SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
논문 정보
- Date: 2025-03-04
- Reviewer: 전민진
- Property: RL
SWE-bench에서도 rule-based RL이 높은 성능을 보임!
RL위주로 간단하게만 정리
Abstract
-
DeepSeek-R1 출시 이후, RL이 모델의 일반적인 reasoning ability 끌어올릴 수 있다는 잠재력이 증명됨
- 하지만 DeepSeek-R1은 수학과 간단한 code에서만 적용
⇒ real-world software engineering에서도 될까?
-
real-world software engineering에 대해서 처음으로 RL-based LLM을 학습한 SWE-RL을 제안
-
간단한 rule-based reward(정답과 모델이 생성한 답변과의 유사도)을 활용해서 학습, SWE-RL은 in-domain뿐만 아니라 out-of-domain에서도 뛰어난 성능을 보임
Introduction
-
DeepSeek-R1은 rule-based RL이 용이한 도메인에 대해서만 학습, 실험 진행
-
수학의 경우 명확한 답이 존재, code의 경우 실행해보면 결과가 명확하게 나옴
- self-contained되고, 쉽게 실행할 수 있는 코드
-
단, 이러한 코드는 한정적, real-world SE task에 바로 적용하기는 어려움
-
-
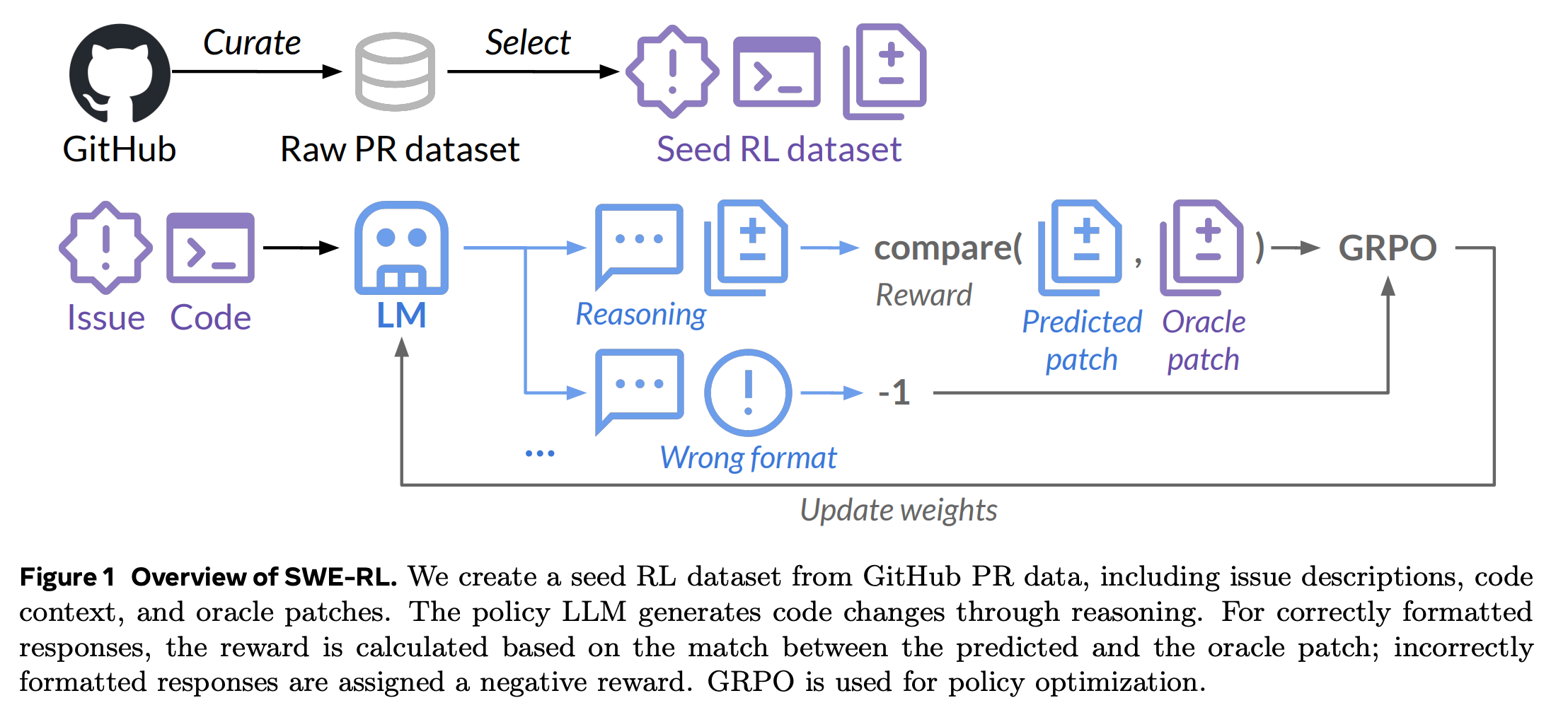
SE task에 대해서 LLM을 향상시키는 첫번째 RL method, SWE-RL을 제안
-
github에서 seed dataset 구축
- 각 학습데이터는 issue, code context, oracle patch로 구성
-
코드 변화(수정사항)은 일관된 patch format으로 변환, 정답과의 유사도를 기반으로 reward 매김
- difflib.SequenceMatcher 사용 (알파벳 기반으로 유사도 0-1사이로 측정) - 겁나 나이브
-
실험 결과, Llama3-SWE-RL-70B는 SWE-bench Verified에서 41.0%성능을 냄 (<100B 모델들 중에서는 최고 성능), 이 뿐만 아니라 학습과 직접적으로 관련이 없는 out-of-domain (function-level docing, practical code generation wtih library use, code reasoning, mathematics, general language understanding)에서도 성능이 크게 향상됨
-
SWE-RL

Raw pull request data curation
-
