See What You Are Told: Visual Attention Sink in Large Multimodal Models
논문 정보
- Date: 2025-06-24
- Reviewer: 조영재
- Property: Multimodal
Introduction
-
LLM의 발전과 함께 Multimodal 모델들도 많이 등장하고 있음 (VQA, image captioning, visual reasoning, …)
-
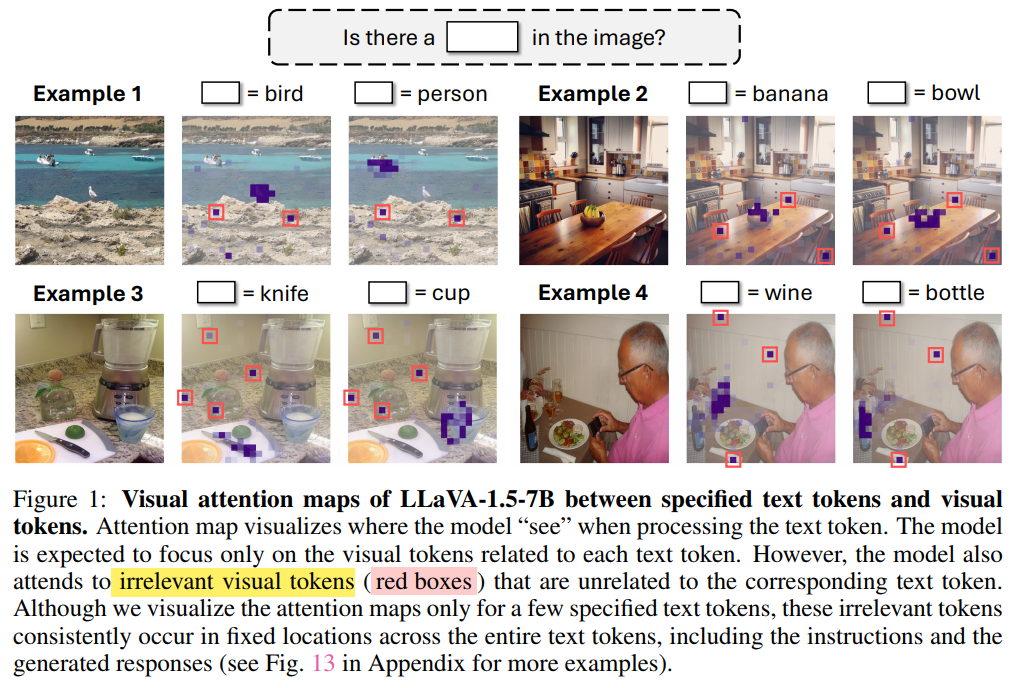
LMM에서도 LLM 처럼 똑같이 attention 매커니즘을 따름. 예를 들어 ‘bird’를 말하고자 할때 model은 해당 이미지에 관련있는 visual token에 대해 집중함. (직관적으로) text와 visual token이 매칭됨.
-
근데 실제로는 text와 visual 간의 관계가 unrelated 되는 경우도 관측됨. attention map을 통해 attention을 더 면밀히 살펴보았을때, Example 1을 보면, 위에 bird를 말하는데 ‘빨간 네모’ 처럼 bird와 무관한 곳에 높은 attention이 관측. 다른 예제들도 마찬가지로 텍스트와 무관한 곳에 높은 어텐션이 관측됨. 이게 왜 발생하는지 궁금해서 해당 연구가 시작됨
-
해당 연구의 발견
-
이러한 attention 맵의 오류는 몇몇 tokens 들이 massive activation of specific dimensions in the hidden states에서 일어남을 찾음. 이것은 LLM에서 특정 limited semantic meaning(e.g. “BOS”, “.”, “\n”)에 large attention이 부여되는 “attention sink”의 개념과 유사해보임.
-
추가로 실험을 해보니 이러한 visual sink token 들은 없애도 모델 답변의 quality에 영향을 주지 않음.
-
최근에 vlm에서 attention이 text에 비해 이미지에 부족하게 할당된다는 사전 연구도 있었음. 그래서 우리는 attention budget의 개념으로 visual sink token들에 가는 attention을 아껴서 다른 visual token들에 redistribute를 하고자 함(Visual Attention Redistribuion (VAR))
Related Work
- Visual attention in large multimodal models.
