Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
논문 정보
- Date: 2025-07-15
- Reviewer: 건우 김
- Property: Reinforcement Learning

Abstract
- Reasoning과 text generation이 가능한 LLM에게 external knowledge와 최신 information을 효율적으로 삽입하는 것은 매우 중요함
→ 하지만 기존 advanced reasoning ability를 가진 LLM에게 prompt 기반의 search engine을 활용하도록 하는 것은 suboptimal임 (LLM이 search engine과 어떻게 상호작용해야 하는지 완전히 이해 못함)
-
이 문제를 해결하기 위해 RL을 활용한 reasoning framework인 Search-R1을 소개함
- 단계별 reasoning step에서 autonomously하게 multiple search queries를 생성하고 실시간으로 정보를 검색하도록 학습
1. Introduction
LLM은 natural language understanding과 generation에서 높은 성과를 보여줬지만, 여전히 external sources가 필요한 task에서 한계점을 보여줌.
→ 즉, 최신 information을 잘 활용할 수 있도록 search engine과 효과적으로 상호작용하는 능력이 필수적임
최근까지 LLM과 Search Engine을 결합하는 대표적인 방식은 두가지
-
Retrieval-Augmented Generation (RAG)
-
search engine을 하나의 tool로 활용하는 방식
위 방법 덕분에 LLM이 external knowledge를 활용할 수 있긴 하지만, 최근 연구 (multi-turn, multi-query retrieval) 역시 본질적으로 **LLM이 search engine과 상호작용하는 방식을 최적화하지 못한 채 prompt에만 의존하는 한계점이 존재함. **
다른 방법으로 LLM이 추론 과정에서 search engine을 포함한 여러 tool을 사용하도록 prompting하거나 training하는 방법들이 있지만
-
prompting 방법 역시 LLM의 pre-training 단계에서 경험하지 못한 작업에 generalize가 잘 안되는 문제
-
training 기반 방식은 더 나은 adaptability를 보이지만 대규모 high quality annotated trajectories가 필요하고 search 연산이 미분이 불가능하기 때문에 end-to-end gradient descent로 최적화하기 어려움
한편으로 RL은 LLM의 reasoning capability를 높이는 robust 방법으로 최근에 주목 받는데, 이것을 **search-and-reasoning **scenarios에 적용하는 데는 3가지 문제가 있음
-
RL framework and Stability: search engine을 어떻게 RL에 효과적으로 통합할지, 특히 검색된 context를 포함할 때 안정적인 최적화를 어떻게 보장할지 명확하지 않음
-
Multi-Turn Interleaved Reasoning and Search: 이상적으로는 LLM이 반복적으로 추론하고 search engine을 호출하며 문제의 난이도에 따라 검색 전략을 동적으로 조정할 수 있어야 함
-
Reward Design: Search와 Reasoning tasks에 의미 있고 일관된 검색 행동을 학습하게끔 유도할 수 있는 효과적인 reward function 설계가 필요하지만, 단순한 결과 기반 보상이 충분한지는 아직 불확실함.
→ 3번은 자기들도 모르면서 뭔가 싶네요 ㅋㅋ
→ 이러한 문제를 해결하기 위해 Search-R1을 소개함. 이것은 LLM이 자체 추론 과정과 search engine을 interleaved하게 연계하여 사용할 수 있도록 설계가 됨.
주요 특징은 다음과 같음
-
Search engine을 environment의 일부로 modeling하여, LLM의 token 생성과 검색 결과 호출이 혼합된 trajectory를 샘플링할 수 있음.
-
Multi-turn retrieval과 reasoning을 지원함.
와 token으로 검색 호출을 트리거하고, 검색 결과는와 토큰으로, LLM의 추론 단계는와 토큰으로, 최종 답변은와 토큰으로 감싸 구조적이고 반복적인 의사결정이 가능함 -
process-based rewards 대신 단순한 outcome-based reward function을 적용하여 복잡성을 줄임
2. Related Works
2.1 Large Language Models and Retrieval
(생략)
2.2 Large Language Models and Reinforcement Learning
(생략)
3. Search-R1
(1) extending RL to utilize search engines
(2) text generation with an interleaved multi-turn search engine call
(3) the training template
(4) reward model design
3.1 Reinforcement Learning with a Search Engine
Search-R1은 search engine R을 활용하는 RL의 objective function을 아래와 같이 정의함
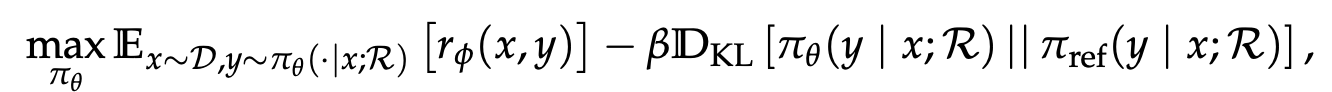
-
r_{\phi}: output quality를 평가하는 reward function
-
\pi_\theta: policy LLM
-
\pi_{ref}: reference LLM
-
x: dataset D에서 추출된 input sample
-
y: search engine calling 결과와 interleaved된 generated outputs
-
D_{KL}: KL-divergence
기존 RL은 원래 \pi_\theta가 생성한 sequence만 학습하지만, Search-R1은 검색 호출과 추론이 교차된 (interleaved) 형태를 학습에 explicit하게 포함함.
-
retrieval interleaved reasoning via \pi*{\theta}(. x;R) =\pi*{ref}(. x)\bigotimes R - \bigotimes denotes interleaved retrieval-and-reasoning
즉, 추론 중 검색 결과를 반영하는 흐름을 통해 external information가 필요한 reasoning-intensive tasks에서도 더 효과적인 결정을 내릴 수 있게 해줌
- **Formulation of RL with a Search Engine**
LLM에서 자주 사용하는 원래 기존 RL의 objective는 아래와 같이 정의됨
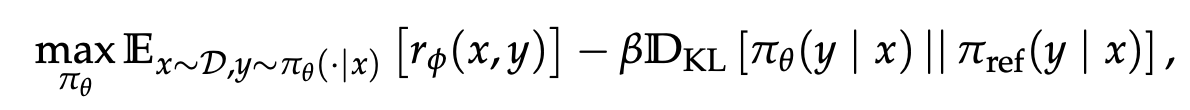
그런데, 위 formulation은 entire output sequence y가 \pi_{\theta}로부터 생성되었다는 가정이 있음. 이 가정은 model behavior가 internal reasoning과 external information retrieval을 모두 포함하는 상황에서 적용할 수 없음.