Github events and clones
-
2가지 정보를 포함하도록 데이터를 수집
- PR내에서 발생한 모든 event, PR에 의해서 merge 되기 전의 repo 소스코드
-
소스 코드를 얻기 위해서, Github API보다 git clone을 주로 사용 ⇒ 4.6M의 repositories를 수집
-
-
PR data aggregation ⇒ 자세한 내용은 원문 참고.. 이해 못했음..
-
각 PR을 개별적으로 보고, 그와 관련 있는 정보를 모두 합침
-
우선, merged PR을 유지, 각 PR의 관련된 conversational event를 수집, chronological order로 정렬
-
두번째로 base_commit과 head_commit을 사용해서, 수정된 파일 내용을 검색
-
마지막으로 각 합쳐진 PR를 보고 패턴 식별, 유사한 애들끼리 또 결합
-
최종적으로 24M의 PR instance를 얻음
-
-
Relevant files prediction
-
현재 모든 pull request는 수정된 파일만 포함됨
-
초기 실험에서, 이러한 데이터로 학습하니, LLM이 주어진 모든 코드를 수정하려고 함
-
이러한 문제를 해결하기 위해서, Llama-3.1-70B-Instruct로 PR과 관련 있지만 수정되지 않은 파일을 생성하도록 prompt
-
-
Data filtering
-
우리의 목표는 어느정도 노이즈가 있는 상태에서 고품질의 PR에 대한 recall을 최대화하는 것이기 때문에, 구린 데이터를 필터링
-
필터링 대상
-
bot이 생성한 PR제거
-
변화가 없거나 너무 많이 바뀐 PR
-
이외에 CodeLlama로 좀 더 섬세하게 필터링(e.g., with only lock file changes or version updates)
-
-
최종적으로 11M의 unique PR instance가 구축됨
- data = (issue, code context, oracle patch)
-
Reward modeling

- logic-RL과 유사하게 system prompt넣어줌, format이 틀릴 경우 -1을, 맞을 경우 정답과의 유사도를 계산해 reward를 줌

- loss식은 GRPO와 동일

-
SWE-RL에서의 학습을 살펴보면, 학습데이터에는 내재적으로 bug 진단, 수정사항 생성 task 2가지 정도만 커버
- 하지만 agentless mini(SE task에서 사용할 수 있는 Inference framework 정도로 이해)는 수정사항 생성을 넘어서, 파일 수준의 오류 탐지, test 생성 재현 등의 학습 범위를 벗어난 task를 수행하도록 하지만, 그래도 성능이 높게 나옴!
