Spurious Rewards: Rethinking Training Signals in RLVR
논문 정보
- Date: 2025-08-19
- Reviewer: 건우 김
- Property: RLVR
Key Takeaways
-
Pretraining is important for RLVR: RLVR outcomes depend heavily on reasoning strategies already learned during pretraining.
-
Weak or spurious rewards can still work: Even random or incorrect rewards can improve performance by amplifying useful pre-existing behaviors (e.g., code reasoning).
-
Limited generalization: Gains observed in Qwen models do not necessarily transfer to other model families like Llama or OLMo.
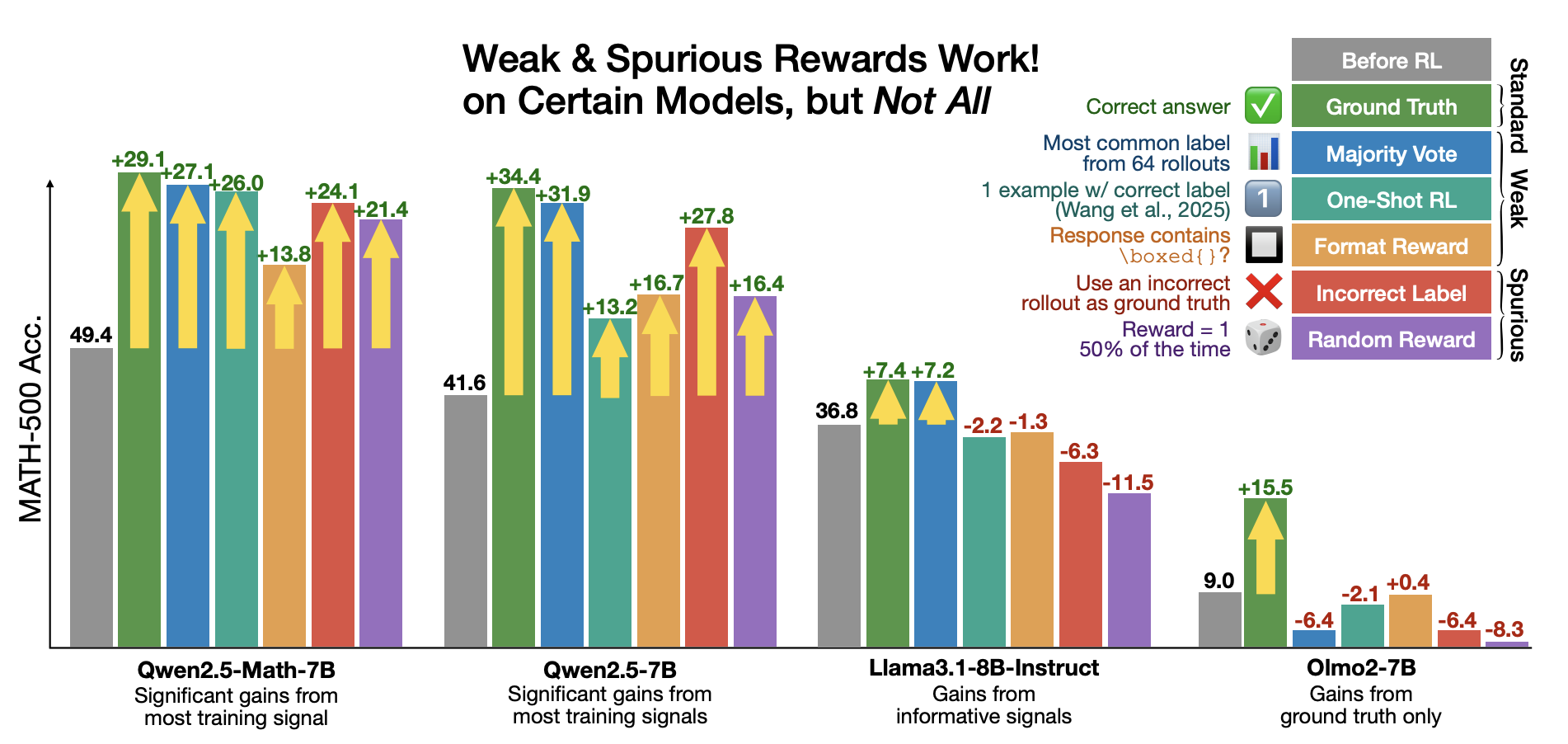
1. Introduction
최근에 RLVR이 language model reasoning을 향상시킴에 있어 큰 도움이 되었는데, 역설적으로 본 연구에서 처음으로 spurious rewards만으로도 특정 모델에서 강력한 mathematical reasoning을 이끌어낼 수 있음을 보여줌.
-
MATH-500에서 Incorrect labels을 이용해 학습하면 24.1% 성능 향상을 보여주고, 이는 ground truth reward를 사용했을때 29.1% 향상과 비슷한 수준임
-
format reward, random reward → 13.8%, 21.4% performance increases, respectively
→ 위 발견은 RLVR이 성능을 개선하는 정확한 메커니즘을 아직 완전히 이해하지 못하고, 많은 경우 RLVR은 reward signal과는 별개로, pretraining 중에 학습된 모델의 innate abilities를 드러내는 방식으로 작동할 수 있다고 볼 수 있음.
weak and spurious rewards가 주는 성능 향상을 측정하기 위해 cross-model analysis를 진행했고, 그 결과 non-Qwen models (OLMo2, Llama3 variants)는 성능 향상이 거의 없거나 오히려 악화된 결과를 보여줌.
→RLVR 성능 차이가 적어도 일부는 pretraining에서의 차이에서 비롯됨을 시사함
본 연구는 pretraining 과정에서 주입된 reasoning patterns이 RLVR 학습에 큰 영향을 끼치는 것을 알아야한다는 것을 강조함.
-
Qwen models은 open weight and high performance이기에, RLVR 연구의 de facto choice가 되버림 (최근 RLVR 연구 대부분이 Qwen2.5-Math-7B 중심의 실험)
-
본 연구에서 Qwen 계열 models은 spurious rewards 만으로도 큰 성능 향상을 얻을 수 있음을 보여줌
→ 향후 RLVR 연구는 가능하다면 다른 계열의 models에서 결과가 재현되는지 확인하는 것을 제안함.
2. Spurious Rewards Yield Significant RLVR Gains
2.1 Experimental Setup
최근 RLVR 연구들을 따라, GRPO를 사용하여 Qwen2.5-Math를 finetune 수행하고 rollouts에 대해 binary reward를 부여함.