따라서, RL objective를 serach engine R과 통합시키기 위해 아래와 같이 수정함
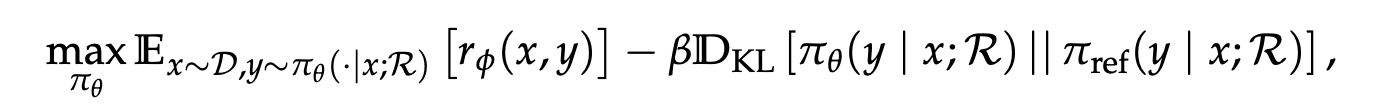
위 수정된 objective에서는 trajectory y 는 interleaved reasoning steps과 retrieved content를 포함
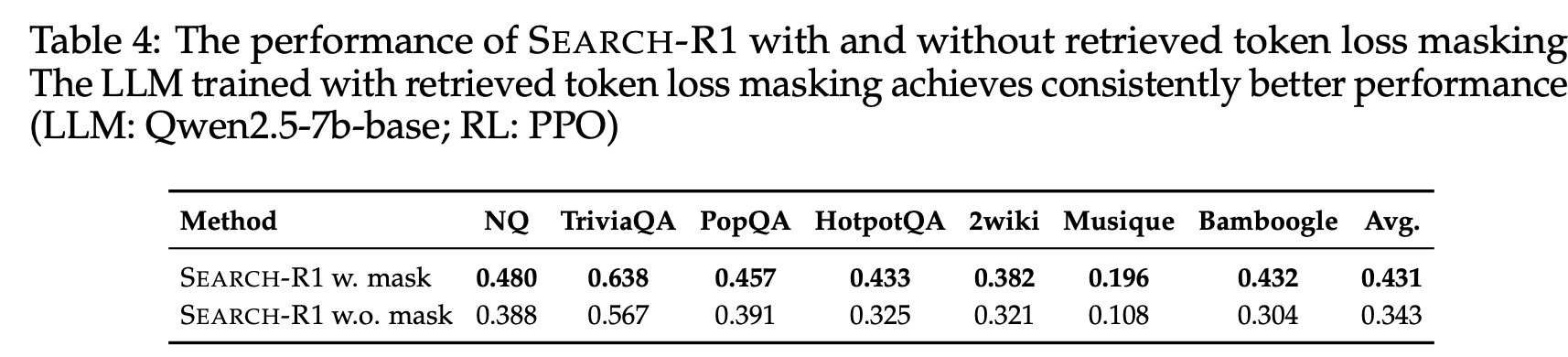
Loss Masking for Retrieved Tokens
PPO와 GRPO에서는 token-level loss를 전체 rollout sequence에 대해 계산함. 하지만 Search-R1의 rollout sequence는 LLM이 직접 생성한 token과 external knowledge에서 가져온 token이 함께 포함됨.
LLM이 직접 생성한 token에 대해 손실을 최적화하는 것은 model이 search engine과 효과적으로 상호작용하고 추론하는 능력을 높이는데 도움됨. 그러나, 동일한 최적화를 검색된 token에까지 적용하면 원치 않는 학습 효과가 발생할 수 있음.
따라서, Search-R1은 검색된 token에 대한 loss masking을 적용하여, policy gradient objective은 LLM이 생성한 token에 대해서만 계산하고, 검색된 content는 최적화 과정에서 제외됨.
→ 검색 기반 생성의 유연성은 유지하면서 학습 안정성을 높임
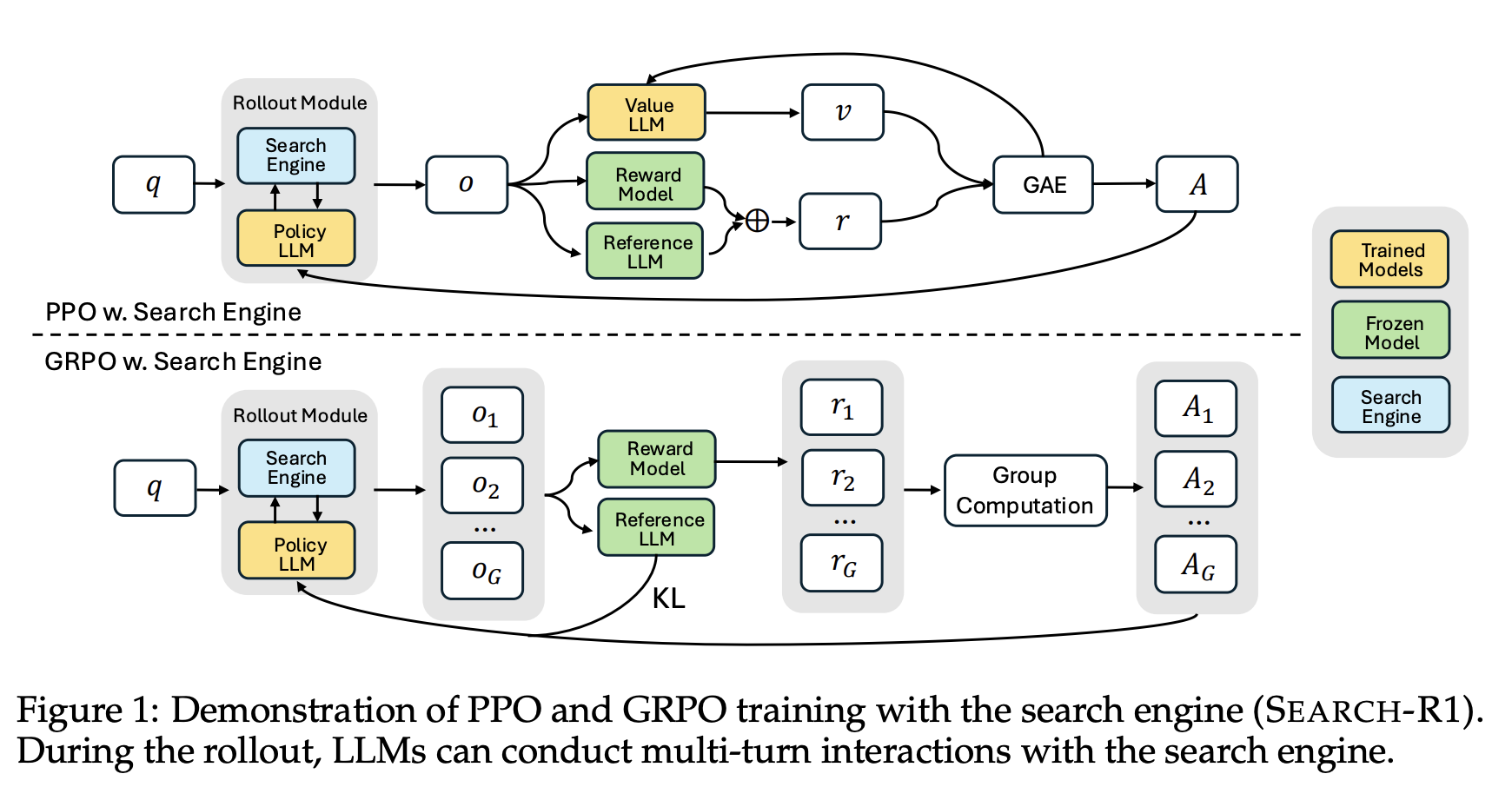
PPO with Search Engine
Search-R1에서는 검색 호출이 포함된 시나리오에 맞춰 PPO를 적용함
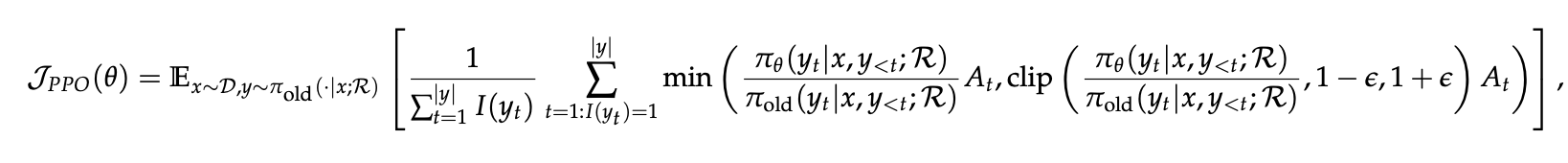
-
\pi_{\theta}: current policy
-
\pi_{old}: previous policy
-
I(y_t): token loss masking 연산으로, y_t가 LLM이 생성한 token이면 1, 검색된 token이면 0으로 설정
GRPO with Search Engine
GRPO 역시 PPO와 마찬가지로 Search Engine을 적용할때, 검색된 token은 masking 적용함
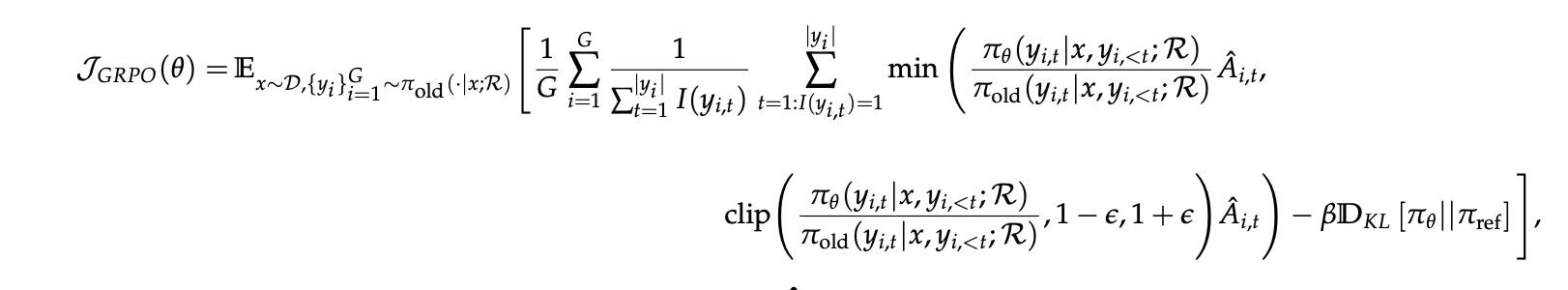