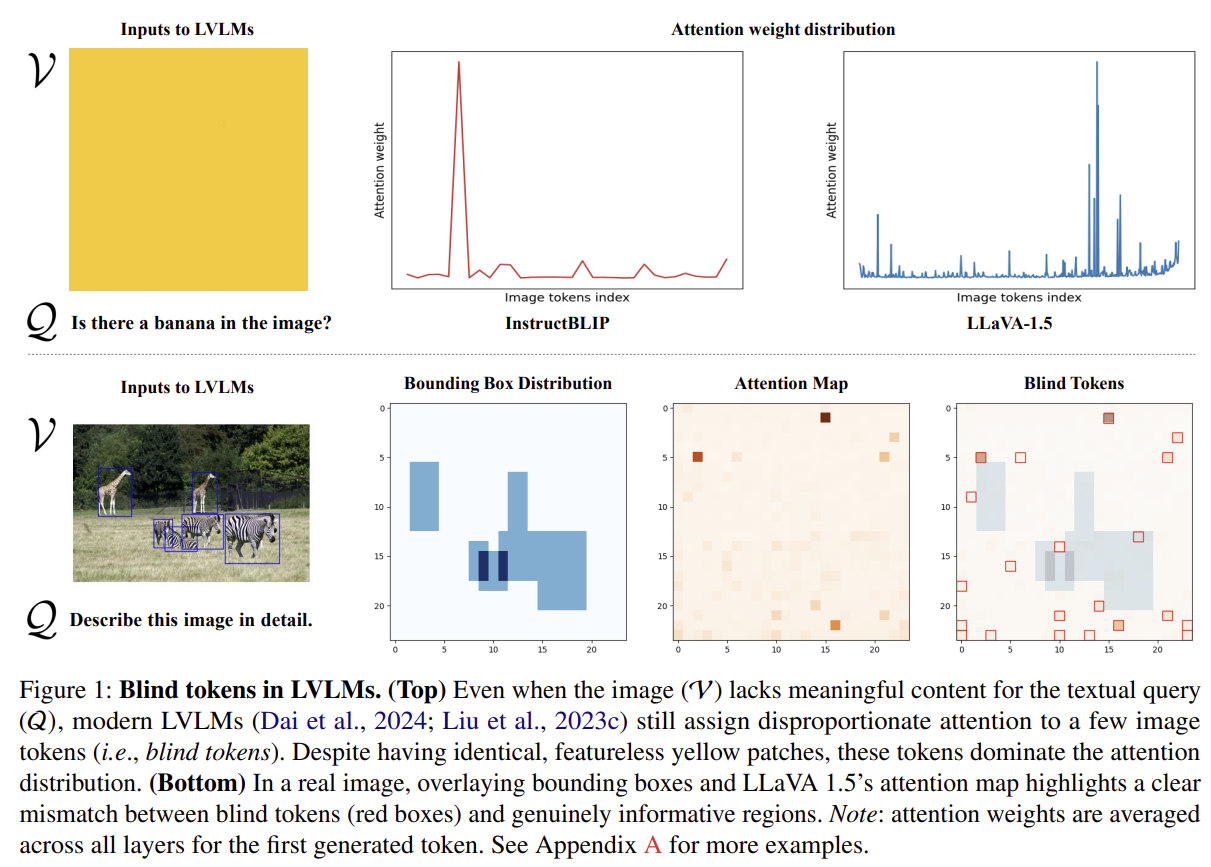
-
LMM이 특정 몇개의 토큰에 과도하게 attention을 부여한다는 연구가 있었고, 이를 활용해 contrastive decoding으로 해결하려는 시도가 있었음(빈 이미지와 질문을 넣었을 때 모델의 답변 logit을 빼서 bias를 없애는 방식, 위 이미지 참고 (https://arxiv.org/pdf/2405.17820)). 혹은 강제적으로 text에 가던 attention을 visual에 가게끔 만드는 시도.