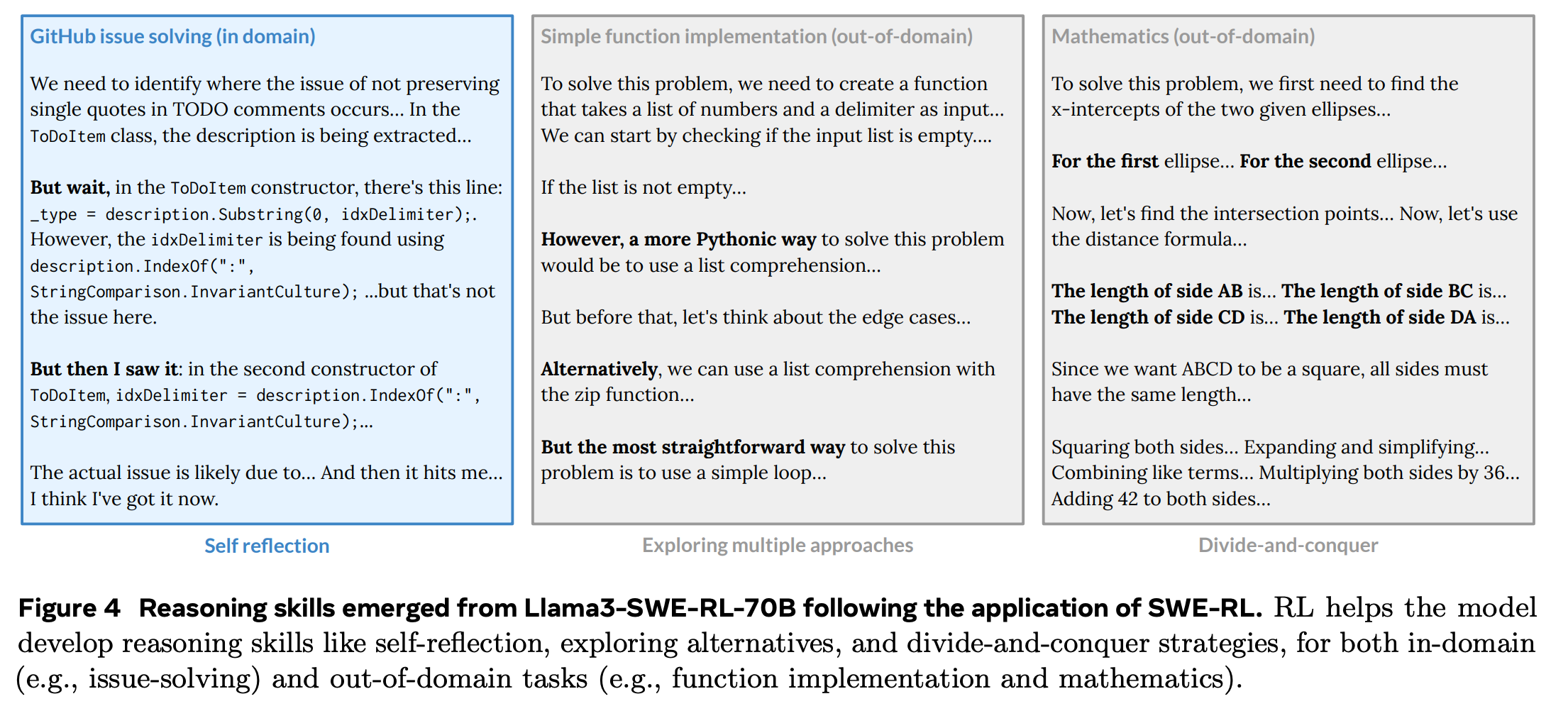
Aha Moments and generalized reasoning capabilities
- SWE-RL에서도 아하모먼트(심화된 reasoning ability)가 나타남, 특히 SE task에서 필요한 reasoning ability가 아니라 범용적인 reasoning ability(self reflection, exploring multiple approaches, divide-and-conquer)등이 발현됨
Evaluation
Experimental Setup
-
Training configs
-
Llama-3.3-70B-Instruct를 기반으로 Llama3-SWE-RL-70B를 학습
-
1600 steps with 16k context window
-
global batch size 512, sampling 16 rollouts from each of the 32 problems in every batch