3.2 Generation with Multi-turn Search Engine Calling
Search-R1이 어떻게 multi-turn search와 text 생성을 interleaved하게 수행하는지 rollout process를 수식적으로 나타내면 다음과 같음
-
y ~ \pi*{\theta}(. x;R) =\pi*{ref}(. x)\bigotimes R
→ LLM은 x를 입력 받아 Search Engine R과의 interleaved 흐름을 통해 y를 생성
Search-R1의 생성 과정은 iterative한 구조로 진행됨
-
LLM은 text를 생성하다가 필요할 때마다 external search engine queries를 보낸 뒤 검색 결과를 다시 반영하여 다음 generation step을 수행하며 이어가는 방식
-
system instruction은 LLM에게 external retrieval이 필요할 때 search query를
와 <\search> token으로 감싸도록 함 -
generated sequence에 이러한 token이 감지되면, system은 query를 추출해 search engine에 전달하고 적절한 relevant results를 가져옴
-
retrieved information은
과 <\information> token으로 감싸져 현재 rollout 시퀀스에 추가됨. 이렇게 추가된 정보는 next generation step에 추가 context로 활용
위 과정이 반복적으로 이어가다가 아래 두 가지 조건 중 하나를 만족하면 종료함
-
사전에 정의된 최대 행동 횟수에 도달할 때
-
모델이 최종 응답을 생성하여 이를
와 <\answer> token으로 감쌀때

3.3 Training Template
Search-R1을 학습시킬때 사용하는 prompt template
-
아래 template은 모델이 출력할 구조를 think → search → answer 순서로 명확히 나누도록 유도함
-
다만 특정 해결 방식이나 반영 수준을 강제하지 않아 모델이 RL 과정에서 자연스럽게 학습하도록 설계함 (구조적 형식만 따르게 제한함)

Case Study

3.4 Reward Modeling