-
Attention sink in language models
-
기존 LLM에서도 attention sink는 2024 년도 부터 제기되던 문제. 특히 BOS 같은 토큰은 AR 특성상 뒤에 모든 token들의 attention이 쏠리게 되어 의미는 적지만 attention이 높음 (c.f. StreamingLLM이란 연구에서는 attention sink가 걸린 토큰의 KV를 고정시켜 efficiency를 갖기도 함)
-
이러한 attention sink가 특히 특정 dimenstion의 hidden state에서 발생! 여기의 attention을 다른곳에 재분배해 정교한 답변을 얻으려는 llm연구도 있었음. This work는 이 개념을 VLM에 적용한 느낌
Preliminaries
트랜스포머 공식
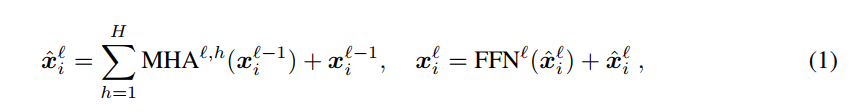
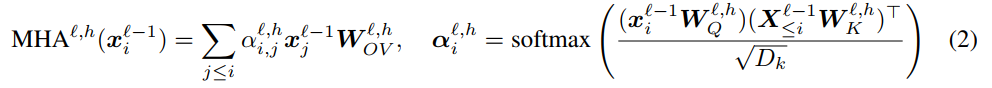

Visual Attention Sink
Figure1보면 attention이 우리의 직관대로 잘 따라가긴 하지만 고정된 어떤 background spot에 굳이 필요없는 limited semanic meaning에 높은 attention이 배정되어 있음
How to distinguish irrelevant visual tokens?