-
For every global step, a single optimization step is performed
-
-
-
Scaffolding
-
Agentless를 기반으로 Agentless Mini를 게발
-
Agentless의 multi-step localization과 달리, mini에서는 file-level localization에만 집중, 전체 파일을 제공하고 detailed reasoning을 repair step에서 수행
-
(자세한 내용은 원문 참고)
-
Evaluation setup
-
SWE-bench Verified로 평가
- SWE-bench에서 사람이 검증한 500개의 문제
-
각 문제마다 500개의 patch생성(with 1.0 temperature), execution과 reranking에서 top 30 reproduction test를 사용, 최종적으로 1등 patch를 pass@1 score를 계산하기 위해 사용
-
-
SFT baseline
-
학습 방법의 차이를 분석하기 위해 Llama-3-SWE-SFT-70B도 학습
-
seed dataset으론 동일한 데이터셋 사용, SFT는 데이터셋 다양상과 모델 일반화 성능을 보장하기 위해 다양한 CoT, mixture data필요 ⇒ PR data with CoT, Llama3 coding SFT data, Llama 3general SFT data등을 섞어서 학습
-
Main results
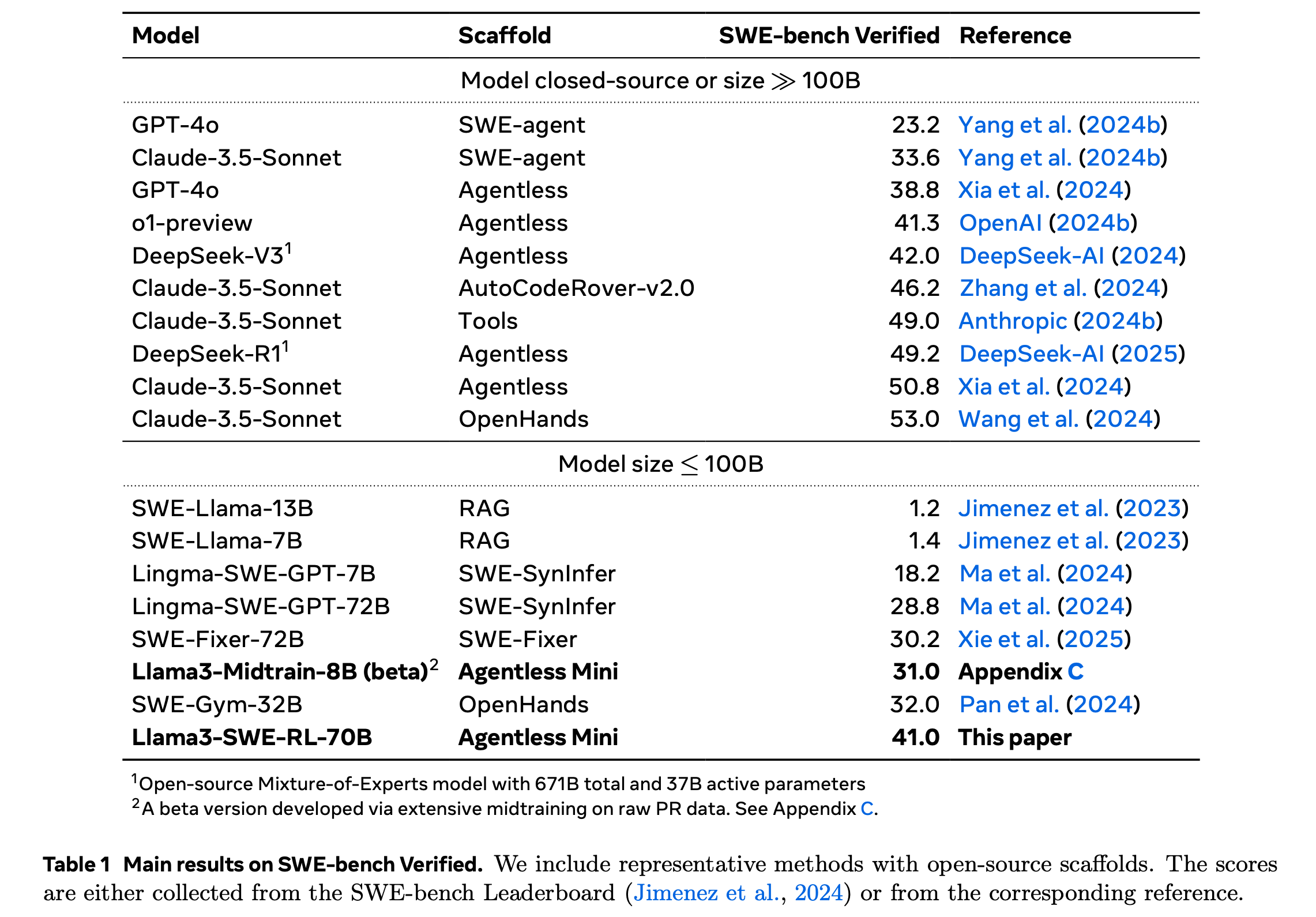
-
GPT-4o 혹은 Claude-3.5-Sonnet의 결과를 Distillation한 Lingma-SWE-GPT, SWE-Gym, SWE-Fixer 등을 비교군으로 사용
-
distillation data 구축 없이도 성능 압도
Baseline comparison