Search-R1은 outcome-based rule-based reward function을 사용함
-
예를 들어, factual reasoning task에서 정답과 모델의 출력이 일치하는지 exact match로 평가함
-
별도의 형식 보상이나 복잡한 과정 기반 보상은 사용하지 않고, 신경망 기반 보상 모델도 학습하지 않아 학습 복잡성을 줄임
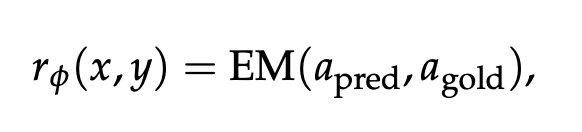
4. Main Results
4.1 Datasets
-
General QA
-
Natural Questions (NQ)
-
TriviaQA
-
PopQA
-
Multi-Hop QA
-
HotpotQA
-
2WikiMultiHopQA
-
Musique
-
Bamboogle
4.2 Baselines
-
Inference w/o Retrieval
-
Direct Inference
-
Chain-of-Thought
-
Inference w/ Retrieval
-
RAG
-
IRCoT (Information Retrieval CoT)
-
Search-o1 (using search engine tool)
-
fine-tuning methods
-
SFT
-
R1: search engine없이 RL fine-tuning (Search-R1과 fair한 비교를 위해 동일 데이터로 RL을 학습하되 검색은 사용하지 않음)
4.3 Experimental Setup
-
LLMs: Qwen-2.5-3B, Qwen-2.5-7B (Base / Instruct)
-
Retrieval
-
Knowledge Source: 2018 Wikipedia dump (using E5 as retriever)
-
number of retrieved documents: 3
-
-
Dataset
-
training data: NQ + HotpotQA for Search-R1 and fine-tuning methods
-
evaluation data: (in-domain, out-of-domain)
-
-
metric: EM
-
Inference 설정
- Inference-style baseline은 Instruct 모델 사용 (Base 모델은 instruction을 따르지 못함)
-
RL 설정
- 별도 언급이 없으면 PPO 사용