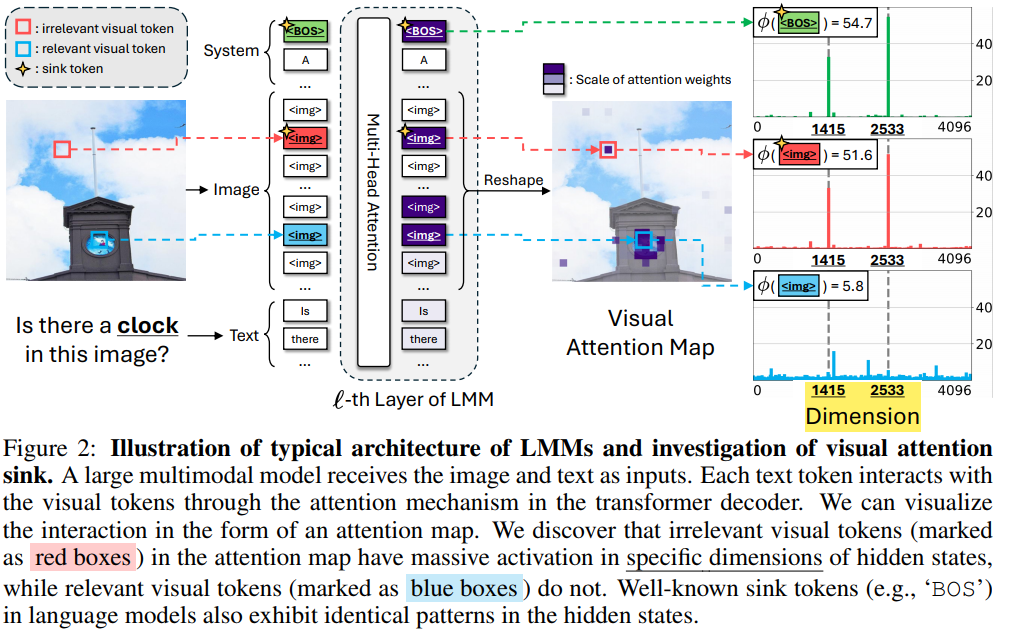
irrelevant visual token에서 두 가지 특성이 나타남. (1) figure 1에서 보듯 이미지에 same irrelevant visual token에 고정적으로 등장. (2) BOS 토큰이랑 유사하게 같은 dimension에서 등장 (Fig 2)
Irrelevant visual tokens have high activation in specific dimensions
-
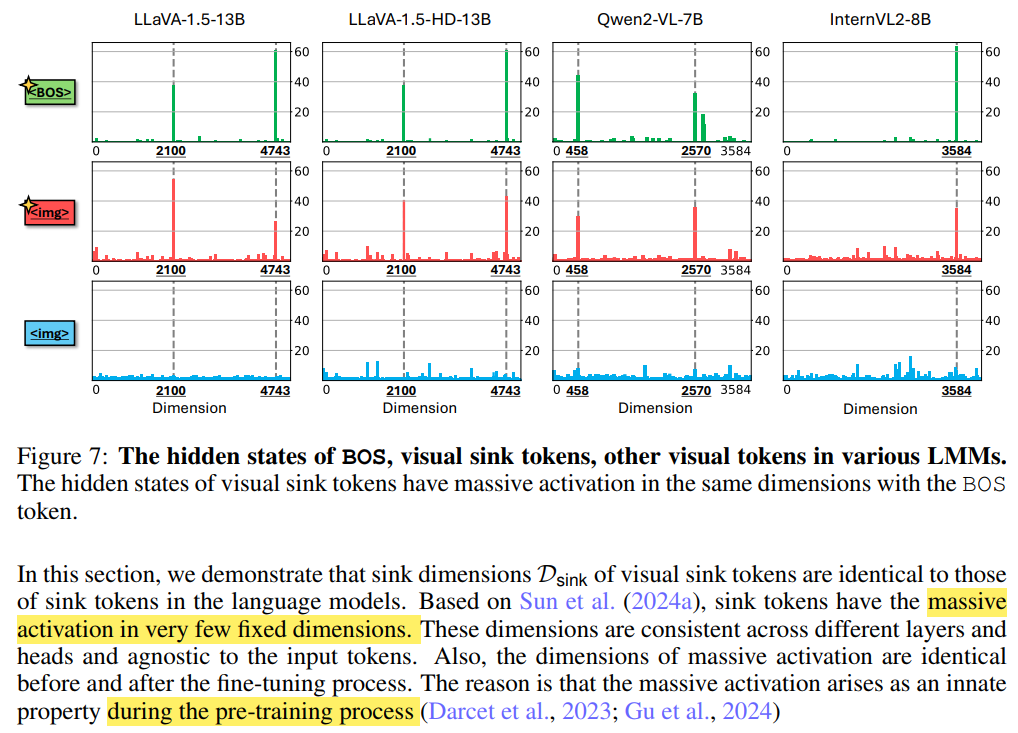
Fig2의 BOS랑 빨간
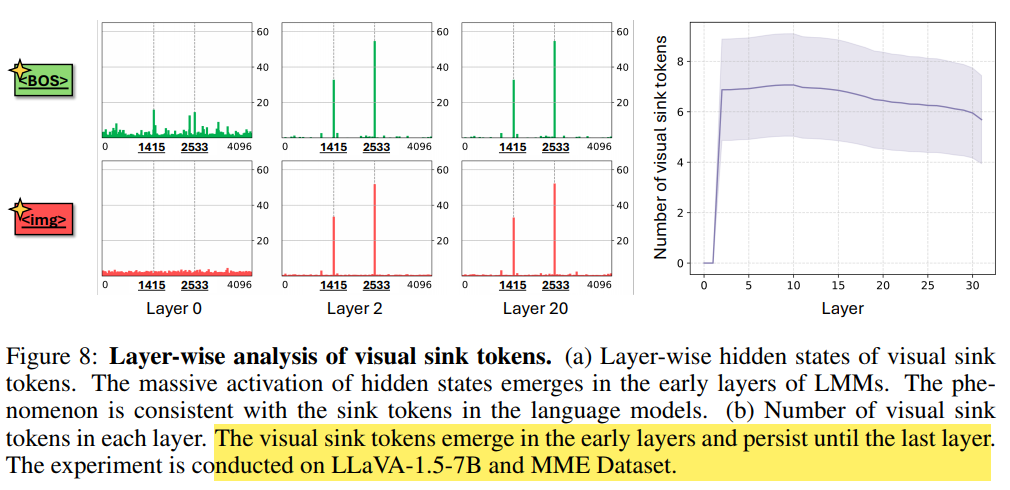
를 보면 같은 dimension에서 attention 값이 튀는 것을 볼 수 있음. 이는 LLM 각자가 같은 고유한 특성이라고 함. 예를들어 LLaVA-1.5-7B가 사용한 LLaMA2 백본은 모두 고정적으로 {1415, 2533} 의 dimension에서 위와같은 형태를 보임. (pretrain 과정에서 쏠리는 거라 finetuning을 해도 sink dimension은 계속 고정되어있다고 함)
-
특정 토큰이 갖는 sink dimension value Φ(x)를 아래와 같이 정의