해당 standard ground-truth reward를 대체하기 위해 점진적으로 약화된 reward functions을 다음과 같이 설계함 (얼마나 적은 supervision으로도 효과적인 RLVR 학습이 가능한지 한계를 확인하기 위함)
-
Ground truth reward: standard RLVR approach (upper bound for reward supervision quality)
-
weak rewards
-
majority vote reward: ground truth labels을 사용하지 않고, RLVR 학습을 하지 않은 model을 활용해 pseudo-label 진행 (각 prompt에 대해 64개 response 추출후 majority answer를 선택하여, online RLVR training에 활용)
-
format reward: response의 수학적 정답 여부를 전혀 고려하지 않고, 최소한 하나의 non-empty \boxed{} expression이 있으면 reward 부여함. (괄호 안의 정답 여부 상관없음)
-
-
spurious rewards
-
random reward: no guidance in the rewarding process를 해도 수학 성능이 향상되는지 확인함. 보상을 fixed probability \gamma로 설정하여 \gamma 확률로 reward 1을 부여함 (\gamma=0.5 사용)
-
incorrect reward: 의도적으로 incorrect supervision을 제공하여 incorrect answer에 대해서만 reward를 부여함 (majority voting으로 training data를 labeling한 뒤에, incorrect label이 붙은 subset만 선택하여 training data로 사용함 → 이렇게 얻어진 incorrect label은 model이 산출할 가능성이 높은 출력)
-
- Training data: DeepScaleR (40,000 unique math problem-answer pairs)
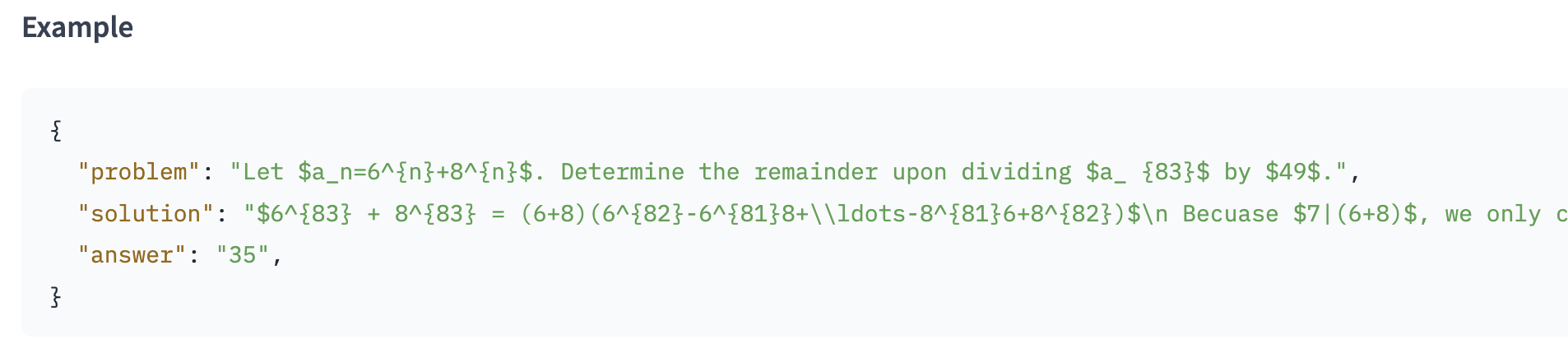
-
Benchmark dataset (+Metric)
-
MATH-500 w/ pass@1 accuracy
-
AMC w/ average@8 accuracy
-
2.3 Results
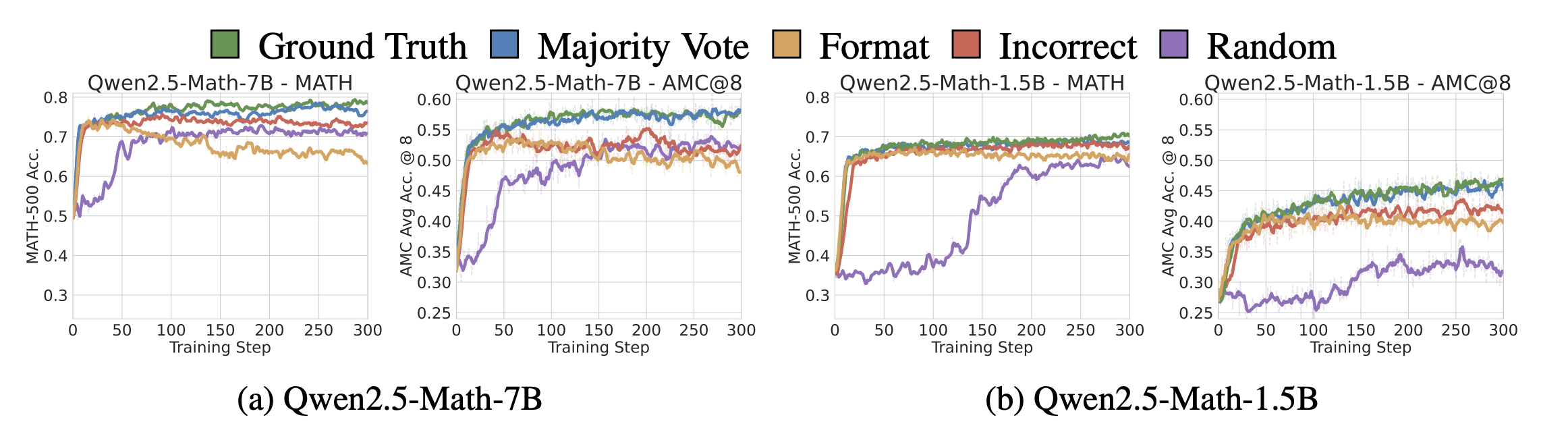
-
MATH, AMC 모든 벤치마크에서 reward 종류와 상관없이 untuned baseline 대비 학습 초반 50 steps이후부터 유의미한 성능 개선을 보여줌
- (예외) Qwen2.5-Math-1.5B에서 Random reward는 비교적 느리게 학습되며, AMC에서는 4.9% 제한적 성능 향상을 보여줌
-
MATH-500과 AMC에서 모두 Spurious rewards에 의한 성능 향상은 ground truth 기반의 RLVR과 차이가 크게 나지 않음을 보여줌
-
**Additional Results (AIME 2024, 2025)**
-
AIME2024역시 ground truth와 spurious rewards랑 큰 차이를 보여주지 않음
-
다만 AIME2025에서는 유의미한 차이가 나타나는데, 이는 AIME2025가 model의 지식 cutoff 이후에 작성된 문제들을 포함하기 때문 (그럼에도 불구하고 untuned baselines 대비 성능 향상 보임)
-
-
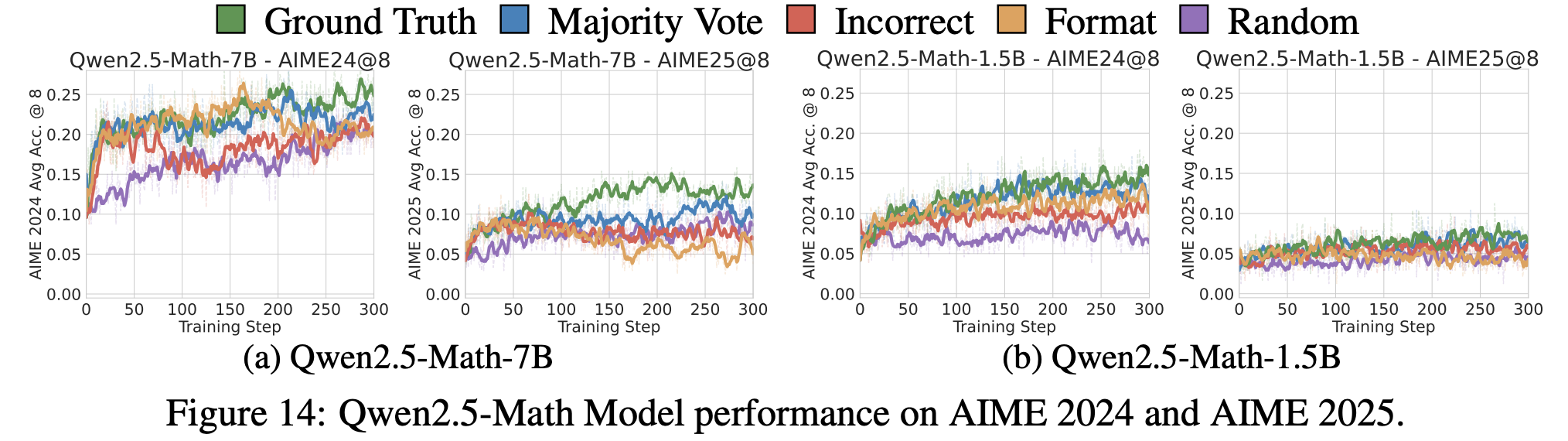
→ 위 실험 결과는 적어도 open-source post-training pipeline 규모에서, RLVR은 새로운 reasoning capabilities를 가르치는 것이 아니라, 이미 base model의 latent capabilities를 trigger함을 보여줌
(뒤에 추가 실험 결과들은 위 가설을 뒷받침함)
3. (Lack of) Generalization to Other Models
Section 2에서 보여준 현상이 다른 모델을 학습할 때에도 적용되는지 확인하는 실험을 함.