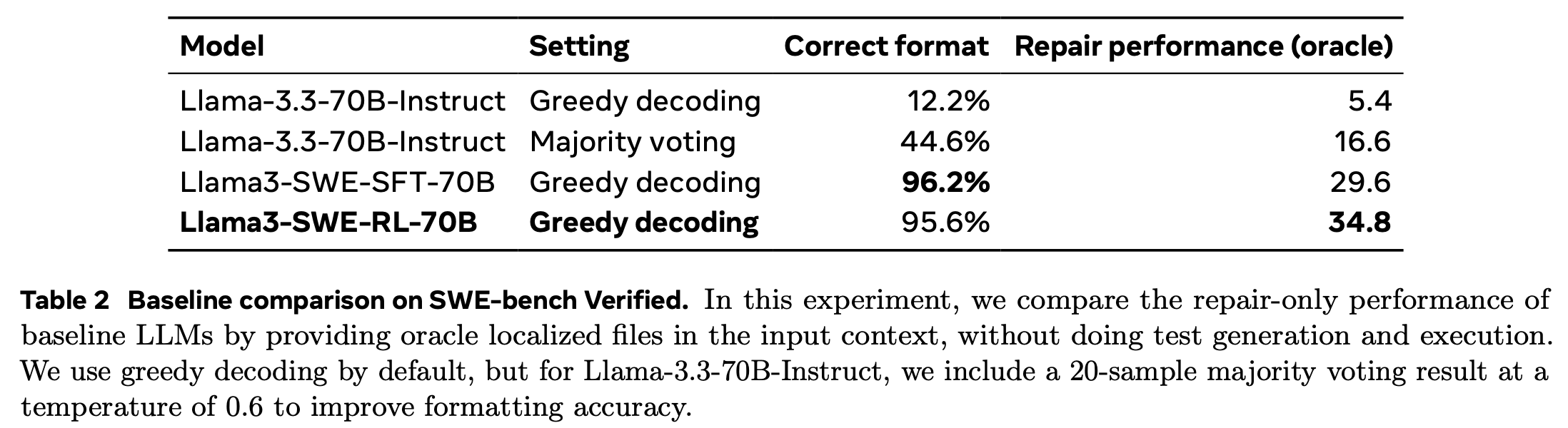
-
Repair performance에 집중해 성능 분석
-
Llama-3.3모델은 20개 샘플링해서 다수결해도 formatting에 어려움을 겪음
-
RL은 formatting도 잘하면서 repair performance도 우수
Scaling analysis with more samples
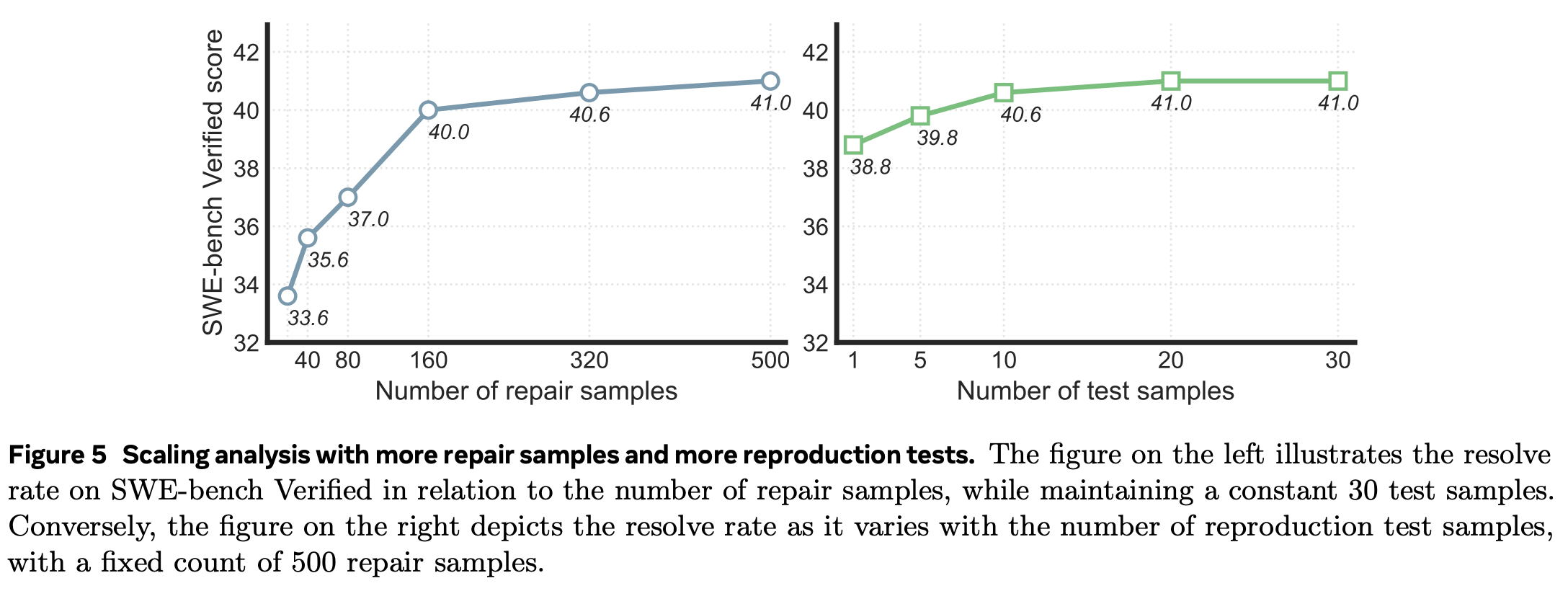
-
repair sample, test sample의 수를 조절하면서 성능 비교
-
어느정도 큰 수가 되면 성능이 수렴
Generalizability of RL
-
SWE-bench 외에도 function coding, library use, code reasoning등의 code 도메인의 다른 task에서도 성능이 향상됨
-
대단한건 MATH 성능이 크게 향상, MMLU 성능을 잃지 않음..!!!