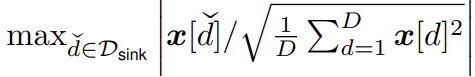
쉽게 말해서 1415, 2333 등과 같은 sink dimension에서 토큰이 갖게 되는 튀는 값을 나타냄. (Fig 2 참고)
- visual sink token을 구분하기 위해 20보다 Φ(x)가 큰 토큰들은 다 visual sink token으로 분류. 이를 통해 irrelevant visual token(sink dimension에서 attention 값이 튀는 애들)과 relevant visual token(튀지 않는 애들)을 구분함.** **
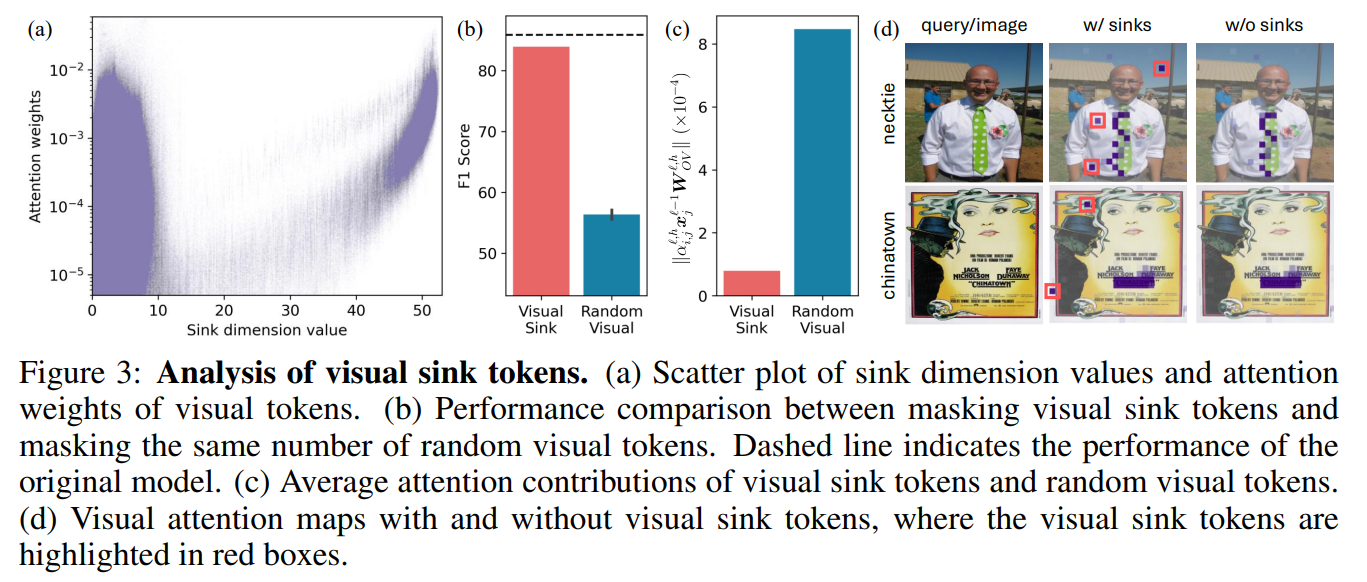
- Fig3 (a)를 통해 본인들이 정의한 high sink dimension value 들이 높은 attention 값을 가지는 애들이였으며, (b) 실제로 visual sink 들을 mask하고 하니 안할때보다 성능이 높았음. (c) attention contribution도 측정했을 때 (실제로 text 답변 만드는 logit에 기여하는 정도) 는 작았음. (d) 를 봐도 w/o sinks 가 noise를 잡아내며 대부분의 sink 들은 background에 존재
Surplus attentions in visual attention sink : can we recycle them?
