Textgrad: Automatic “Differentiation” via Text
논문 정보
- Date: 2025-06-03
- Reviewer: hyowon Cho
오늘은 평소의 리서치 관심사와는 달리, 회사에서.. 리서치를 요청한 분야에 대한 논문을 한 편 가져왔습니다.
오늘의 도메인은 Automated Prompt Engineering (APE) 입니다. 프롬프트 작성하는 기계가 되는 최근 AI application 시장에서 어찌보면 수요가 낭낭한 연구 분야라고도 할 수 있겠습니다-
도메인 자체는 다들 엄청 흥미있어 하지는 않을 것 같지만, 아직 보완할 부분이 많이 보여서 분석+실험 설계만 잘 한다면 후속 논문 쓸 때는 재미있을 것 같은 연구였어요. 저는 개인적으로 연구 방향에 동의해서 재밌었슴다.
더불어서, nature에 NLP 연구가 요새 종종 보이는데, 어떤 유형이 accept되나 궁금증 겸사겸사 해소도 되고, 역시 연구는 프레이밍이 중요하다라는 것을 느낀 연구입니다.
거두절미 하고 들어가보죠
1. Introduction
LLM의 발전으로 인해 AI 시스템을 구축하는 방식에 패러다임 변화가 일고 있습니다. 하지만 이 중 많은 breakthroughs는 특정 도메인의 전문가들이 수작업으로 만든 시스템과 heuristic한 튜닝을 통해 이뤄졌습니다. 따라서 LLM 기반 시스템을 제대로 구축하려면 이를 자동으로 최적화할 수 있는 방식이 필요합니다.
과거 15년간의 AI 발전은 대부분 인공신경망과 미분 가능한 최적화에 기반했죠. 두 뉴런 사이를 연결하는 연산은 행렬곱처럼 미분 가능한 함수이고, 역전파(Backpropagation)는 그 구조 내에서 parameter를 조정하는 방식이었습니다. PyTorch 등 자동 미분 프레임워크가 필수였던 이유도 여기에 있죠.
이번 논문에서는 AI 시스템을 최적화하기 위해 TEXTGRAD라는 개념을 소개합니다. 여기에서 우리는 미분(differentiation)과 그래디언트(gradients)를, LLM이 제공하는 텍스트 기반 피드백에 대한 은유적 표현으로 사용합니다.
TEXTGRAD는 AI 시스템을 계산 그래프로 표현하고, 각 노드(변수)에 대해 LLM으로부터 자연어 피드백을 받아 이를 “텍스트 그래디언트(textual gradient)”로 간주합니다. 이후 이 피드백을 그래프 구조를 따라 역방향으로 전파(backpropagation)하며, 각 변수(프롬프트, 응답 등)를 업데이트합니다. 이 과정은 LLM API 호출, 시뮬레이터, 외부 수치 해석기 등을 포함하는 복잡한 연산 구조에도 적용 가능합니다.
저자들은 다양한 도메인에서 TEXTGRAD를 적용한 결과를 보입니다:
-
코딩: LeetCode 문제에서 GPT-4o 및 기존 기법 대비 20% 성능 향상.
-
문제 해결: 과학 문제에 대해 GPT-4o의 zero-shot 정확도 51% → 55%로 개선.
-
추론: GPT-3.5 성능을 prompt optimization으로 GPT-4 수준으로 끌어올림.
-
화학: 약물 친화도 및 druglikeness가 높은 분자를 새로 디자인.