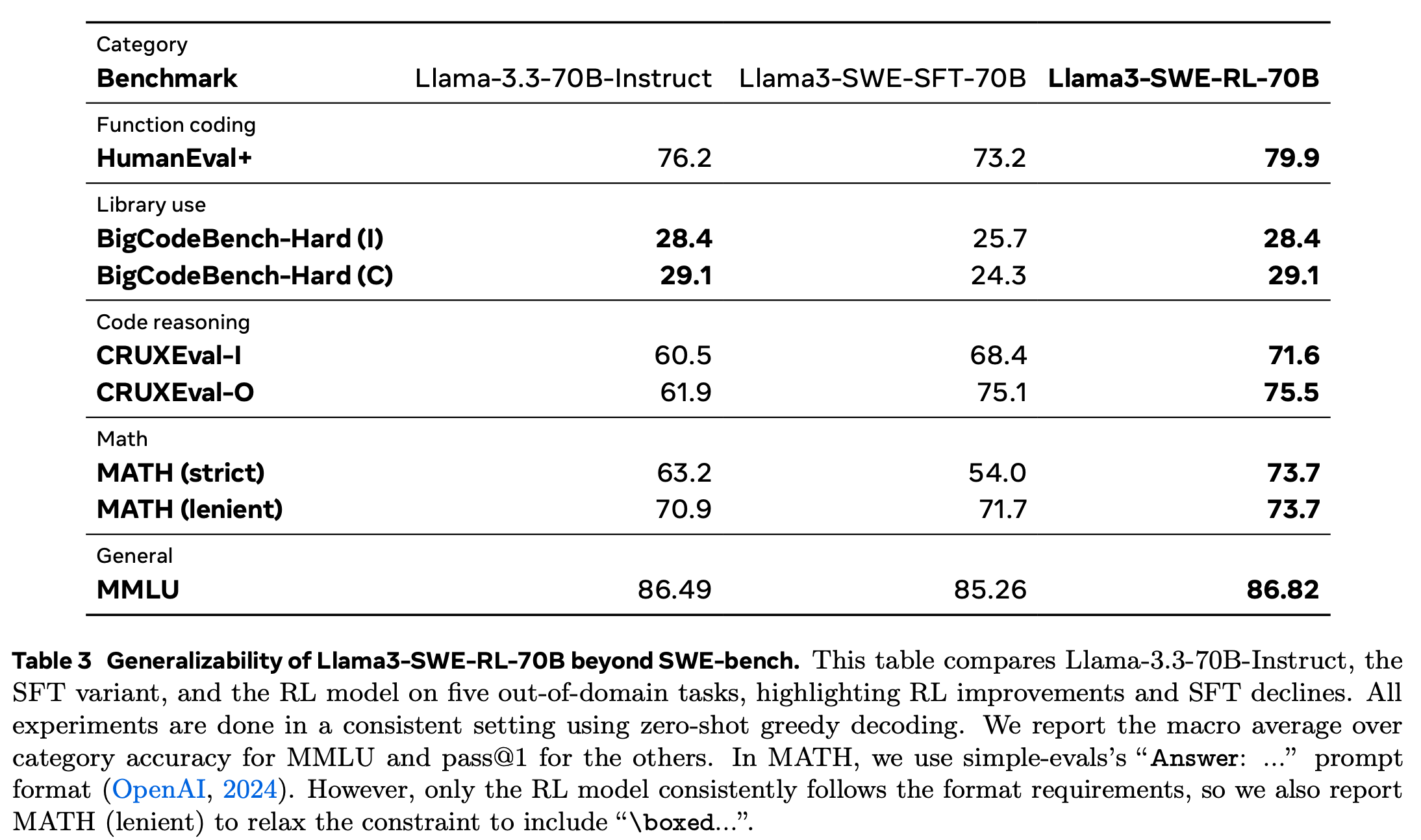
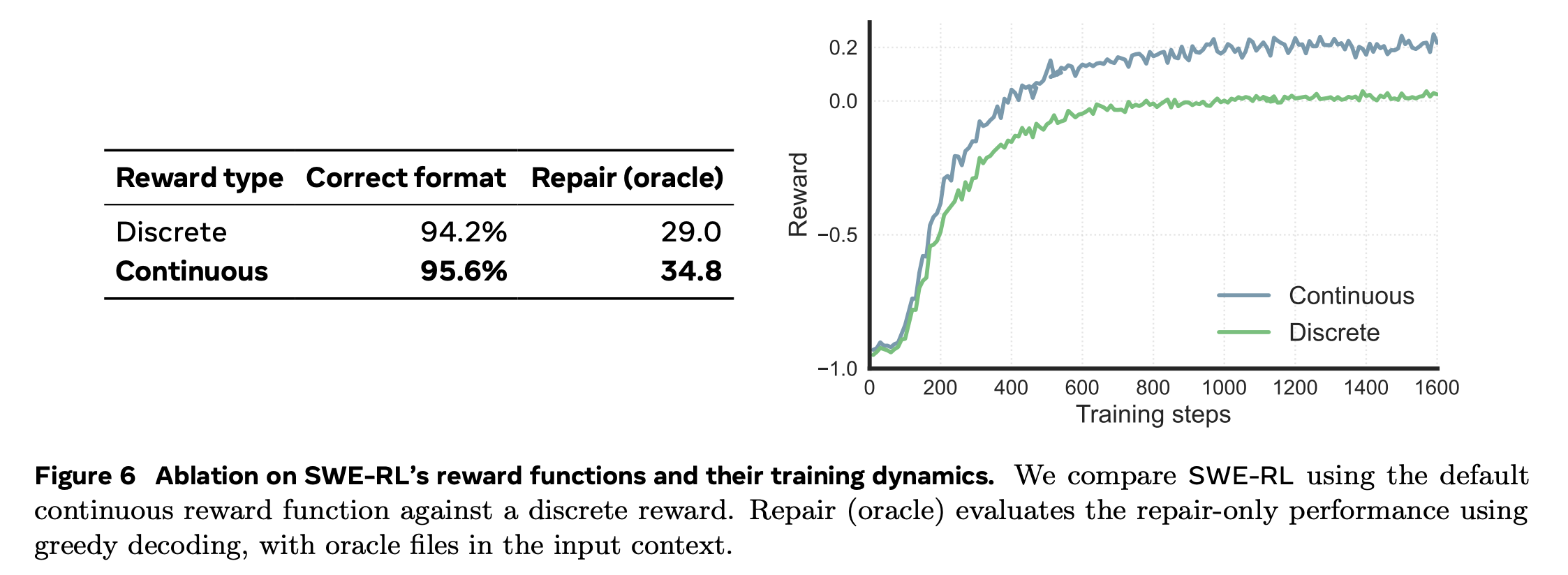
Reward ablation
-
reward를 0-1사이의 continuous값이 아니라 discrete한 값으로 주었을 때의 결과
-
continuous가 낫다!