(1) image centric-head 를 먼저 뽑고 (2) 해당 head에서 sink token들에 가던 attention을 보아서 non sink token 에게 분배할 예정
-
Image centric-head
-
먼저 visual token에 대한 attention weight의 sum 이 0.2 보다 작은 head는 다 버림
-
visual non-sink ratio 정의 (전체 이미지에 대한 attention 분의 non visual sink token 에 대한 attention). 즉, 이미지를 해석하는데 실제로 필요한 애들의 비율
-
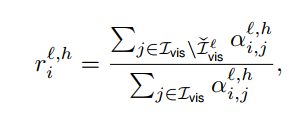
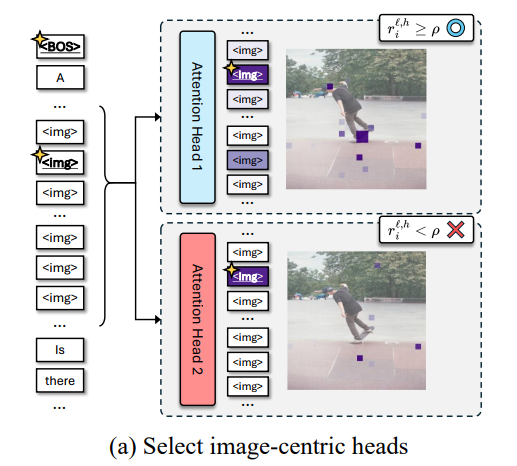
-
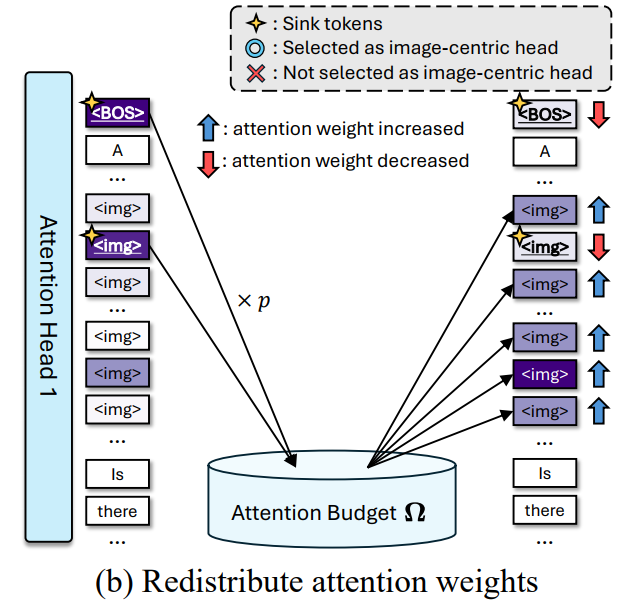
Redistributing attention weights
- sink 토큰들에 대해 decrease 시키고
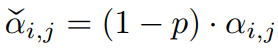
- 이것들을 모아서 attention budget에 넣어줌 (오메가)
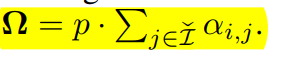
- 그리고 아래 식을 통해 attention sink에 attention 을 빼앗겼던 부분에 더 높은 가중치를 주어 redistribution