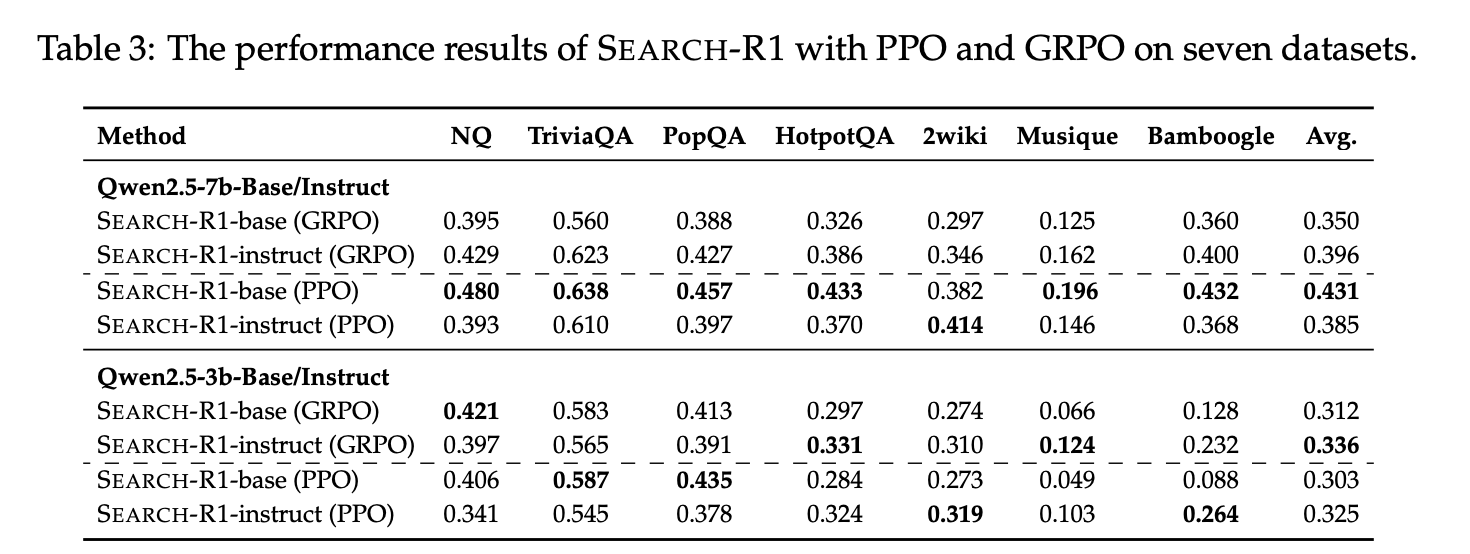
4.4 Performance
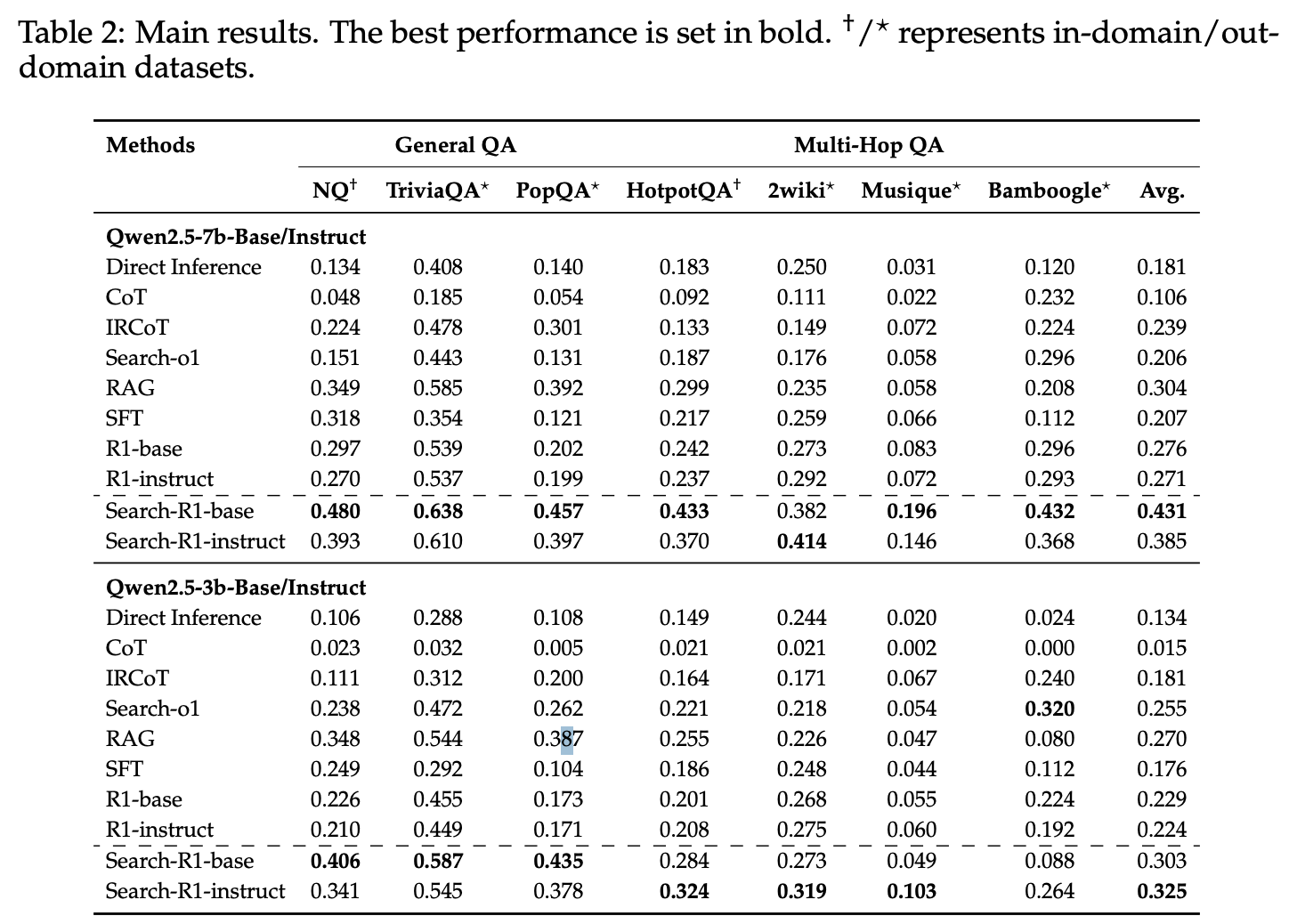
-
Search-R1은 baselines 대비 우수한 성능 보여줌
-
Qwen2.5-7B: 평균적으로 41% 향상
-
Qwen2.5-3B: 평균적으로 20% 향상
-
→ in-domain (NQ, HotpotQA)와 out-of-domain (TriviaQA, PopQA, 2Wiki, Musique, Bamboogle) 모두 일관되게 높음
- 검색 없이 추론만하는 R1보다도 Search-R1이 우수함
→ Search가 LLM 추론에 external knowledge를 추가함으로써 도움되는 것을 보임
- Base와 Instruct model 모두 일관되게 Search-R1 효과적임
→ DeepSeek-R1-Zero style의 단순 outcome-based reward가 순수 Reasoning 뿐만 아니라 search를 포함한 complex reasoning scenarios에서도 효과적임을 보여줌
- **Model size가 클 수록 검색 활용 효과가 더 큼 **
5. Analysis
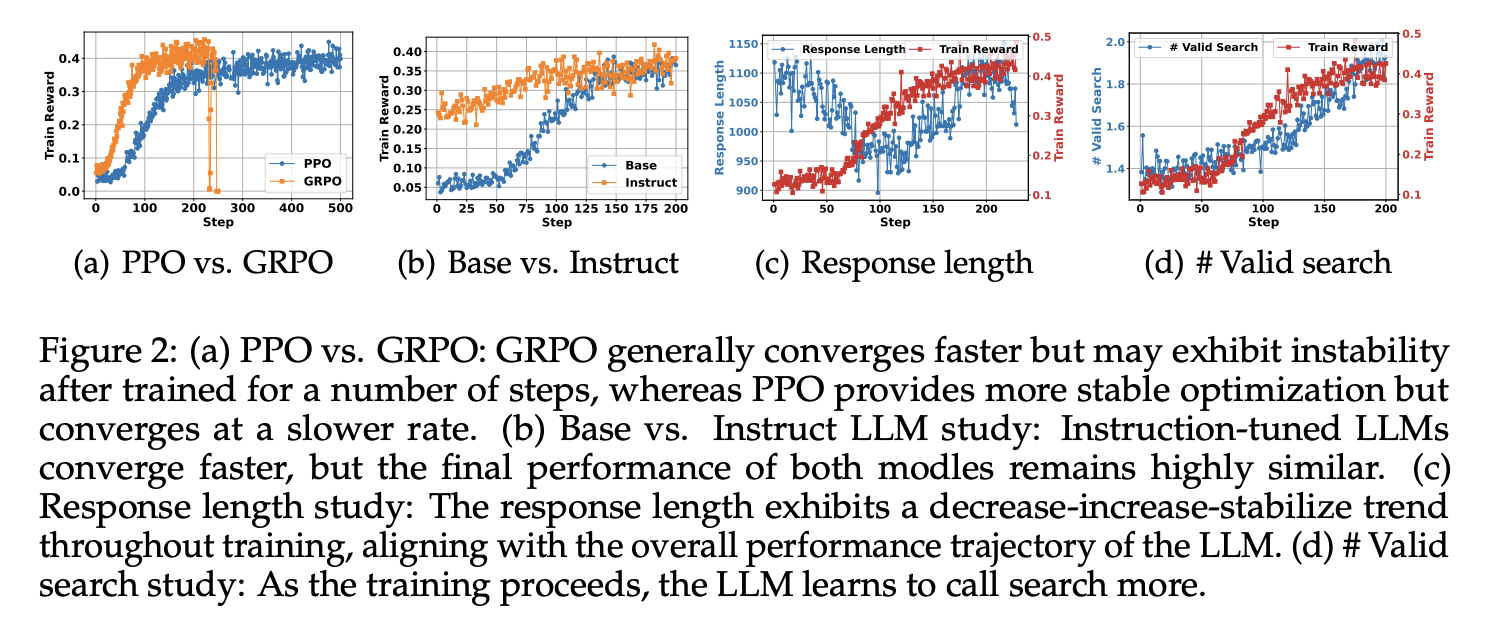
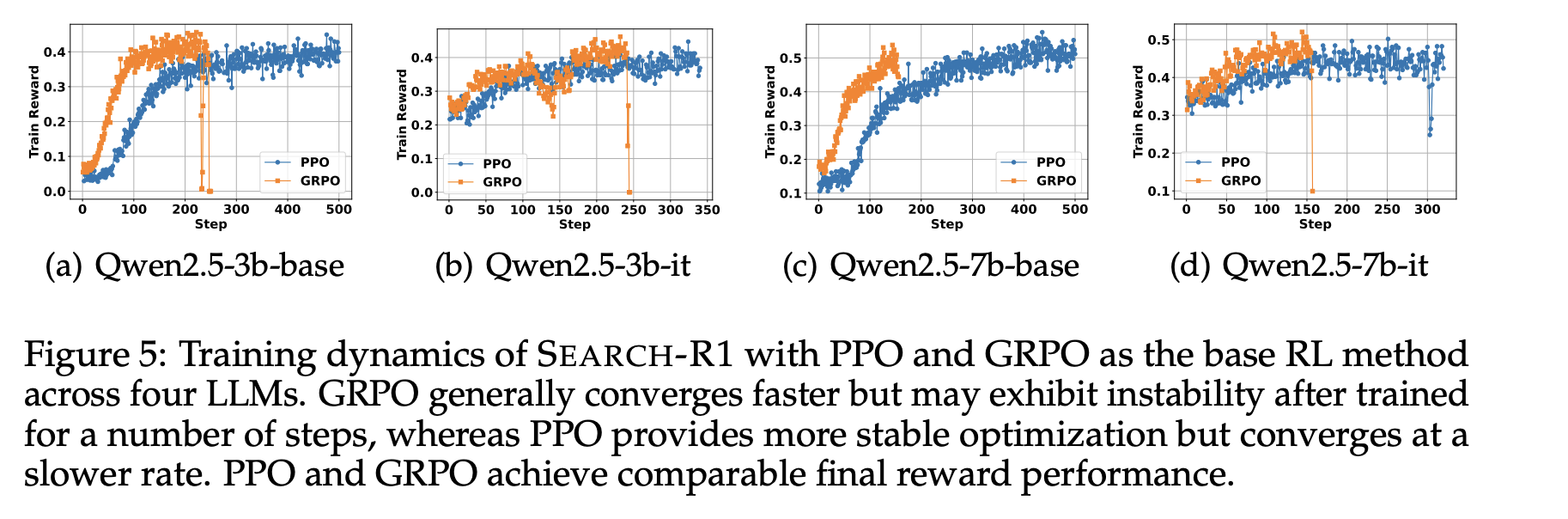
5.1 Different RL methods: PPO vs. GRPO
Search-R1에서 RL 방법으로 PPO와 GRPO 두 가지를 모두 실험함
-
GRPO는 PPO보다 수렴 속도가 빠름 → Figure2 (a)
-
PPO는 critic model에 의존하기 때문에 효과적인 학습이 시작되려면 여러 단계의 워밍업이 필요하지만, GRPO는 baseline을 여러 샘플 평균으로 잡아 더 빠르게 수렴함
-
PPO는 학습 안정성이 더 높음 → Figure2 (a)
-
GRPO는 일정 단계 이후 reward collapse가 나타나지만, PPO는 학습이 더 안정적으로 유지됨
-
최종 train reward는 PPO와 GRPO 모두 유사함
-
수렴 속도와 안정성은 다르지만 최종 성능과 train reward는 큰 차이가 없음. 그래도 GRPO는 나중에 불안정해질 수 있기에 더 안정적인 PPO가 느리지만 적합함.