Models
-
Qwen2.5-7B, Qwen2.5-1.5B (수학 특화 모델이 아닌 general-purpose variants)
-
Llama3.1-8B(-Instruct), Llama3.2-3B(-Instruct)
-
OLMo2-7B, OLMo2-7B-SFT
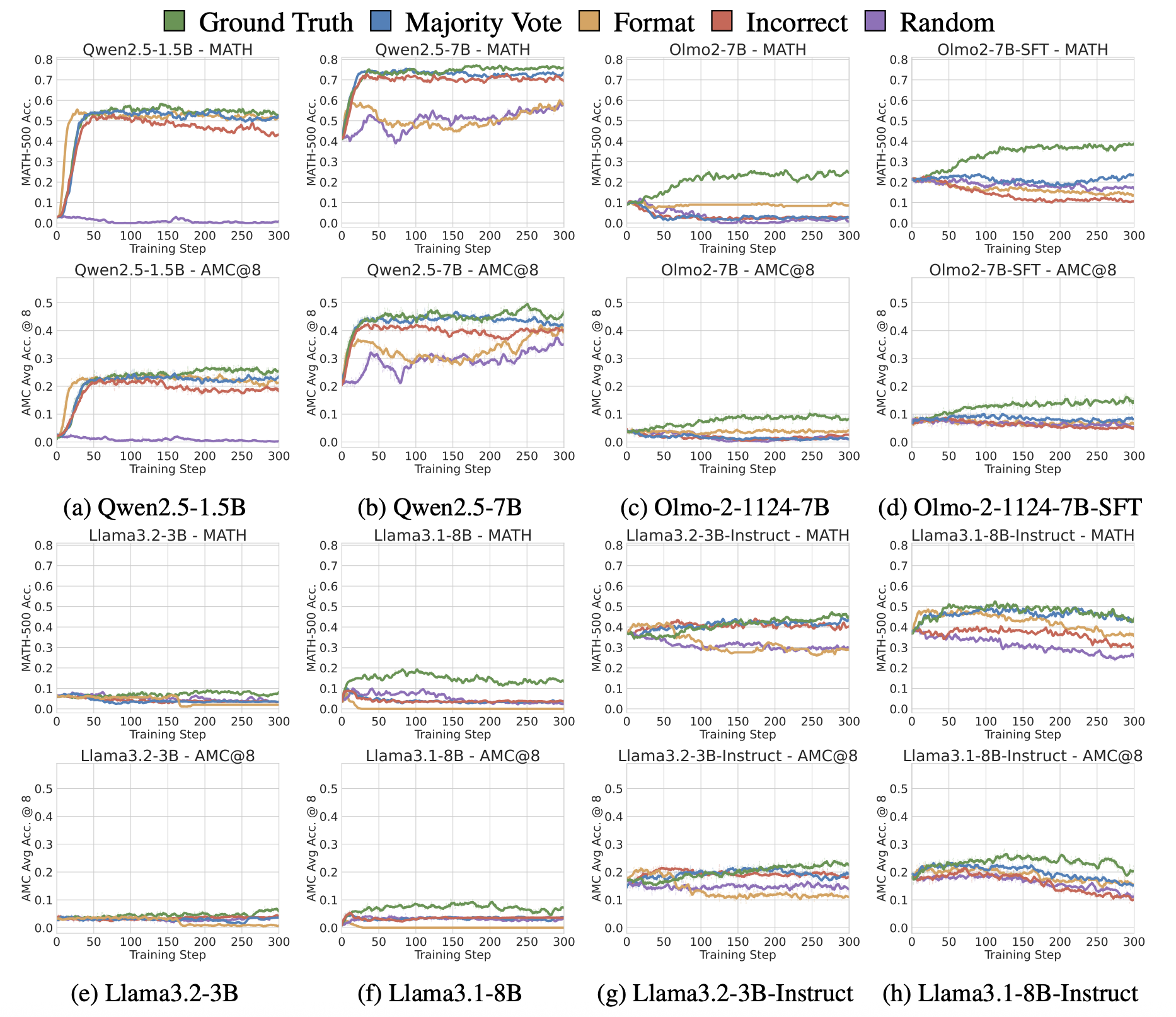
Spurious rewards can benefit Qwen2.5 models, but nearly always fail to improve non-Qwen models.
-
같은 계열의 models에서는 일반적으로 유사한 경향을 보여줌
-
Qwen2.5 models에서 random reward를 제외하면, MATH와 ACC에서 명확한 성능 향상을 보여줌
-
OLMo models은 ground truth reward에 대해서만 효과 있음 (spurious rewards X)
-
**→ 저자들은 같은 계열의 model들이 유사한 경향을 보여주는 이유는, pretraining data의 distribution이 유사하기 때문이라고 추정함 **
- 작은 models일수록 spurious rewards의 gain이 낮음
→ 저자들은 bigger models이 pretraining 단계에서 더 많은 knowledge를 학습했고, spurious rewards가 그 지식을 이끌어낼 수 있기 때문이라고 추정함
-
어떤 model 계열에서 잘 작동하는 reward signals이 다른 계열의 모델로 일반화되지는 않음
- Spurious rewards는 Qwen 계열의 models에서 일관된 성능 향상을 보여주고, 다른 계열의 models에서는 그렇지 않음
Practical warning : Proposed RLVR reward signals should be tested on diverse models!
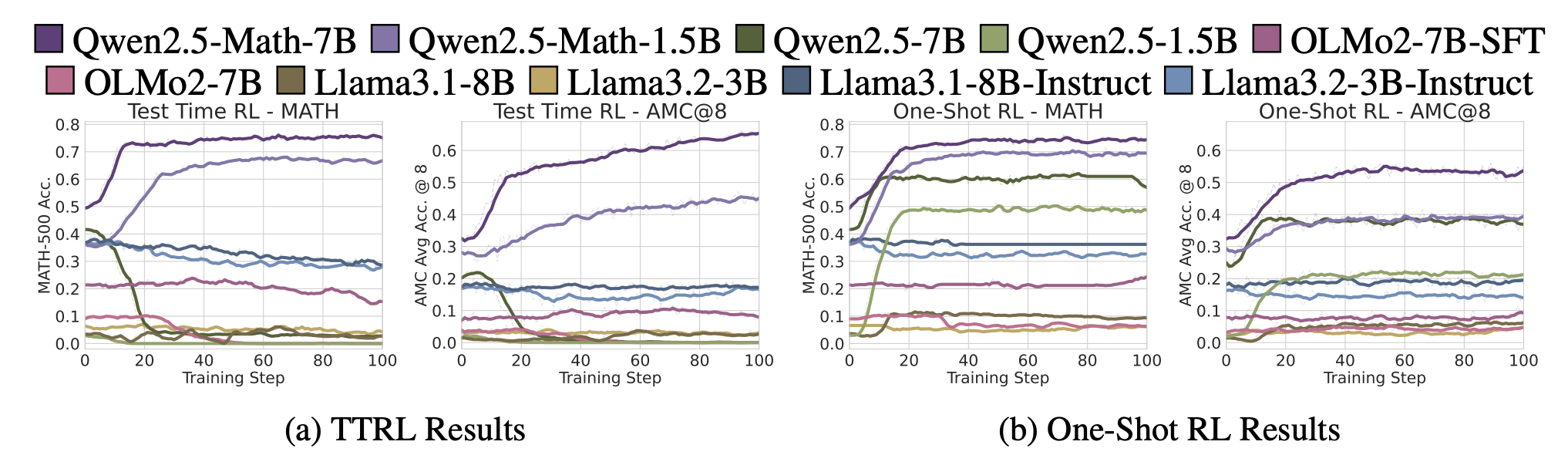
-
최근 RLVR reasoning 연구들은 주로 Qwen model에 대해서 결론을 도출함 (test-time scaling, one-shot RL)
-
TTRL과 One-Shot RL에 대해서 Qwen 계열 models을 포함하여 다른 계열의 models도 실험해본 결과,
-
proposed rewards는 Qwen 계열에서는 잘 작동함 (어떤 spurious reward 적용했는지 언급 x..)
-
동일한 reward signal임에도 다른 models 계열에서는 성능 향상이 없음
-
→ 앞으로 Qwen-centric RLVR 연구는 non-Qwen models에 대해서도 validation이 필요함
4. What Makes RLVR with Spurious Rewards Work?
Section 3에서는 동일한 reward function을 사용함에도 불구하고 model에 따라 결과가 달라지는 것을 보여줬고, 이번 Section에서는 왜 이러한 discrepancy가 발생하는지 알아봄.
*hypothesis**: RLVR 결과의 차이가 각 model이 pretraining하는 동안 학습한 특정 reasoning strategies의 차이에서 발생함. (어떤 strategy는 RLVR에 의해 쉽게 이끌어낼 수 있고, 다른 strategy는 그렇지 않음)*
-
Qwen-Math는 효과적으로 활용하고 다른 model 계열은 그렇지 못하는, ‘generating code to assist in math reasoning’ strategy를 확인함 (Section 4.1)
-
RLVR 학습 과정에서 code reasoning의 prevalence를 tracing하며, 위 hypothesis를 지지하는 evidence 발견함 (Section 4.2)
-
Incorrect and Random rewards (Spurious rewards)의 reward signals의 origin에 대한 hypothesis를 제안함 (Section 4.4)
4.1 Different Models Exhibit Pre-existing Discrepancies in Reasoning Strategies
Qwen2.5-Math-7B와 OLMo2-7B의 behaviors discrepancy를 이해하기 위해, MATH-500에 대한 reasoning traces를 평가함.