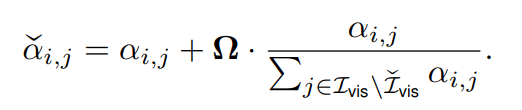
Experiments
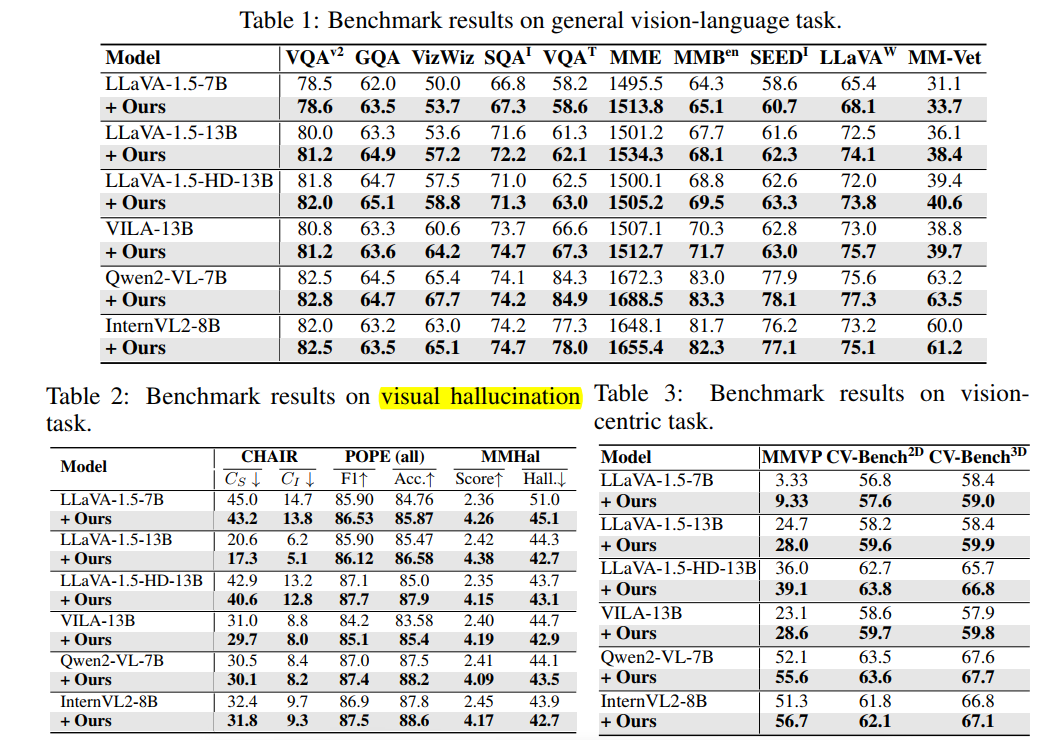
(1) VL-task
(2) visual hallucination
(3) vision centric (spatial relationship between objects)
Ablation studies
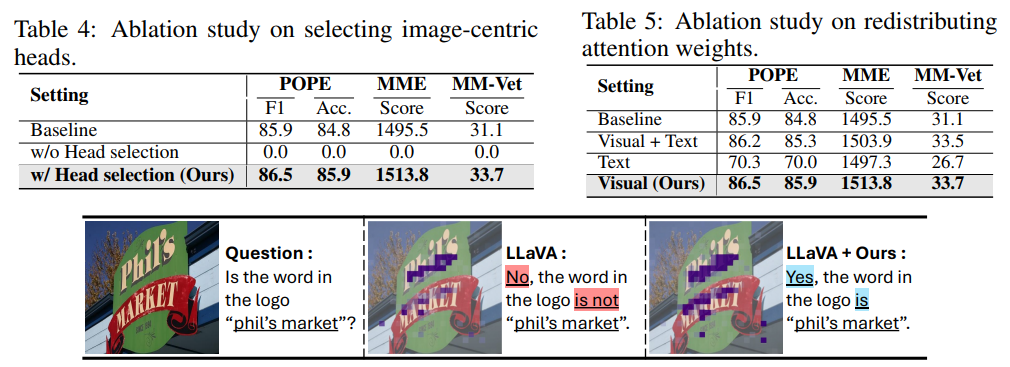
-
(Table 4) visual non sink ratio 를 정의해서 로 보다 큰 애들의 head 만 살렸었는데 이 과정이 필수적이였음.
-
(Table 5) visual token 내에서만 attention redistribution이 성능이 제일 높음.
Appendix
Discussion
-
latency가 별로 없으면서 정말 많은 VL task에서 성능이 다 오른건 신기! 다만 해당 방법론 역시 projector을 이용한 vision language model에서만 적용 가능할 것으로 보임. (one-to-one 매칭, instructVL, instructBLIP같은 resampler는 적용 안됨)
-
마지막 table5에서 budet을 아껴서 text에 줬을 때 성능이 안오른건 의외. 직관적으로 필요 없는 잉여물을 준다고 해서 오르는건 아닌것같음