(다른 세팅에서도 동일한 현상이 관찰됨)
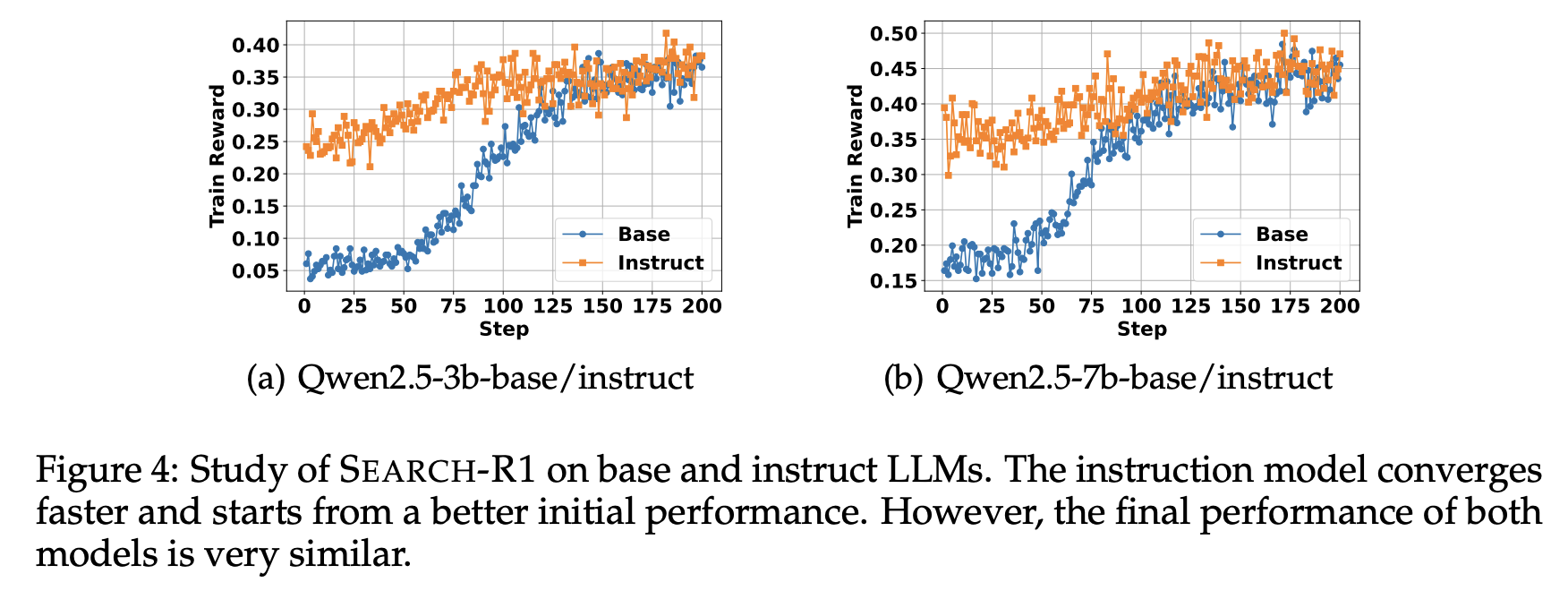
5.2 Base vs. Instruct LLMs
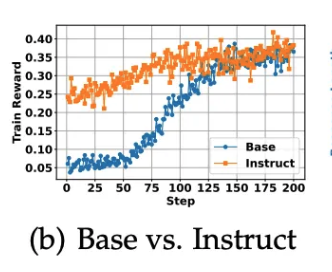
- Figure2 (b)에서 Instruction-tuned model은 Base model보다 더 빠르게 수렴하고 초기 성능도 더 높게 나오지만, 최종 train reward는 두 모델 모두 거의 동일한 수준으로 수렴함
→ 이는 사전 instruction tuning이 초기 학습을 가속화하는데 도움이 되지만, RL만으로도 Base model이 충분히 따라잡을 수 있음을 보임
(다른 세팅에서도 동일한 현상이 관찰됨)
5.3 Response Length and Valid Search Study
Qwen2.5-7B-base 모델로 response length와 검색 호출 횟수 변화를 분석함
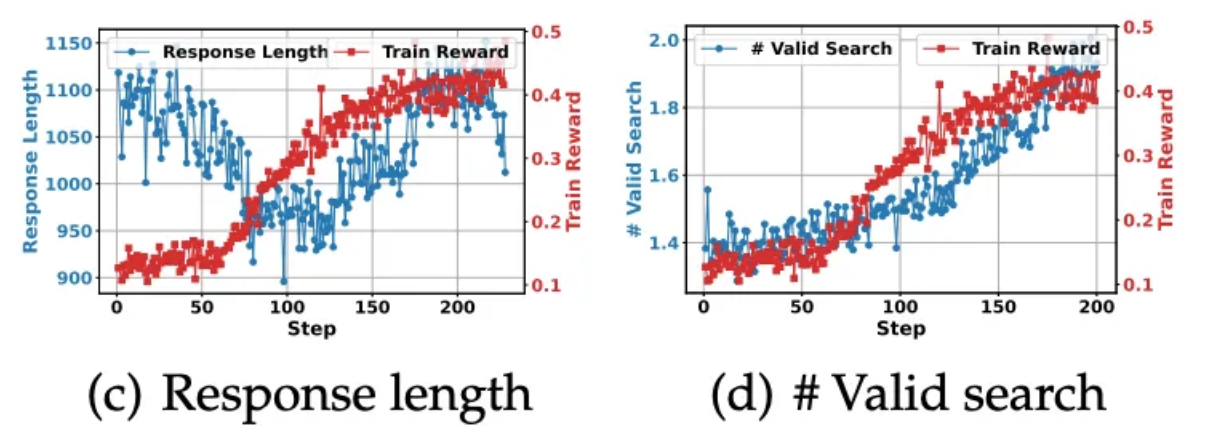
-
Figure2 (c)를 보면
-
초기 단계 (100 steps 전후)
-
응답 길이가 급격히 줄고, train reward는 소폭 상승함
-
모델이 불필요한 군더더기 단어를 줄이고 task에 적응하기 시작함을 보여줌
-
-
후기 단계 (100 steps 이후)
-
응답 길이와 train reward 모두 증가함
-
모델이 검색 호출을 더 자주 하면서 (Search Engine을 자주 호출하는 법 학습) 검색 결과가 추가되어 응답이 길어짐