- Qwen2.5-Math-7B는 code execution environment가 아님에도 불구하고, 자신의 thinking process를 돕기 위해 자주 Python 코드를 생성함 (65.0% of all responses) → Code Reasoning
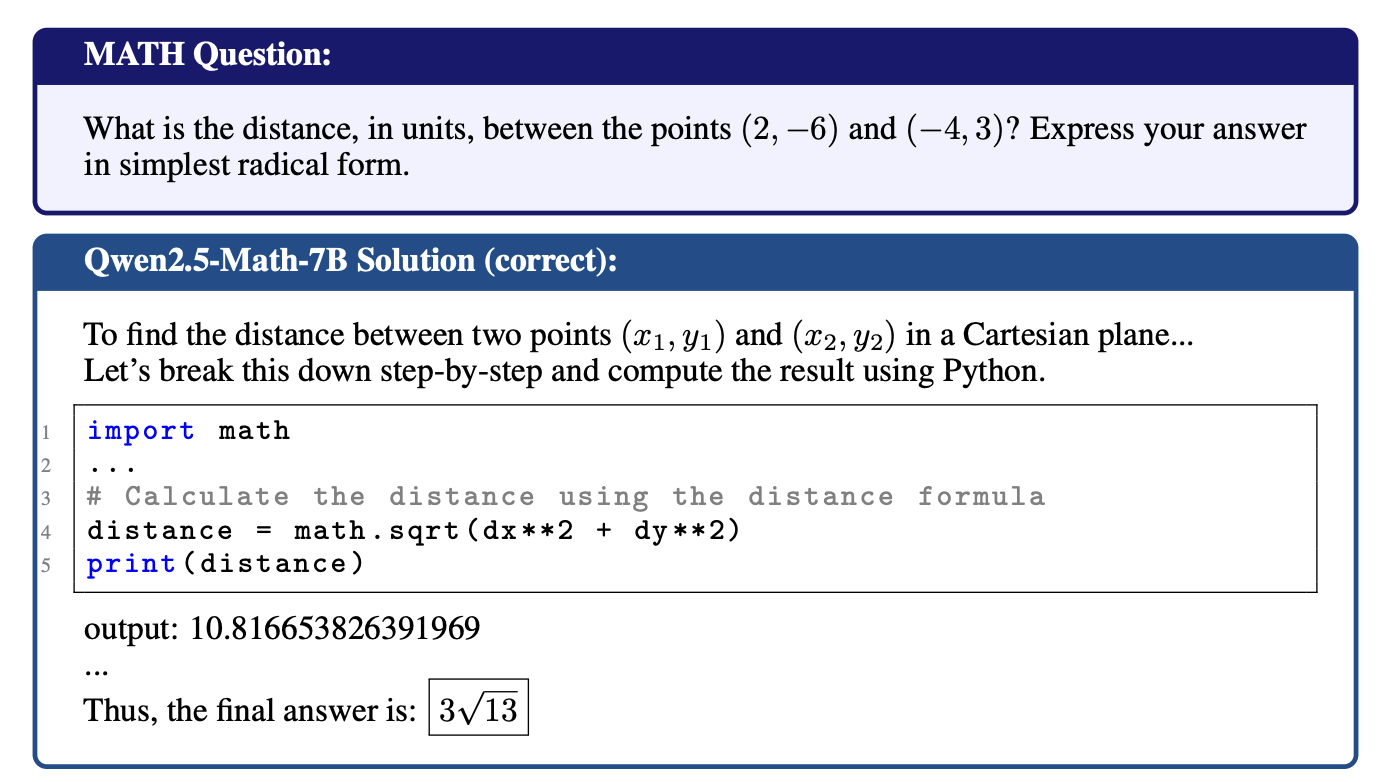
-
Code Reasoning 현상은 단순히 model의 memorization이라고 볼 수 없는게, 문제에서 숫자만 바꿔도 accuracy를 유지하는 현상을 보여줌.
-
문제가 다른 서술 형태로 재구성되면 Code Reasoning 현상을 보여주지 않고, 틀린 정답을 도출함

→ Qwen2.5-Math-7B가 pretraining 과정에서 많은 code-assisted math reasoning traces를 접했을 것이라 추정함
- Code 사용은 answer correctness를 강하게 예측하는 것을 보여줌

-
Qwen2.5-Math-7B/1.5B 둘 다 Acc. w/Code가 Acc. w/Lang 보다 유의미하게 높은 성능 보여줌
- 두 모델은 동일한 corpus로 pretraining 진행됨
-
다른 계열의 models에서는 이러한 현상이 나타지 않음 → No-Code / Bad-Code
-
No-Code: Llama, Qwen2.5-1.5B, OLMo2-7B는 Code Frequency가 0%
-
Bad-Code: OLMo2-7B-SFT, Qwen2.5-7B는 Code Frequency가 90% 이상으로 매우 높지만, 오히려 성능 악화로 이어짐
-
→ Effective Code Reasoning은 RLVR 학습 이전에 Qwen2.5-Math models이 갖는 unique capability라고 볼 수 있음
4.2 RLVR with Spurious Rewards Can Upweight Pre-existing Reasoning Strategies
Section 4.1의 결과에 따라 RLVR training에 걸친 model의 reasoning behavior를 다음과 같이 분석함
-
Accuracy: MATH-500의 평균 accuracy
-
Code reasoning frequency: model 응답에서 “python” string을 포함하는 비율
Performance is correlated with code reasoning frequency
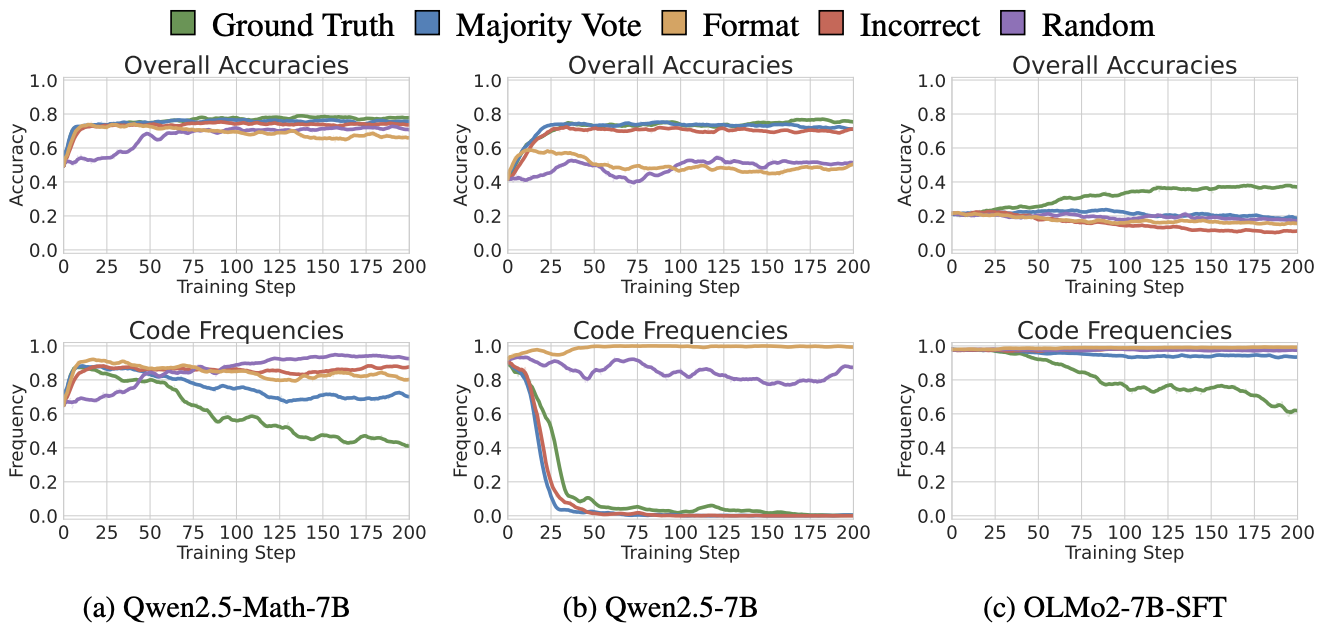
-
Qwen2.5-Math-7B는 RLVR training 이후에 초반 15 steps에 reward에 상관없이 code frequency가 대략 90%로 보여주며, accuracy improvements와 강한 상관관계를 보여줌 (뚜렷한가..?)
