝나갈 때 쯤에 wait을 넣고 constraint instruction을 반복해서 넣어준 경우의 성능을 측정
-
IF성능은 향상되나 Correctness는 하락하는 것을 볼 수 있음
Conclusion
-
Reasoning-oriented model들이 생각보다 instruction following 성능이 악화됨
-
대부분 간단한 형식에 대한 제약인데도, 제약이 있을 때와 없을 때의 성능 차이가 큰게 충격적
-
LLM이 정말 reasoning을 하는걸까? 그냥 답변 길이가 길어져서 발생하는 attention sink일까?