-
검색 결과를 효과적으로 활용하며 train reward도 크게 향상됨
-
-
-
Figure2 (d)를 보면 학습이 진행될수록 LLM이 검색 엔진 호출을 더 많이 학습한다는 점이 드러남
5.4 Study of Retrieved Tokens Loss Masking
Retrieved Token Loss Masking은 unintended optimization을 방지하기 위해 도입한 것임. Retrieved token loss masking의 효과를 추가로 분석해봄 (Qwen2.5-7B-base)
- Figure 3에 따르면, masking을 적용하면 원치 않는 최적화 효과를 줄이고 LLM 성능 향상이 더 커짐
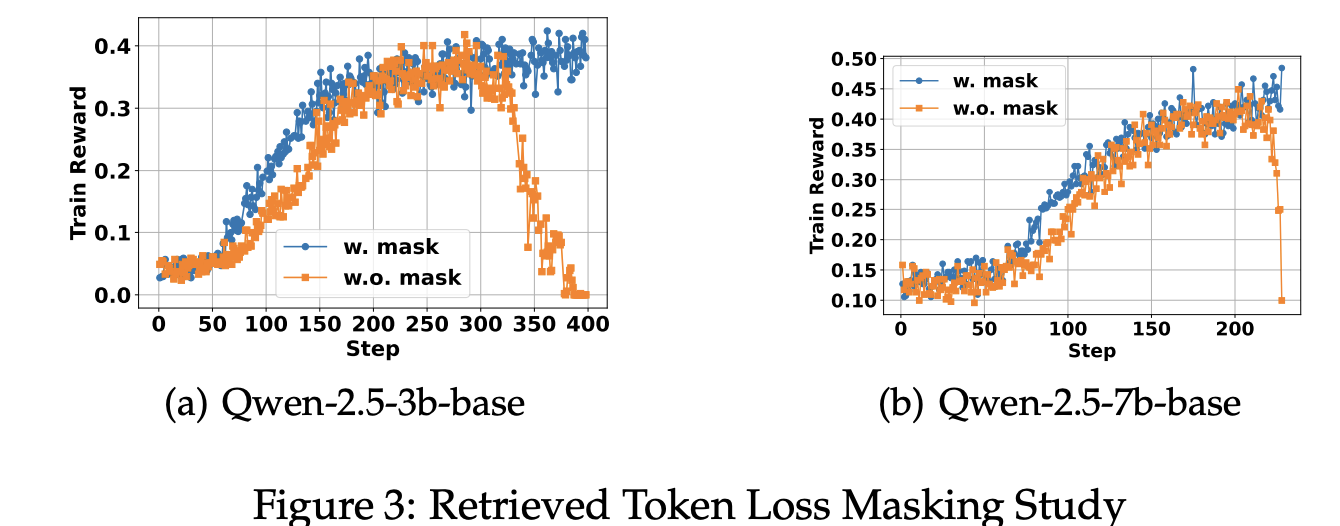
- w. mask와 w.o. mask를 비교한 결과 **masking을 적용한 경우가 항상 더 높은 성능을 기록함 **
- **Appendix**
Number of Retrieved Passages Study in SEARCH-R1 Training
- 본 실험에서는 top-k를 3으로 설정했지만, 1,3,5 바꿔가며 이것의 effect를 분석함
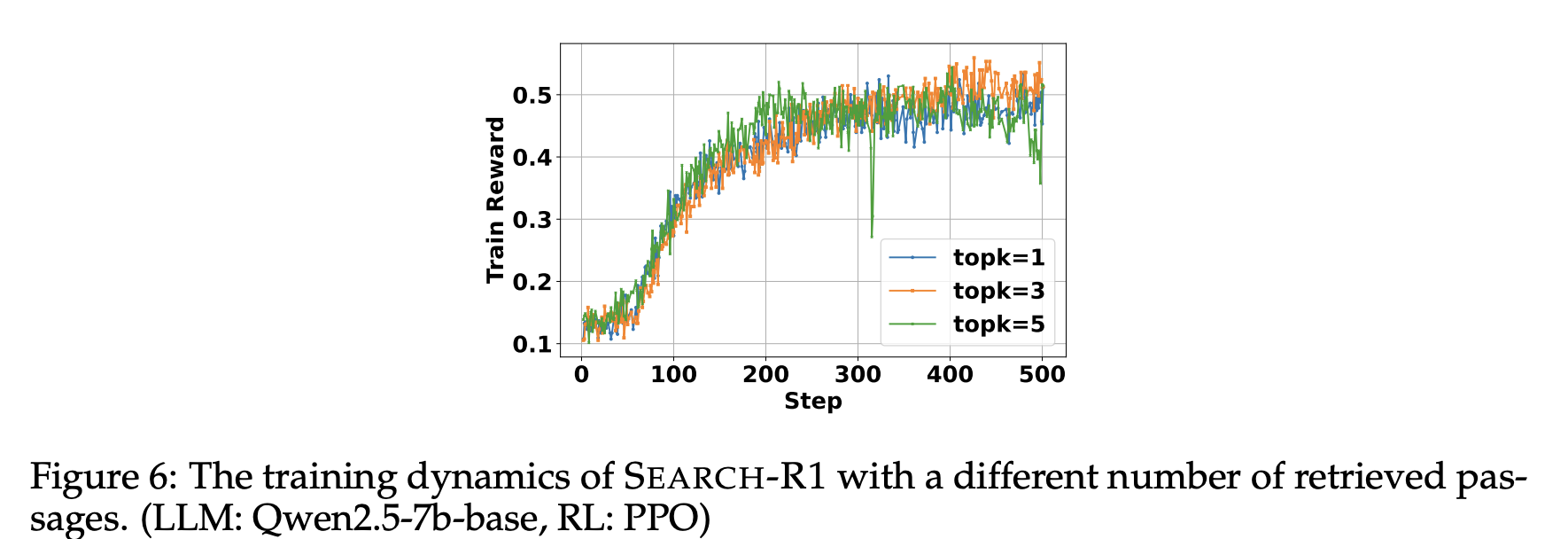
→ top-k가 1,3,5 설정이 모두 training pattern이 비슷함 (top-k=5가 초기 수렴 속도가 빠른 대신에 이후 train reward가 감소하며 학습 안정성 떨어짐을 보임)