-
Random Reward는 비록 초반에 낮은 수치를 보여주지만, 후반부에 가서 95.6% 찍음
-
Ground Truth를 reward로 RLVR을 수행할 때, code frequency는 급격히 증가하지만, model의 natural language reasoning accuracy가 올라감에 따라 감소하는 경향을 보여줌
-
→ RLVR 중에 model은 high-quality ground truth reward로부터 real knowledge를 학습함
- Bad-Code 모델은 뚜렷한 상관관계를 보여주지는 않다고 주장하지만, 대체로 음의 상관관계 보여줌
Reasoning strategy switches during RLVR
-
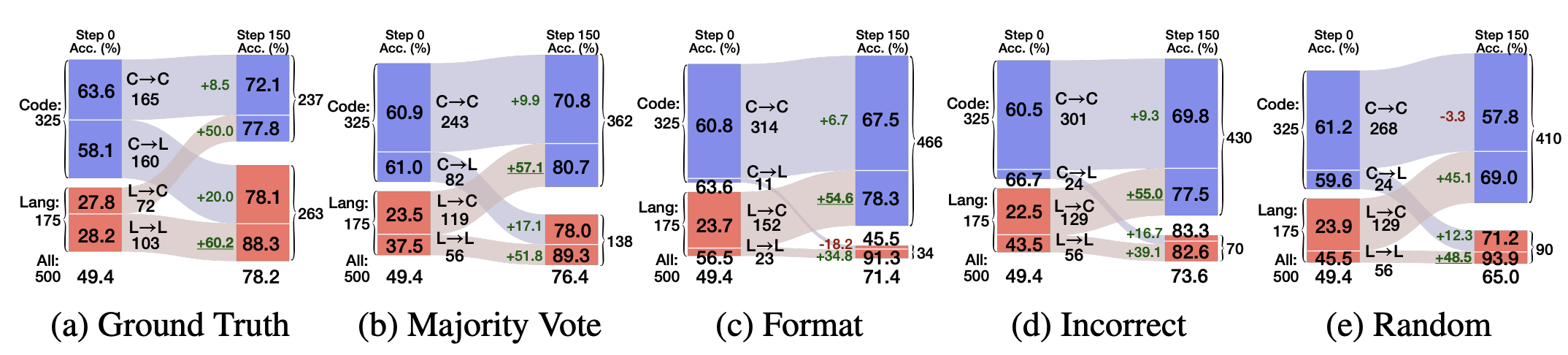
Qwen2.5-Math-7B의 accuracy 향상을 세분화하여 분석하기 위해, 각 reward signal로 학습한 model의 성능을 다음과 같이 설정하여 분석함 (test prompt를 4개의 베타적인 subset으로 나눔)
-
Code → Code: RLVR 전후 모두 code reasoning 사용
-
Code → Lang: 초기에는 code reasoning 사용, 이후에 natural language reasoning 사용
-
Lang → Code: 초기에는 natural language reasoning 사용, 이후에 code reasoning 사용
-
Lang → Lang: RLVR 전후 모두 natural language reasoning 사용
-
**Partial Contribution Score **C_d: test set D의 subset d에 대한 부분 기여 점수를 이용하여 각 subset이 성능 향상에 기여한 정도를 정량화 시킴
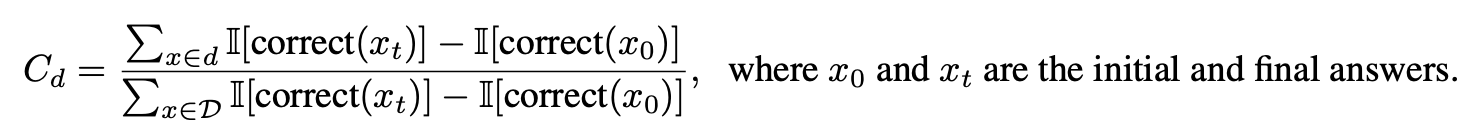
Frequency
-
각 reward signal 별로 Qwen2.5-Math-7B의 reasoning strategy switches를 보면,
-
weak/spurious rewards에서 RLVR 이후에 code reasoning을 많이 사용함 (C → L cases는 적지만, L → C cases는 상대적으로 많음)
-
Ground truth reward는 상반된 결과를 보여줌 (L → C cases < C → L cases)
-
-
Section 4.2 결과와도 일맥상 통하는 결론
-
Bad-Code 모델에서 (Qwen2.5-7B, OLMo2-7B-SFT) meaningful reward (ground truth, majority vote)는 model로 하여금 bad code reasoning으로부터 멀어지게 함 (위에 Figure 참조)
-
(No-Code 모델에서 RLVR은 reasoning strategy에서 meaningful changes를 보여주지 못하는데, 이는 pretraining 과정에서 해당 capability 자체가 학습되지 않았기 때문)
-
Accuracy
- 위 Figure 보면, L → C subset의 accuracy가 모든 reward에서 RLVR 이후 큰 성능 향상을 보여줌
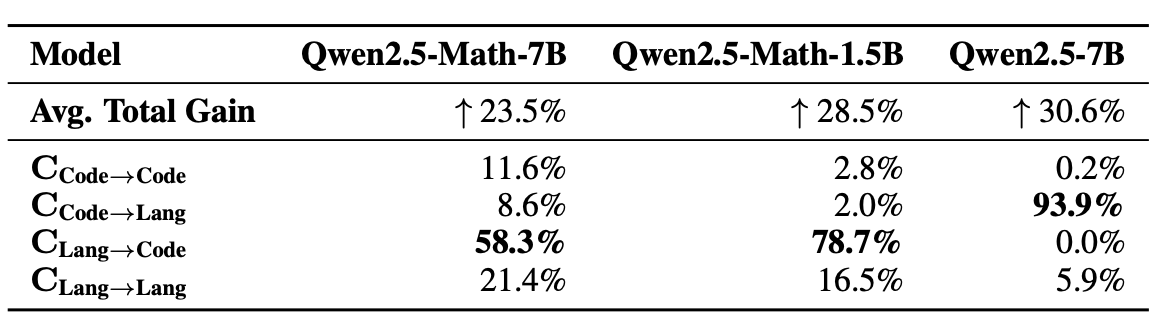
→ Qwen2.5-Math-7B/1.5B의 성능 향상의 58.3% / 78.7%은 L→C case가 차지함
- Bad-Code model인 Qwen2.5-7B에서 성능 향상은 C → L case가 93.9% 차지함
→ 이 model은 language reasoning accuracy가 code reasoning accuracy보다 높기 때문에, **RLVR training은 결국 model이 더 잘하는 strategy를 이용하도록 학습됨 **(즉, prior knowledge에 대한 dependency가 있다고 생각함)
4.3 Intervening Explicitly on Code Reasoning Frequency
Section 4.2와 4.3에서 RLVR 동안 code reasoning frequency가 증가하고, 이는 test performance의 향상과 상관관계가 있다는 것을 실험적으로 보여줌. 이번 Section에서는 Code reasoning의 빈도를 more / less 명시적으로 유도하며, causal impact를 분석함
*Hypothesis**: spurious reward로 학습할 때, code reasoning 증가가 Qwen2.5-Math-7B의 성능 향상의 주된 원인중 하나가 맞다*
→ 해당 hypothesis가 맞다면, code reasoning frequency에 intervention을 하는 것은 그에 상응하는 성능 향상 혹은 감소를 일으켜야함.
Code reasoning을 유도하면 Qwen2.5-Math의 성능이 향상되는 반면, 다른 모델들은 반대 경향을 보여줌.
-
Prompting과 RLVR 학습을 통해 code reasoning을 유도함
- Prompting: “Let’s solve this using Python” 명시적으로 강제함
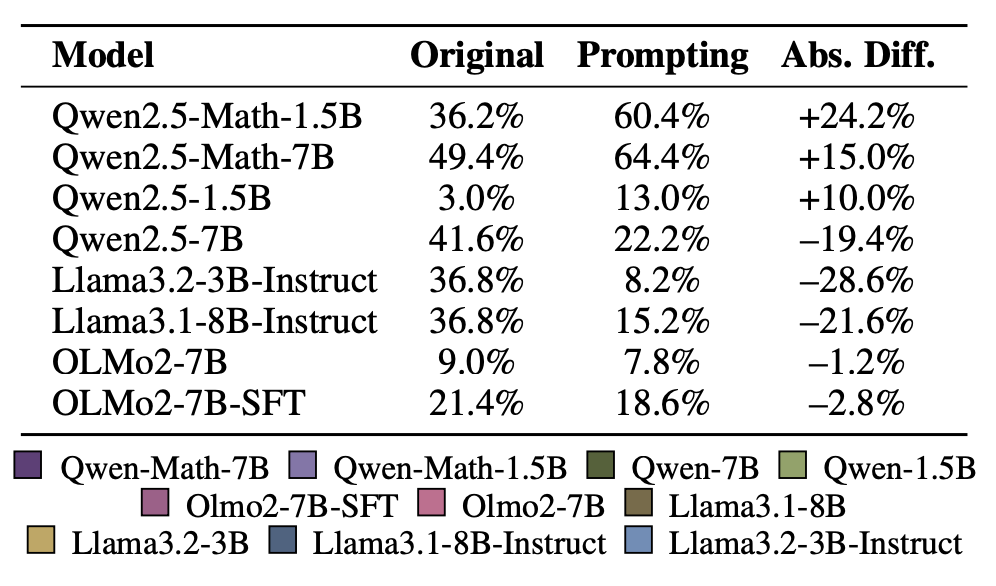
- No-Code models은 성능 하락을 보이는데, 이는 해당 계열 models이 effective code reasoning behavior를 보여주지 않음 (Section 4.1 실험 결과와 일치)
- RLVR: response에 “python” string을 포함할때만 + reward 부여함
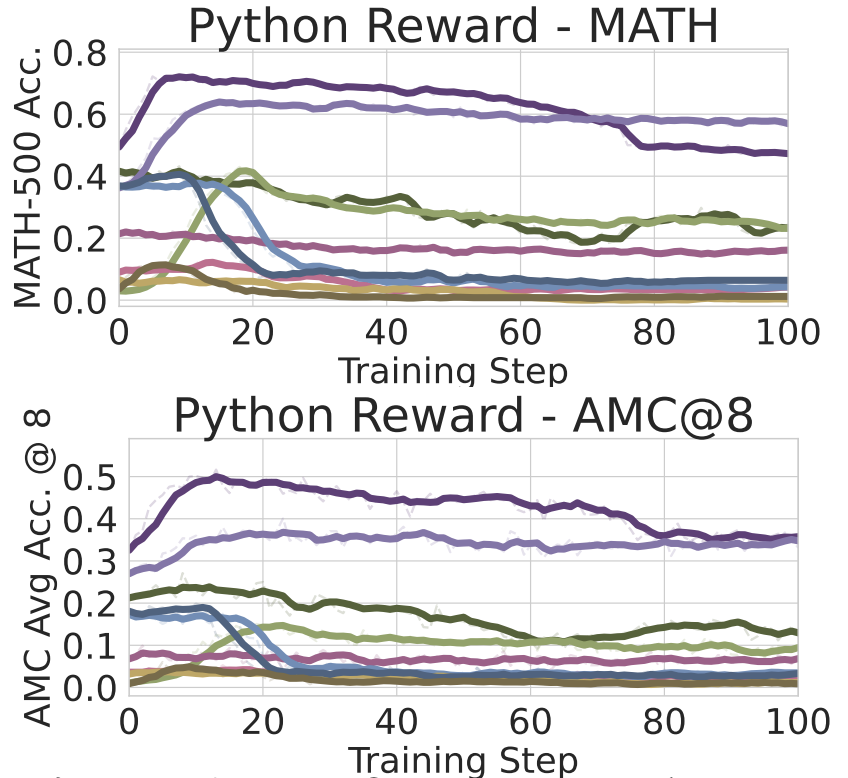
- Qwen2.5-Math-7B는 20 training steps부터 code reasoning frequency가 99% 이상 비율
- Qwen2.5-Math에서만 유의미한 성능 향상을 보여주고, 다른 모델에서는 그렇지 않은 결과를 보임
반대로 RLVR 중 code reasoning을 억제하면, Qwen2.5-Math-7B에서 성능이 줄어들고, 다른 models에서는 향상될 수 있음.
위 Hypothesis에 대한 대우명제를 검증하는 실험을 진행함
-
대우: “Code reasoning에 penalty를 주면 spurious reward로 인한 성능 향상이 감소할 수 있음”
-
실험 세팅으로는 compound rewards를 설계함 (아래 두가지 조건 모두 만족할 때 reward 부여)
-
원래의 spurious rewards를 만족
-
response에 “python” string이 없을 때
-
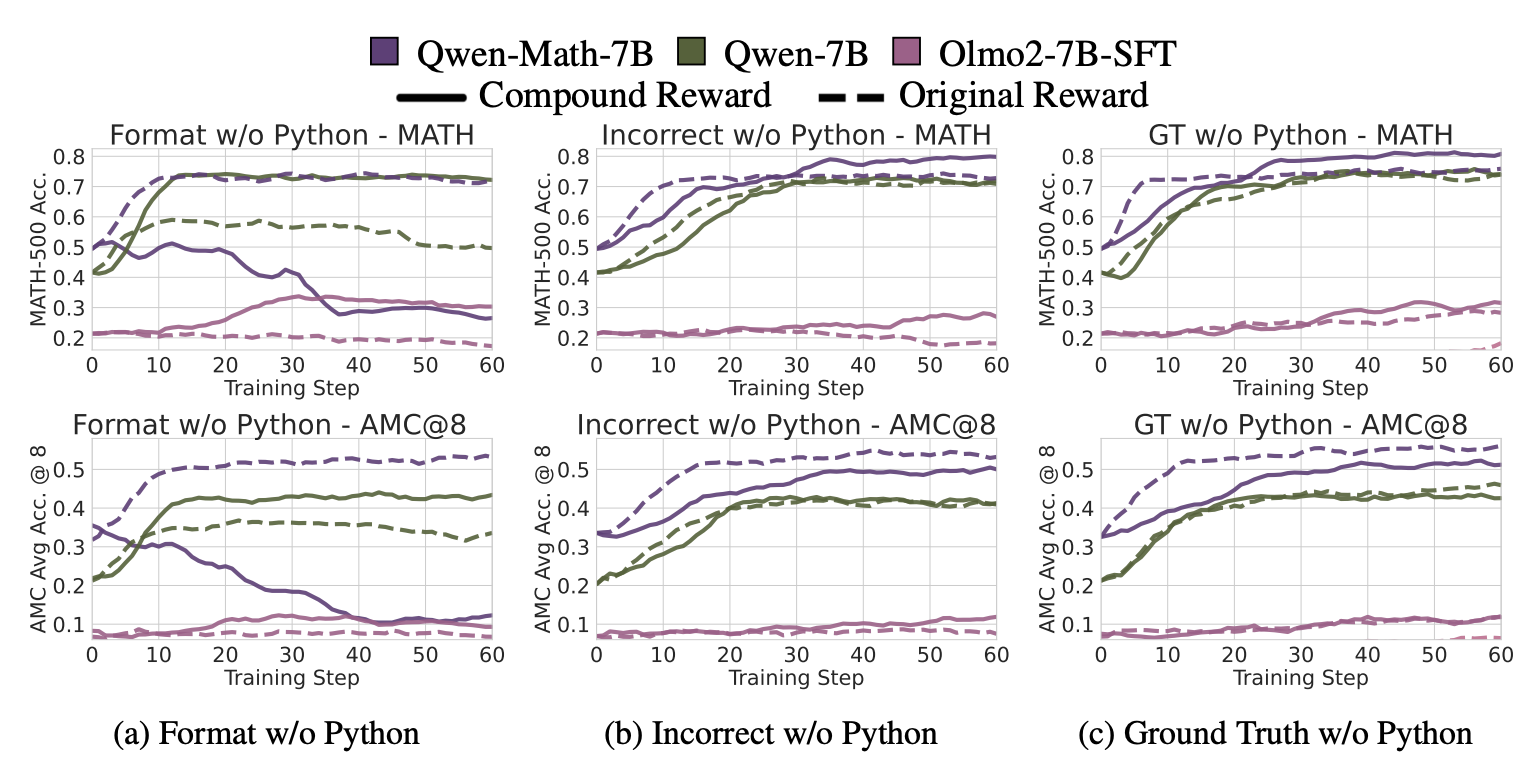
-
format reward와 no-code reward가 compound된 Figure (a)를 보면, Qwen2.5-Math-7B는 성능이 하락함 → hypothesis와 일치한 결과 (웃긴게 여기만 제대로 일치함 ㅋㅋ)
-
Incorrect reward에서 MATH-500은 Compound reward와 Original reward가 비슷한 수준으로 성능이 나오는 반면, 더 어려운 task인 AMC에서는 성능 향상의 폭이 줄어듬
→ code reasoning을 제거하면, spurious reward의 performance gain이 줄어듬
- ground truth reward에서는 성능 향상을 보여주는데, 이는 앞에서 code reasoning frequency가 줄어듬에 따라 real knowledge를 배워 성능이 개선되는 결과와 consistent함
(???: 그런데, Incorrect reward와 GT reward에서 Qwen-Math-7B trend는 비슷한거 아닌가..? 최종 acc까지 비슷한 수준임. Format reward하고 일관된 trend가 보이지 않음..)