Group Size Study in SEARCH-R1 (GRPO) Training
- 본 실험에서는 Search-R1 (GRPO)의 group size를 5로 설정했지만, group size가 어떤 영향을 미치는지 확인하고자 1,3,5로 분석함
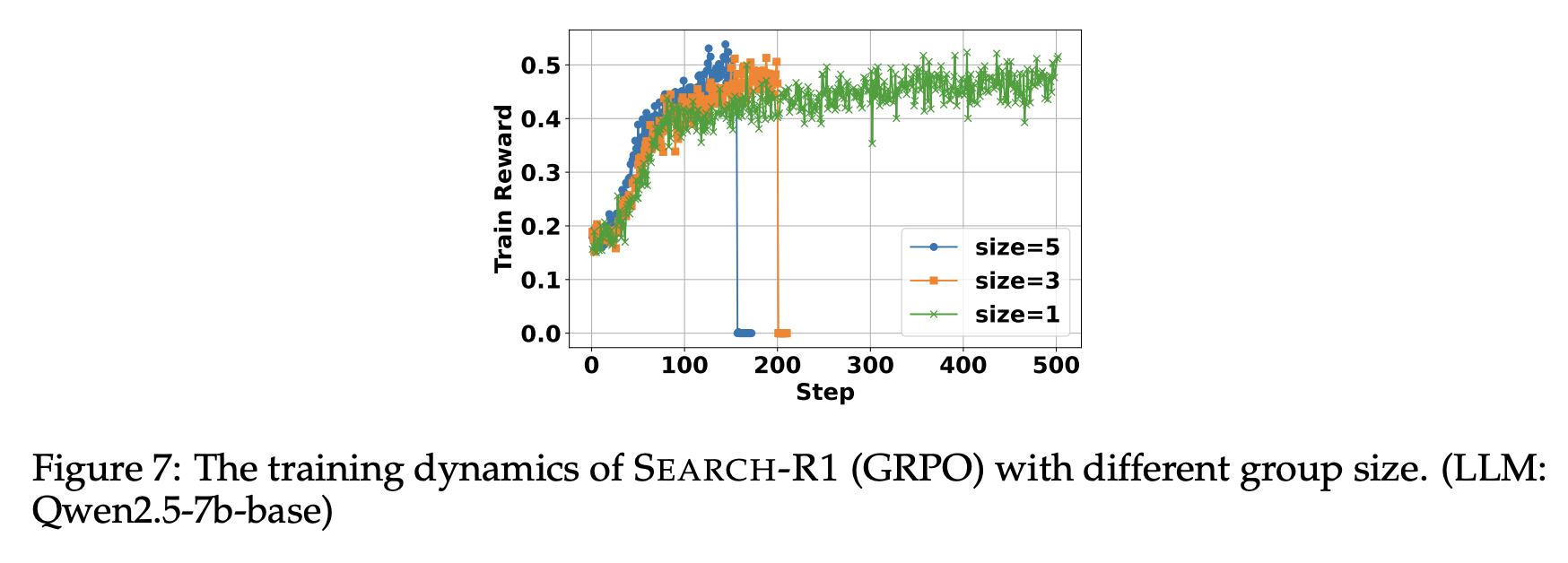
→ Figure7을 보면 group size가 칼수록 수렴 속도 빨라지는 반면 RL의 불안정성 때문에 training collapse 위험도 증가
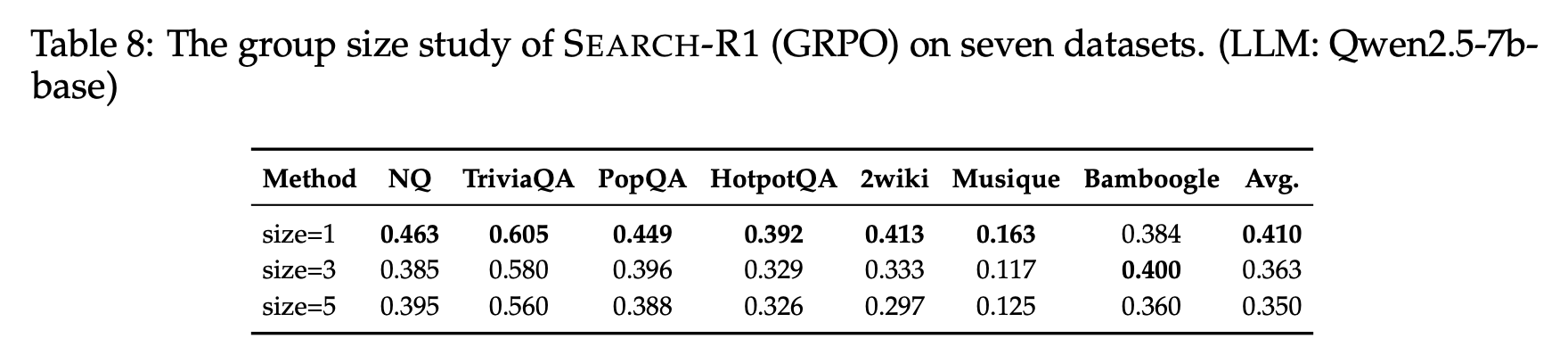
→ Table8을 보면 group size가 큰 경우 빠른 수렴과 더 높은 train reward가 있었지만, group size=1일 때 학습이 더 안정적이고 일반화 성능이 더 우수함 (out-of-domain에서 더 우수함)
6. Conclusion
-
본 연구에서는 LLM이 self-reasoning과 실시간 검색 엔진 상호작용을 교차적으로 수행할 수 있는 framework인 Search-R1 제안함
-
기존의 multi-turn search를 위해 많은 prompt에 의존하는 RAG나 대규모 train data가 필요한 tool 사용 기반 접근법과 달리, Search-R1은 RL을 통해 모델이 자율적으로 검색 쿼리를 생성하고 검색된 정보를 전략적으로 활용할 수 있도록 최적화함
Limitations
- Reward Design가 단순 결과 기반 보상이라 보다 디벨롭이 필요함