- Bad-code models (Qwen2.5-7B, OLMo2-7B-SFT)는 Compound reward가 original reward보다 더 높은 성능을 보여줌 → 이는, bad-code models이 weak code reasoning을 보이기 때문에, Compound reward가 model이 못하는 behavior의 weight를 명시적으로 낮춰 학습을 유도함.
4.4 The Curious Cases: Training Signals from Incorrect Rewards and Random Rewards
그러면 Spurious Rewards가 어떻게 RLVR에서 meaningful training signal을 만들어내는가?
Incorrect Rewards
저자들은 incorrect rewards가 effective training signals을 만드는 다음 두 가지 포인트를 가정함
-
많은 incorrect labels이 ground truth 값에 가까운 값으로 남아 있어, 대체로 올바른 reasoning에 positive reinforcement를 제공함
-
Incorrect labels may function like format rewards
- models은 생성된 response를 성공적으로 추출하고 평가하지 않으면 reward를 줄 수 없기 때문에, 일정 수준의 correct reasoning이 필요함
→ 말로 가정만 하고… 정작 이를 검증하는 실험이 없네요….ㅋㅋ
Random Rewards
혹자는 Rewarded answers 다수가 correct하기 때문에, Qwen2.5-Math의 성능이 개선되었다 볼 수 있음.
→ GRPO는 reward의 평균을 0으로 normalize하기 때문에, rewarded answers가 대부분 정답이라면, penalty answers도 대부분 correct하기 때문에 (penalized responses 중에도 correct 다수 포함), 위에 말은 틀림.
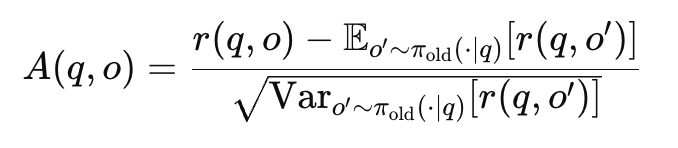
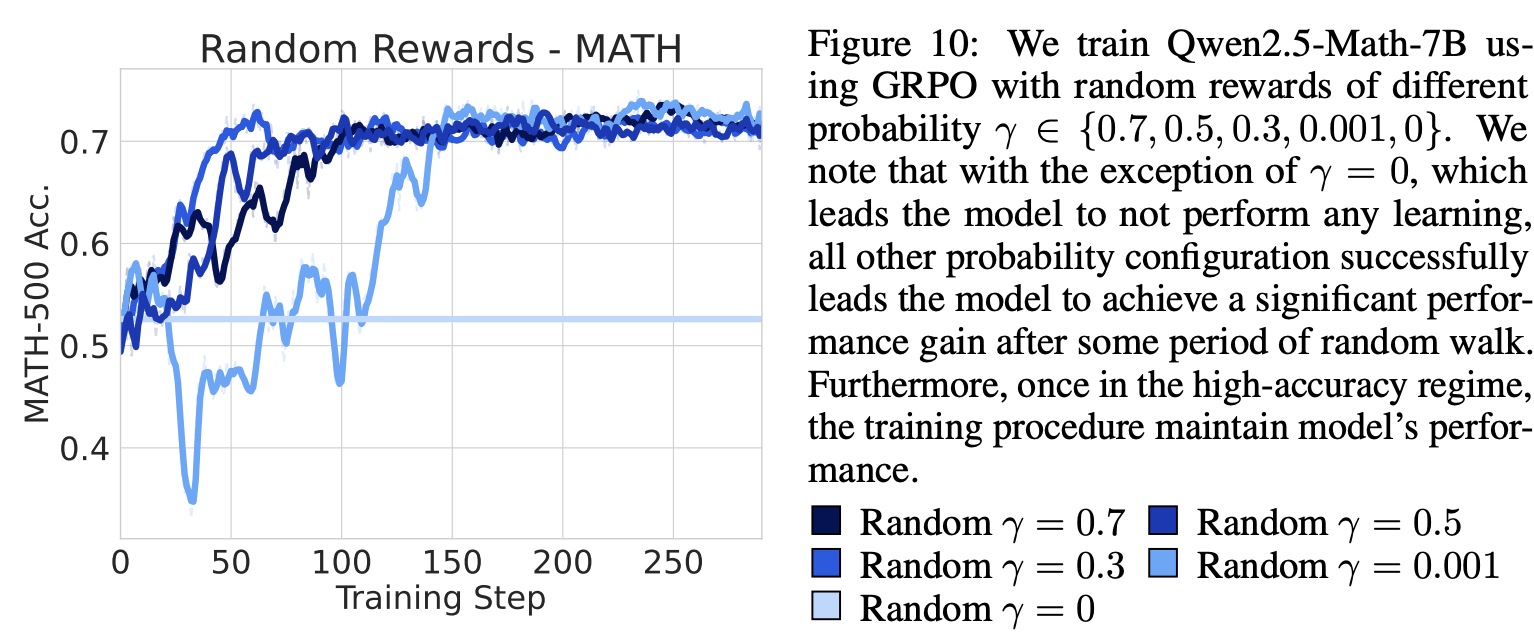
Random rewards with varying probabilities consistently improve performance
-
GRPO training에서 *Bernoulli(\gamma) *variable로 random rewards를 보여함
-
\gamma 가 0이 아닐 때는, 유의미한 성능 향상을 보여줬고 (15~20% 향상), 0일 때는 constant rewards가 learning signal을 만들지 않아 개선이 없음.
- \gamma가 0이면, Reward가 0이고, 그럼 모든 rollout의 Advantage 역시 0이고 → gradient=0이라 학습x
GRPO clipping bias can induce random reward training signals
GRPO는 gradient updates에서 reward에 대해 normalized group-relative advantage를 계산함. 이때, batch rollouts에 대해 normalize를 하기 때문에, advantage의 expectation은 0임.
→ 그런데, GRPO의 clipping mechanism 때문에, 실제로 advantage의 expectation은 0이 아님.
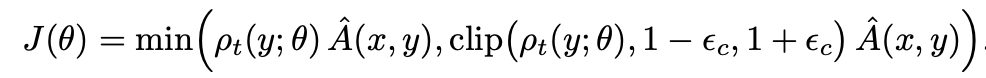
- \rhot=\pi{\theta}(y)/\pi_{old}(y) → 1-\epsilon < \rho_t < 1 + \epsilon
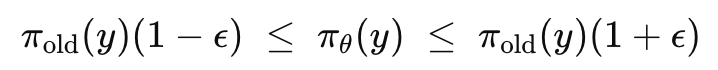
-
확률이 높은 token에 대해서는 clip에 걸리는 경우가 거의 없어, update는 대부분 +방향으로 이루어짐
-
확률이 낮은 token에 대해서는 범위가 좁아 clip에 쉽게 걸려, 조금만 확률을 늘리면 penalty (-gradient)가 들어옴 → 낮은 확률 token에 대해서는 키우기가 어려움
-
Example
-
\pi_{old}(y)=0.85, \epsilon=0.2
- clip range = [0.85 x 0.8, 0.85 x 1.2] = [0.68, 1.02]
-
-
→ prob은 1을 넘을 수 없어 실제 상한은 1.0이므로 구간의 폭은 0.32
- \pi_{old}(y)=0.02,\epsilon=0.2
- clip range = [0.02 x 0.8, 0.02 x 1.2] = [0.016, 0.024]
→ 구간 폭은 0.008 (매우 좁기때문에, 조금만 확률이 늘어나도 clip에 걸려 gradient가 0이 되거나 penalty 발생 → 확률을 키우기 어려움)
→ clipping으로 인해 비대칭이 생겨, advantage expectation은 0이 아니고, model이 원래 자주 생성하는 token들로 probability mass가 쏠리는 현상 발생 (model의 prior knowledge를 강화하는 방향으로 bias 생김)
-
높은 token 확률은 clipping에 잘 안걸려 → +gradient 누적
-
낮은 token 확률은 clipping에 잘 걸려 → -gradient 누적
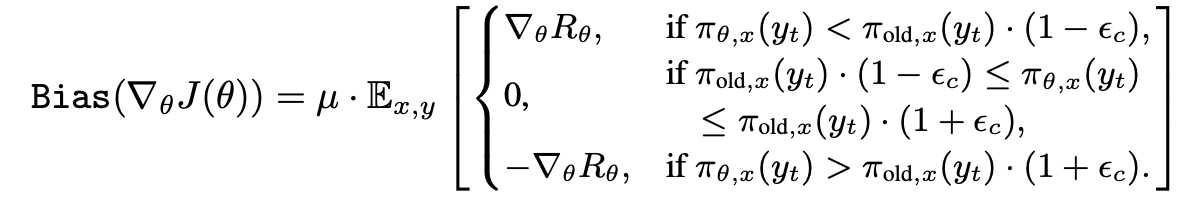
→ 즉, random reward에서도 clipping bias가 prior knowledge에 기반한 behavior를 강화함 (아래 실험 결과로도 보여줌)
Dapo: An open-source llm reinforcement learning system at scale, 2025
- 위 연구에서도 clipping bais가 RLVR에서 exploration을 줄이고 exploitation을 늘린다는 것을 발견함
추가로 GRPO에서 clipping effect를 실험적으로 검증을 함
-
clipping 효과를 제거하기 위해, clipping bias를 없애는 설계를 구현함
-
loss calculation에서 clipping bias를 직접 제거
-
training 및 rollout batch size를 조정하여 \pi{\theta}=\pi{old}를 보장하며, clipping이 발생하지 않도록 함
-
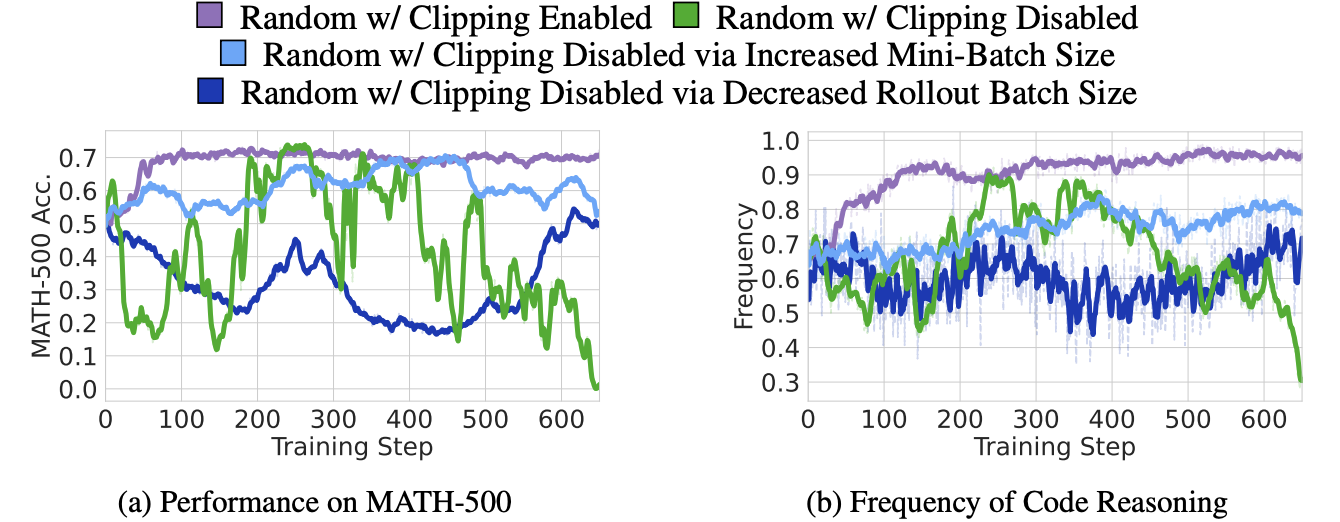
-
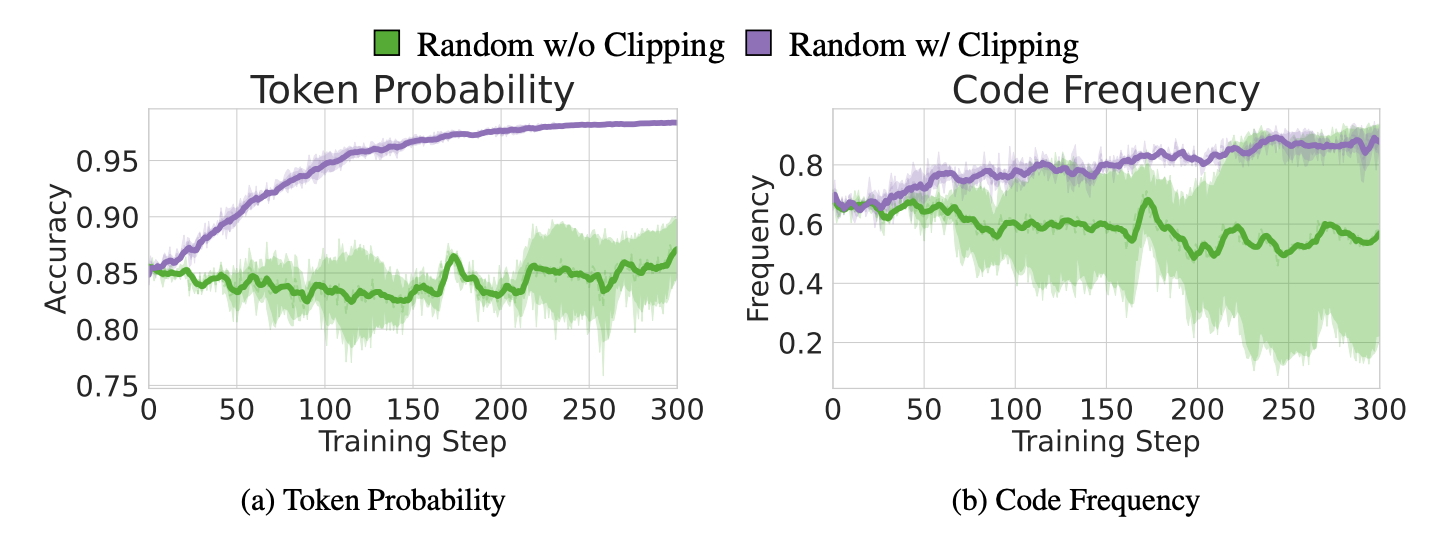
Random w. Clipping Enable (GRPO)에서 random reward가 code reasoning frequency를 높임.
-
w. Clipping Disabled case를 보면, 이러한 reasoning pattern trend가 사라짐
→ Clipping을 사용하면, 이에 따라 성능 향상으로 이어짐
5. Conclusion
본 연구에서는 Weak / Spurious Rewards를 사용한 RLVR이 Qwen-2.5-Math에서 유의미한 성능 개선을 보여주는데, 이는 existing reasoning patterns을 증폭함으로써 이루어진다는 것을 설명함.
본 연구의 다양한 실험을 통해 아래 3가지 주요 포인트를 강조함.
-
Base model pretraining은 RLVR 결과에 큰 영향을 미침
-
Spurious supervision도 유의미한 existing behaviors를 촉발할 때 reasoning을 향상시킬 수 있음
-
특정 model 계열의 결과가 다른 계열의 model로 일반화 되지 않음
본 연구가 제시하는 기준은 다음과 같음
-
서로 다른 pretraining distribution을 가진 여러 model에 대해서 RLVR을 검증
-
RL을 평가할 때, 다양한 reward를 baseline으로 두어 비교
아쉬운점..?
-
전반적으로 잘 설계된 많은 실험과 흥미로운 결과들을 보여줘서 인정하지만, 몇몇 부분에서는 다소 비약이 있다고 생각함.
-
Spurious Reward가 다른 계열의 모델에서는 잘 나타나지 않고, Qwen2.5-Math에서만 강하게 나타나는 것으로 보아, 해당 계열 model의 특수성일 수 있음. 즉, RLVR이 latent capability를 trigger한다는 주장은 일반화하기 어려움
-
random reward가 왜 작동하는지 설명하는 부분에 있어서, 변인통제가 제대로 이루어지지 않음. 다른 bias로 인해 영향을 받았을 수도 있음
-
Math 이외의 domain (ex. code, language reasoning) tasks에 대해서 어떻게 나타는지 분석이 아쉬움
-
실험 전반의 RLVR training steps이 50~100 steps에서 saturation이 이러나는데, long-term stability 검증이 부족함 (catastrophic forgetting 혹은 overfitting issue에 어떻게 되는지)