-
의료: 전립선암 방사선 치료 플랜을 최적화하여 효과는 높이고 부작용은 줄임,
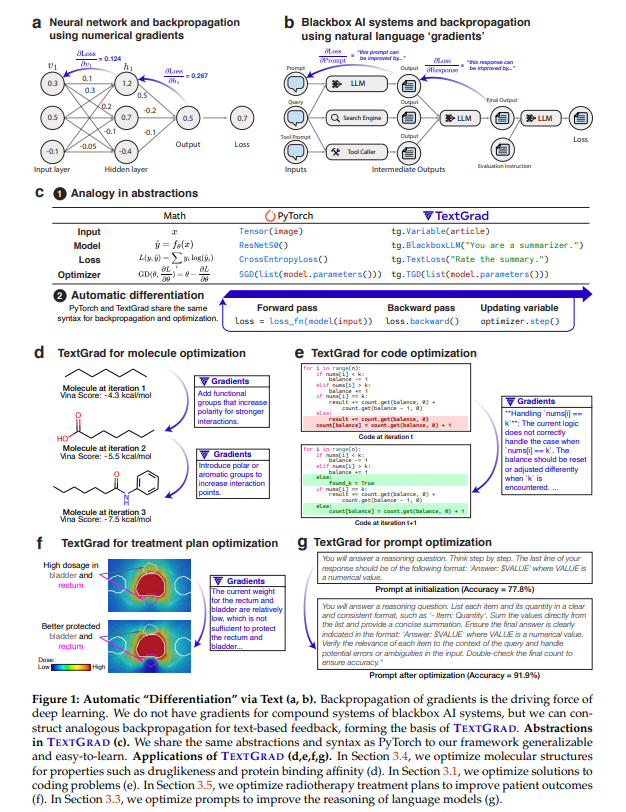
2. TEXTGRAD: Optimizing AI systems by backpropagating text feedback
먼저 두 개의 LLM 호출로 구성된 간단한 예제를 통해 TEXTGRAD가 어떤 모습인지 보여주고, 그 뒤에는 더 일반적인 시스템에 대한 설명을 이어갑니다:
계산 그래프는 다음과 같이 정의됩니다:
-
Prediction = LLM(_Prompt _+ Question)
-
Evaluation = LLM(Evaluation Instruction + Prediction)
여기서 우리가 최적화하려는 자유 변수는 “Prompt”이고, +는 문자열 연결을 의미하며, LLM(x)는 x를 프롬프트로 넣어 응답을 받는 LLM 호출을 의미합니다.
이를 다음과 같이 체인 표기법으로 나타낼 수 있습니다:
_Prompt _+ Question LLM→ Evaluation Instruction + Prediction LLM → Evaluation
즉, 첫 번째 LLM 호출로 Question에 대해 Prompt를 기반으로 Prediction을 생성하고, 두 번째 LLM 호출로 그 Prediction에 대해 평가합니다.


The general case
이 추상화는 복잡한 시스템으로 쉽게 확장할 수 있습니다. 계산 그래프의 각 변수 v에 대해 다음과 같이 정의합니다. PredecessorsOf는 해당 변수의 입력값들을, SuccessorsOf는 출력값들을 나타냅니다.:
v = f_v(PredecessorsOf(v)) for all v ∈ V
대체로 v의 값은 자연어 텍스트나 이미지 같은 비구조적 데이터일 수 있습니다. 이 논문에서는 대부분 자연어 텍스트로 구성되어 있습니다.
각 함수 f_v는 입력 변수 집합을 받아서 새로운 변수를 생성합니다. 예를 들어, LLM이나 수치 시뮬레이터가 이 역할을 수행할 수 있습니다.
그래디언트는 다음과 같이 계산됩니다:
∂L/∂v = sum[ ∇f_v(w, ∂L/∂w) for w ∈ SuccessorsOf(v) ]
즉, 변수 v가 사용된 모든 맥락(context)으로부터 피드백을 수집하고 이를 집계합니다.
최종적으로 변수 v를 업데이트할 때는 다음의 Optimizer를 사용합니다:
v_new = TGD.step(v, ∂L/∂v)
계산 그래프에 n개의 엣지가 있다고 할 때, 각 최적화 반복(iteration)마다 최대 n번의 LLM 호출이 추가로 이뤄지며, 각각의 엣지에 대해 한 번씩 그래디언트를 계산합니다. TEXTGRAD의 연산 구현은 부록 A를 참고하면 됩니다.
Appendix A.1: Variables
아래는 변수의 가장 핵심적인 속성들입니다:
-
값 (Value): 변수에 담긴 비구조적 데이터입니다. 본 논문에서는 대부분 텍스트 데이터입니다.
-
역할 설명 (Role description): 해당 변수가 계산 그래프 내에서 어떤 역할을 수행하는지를 설명하는 정보입니다. 이는 사용자가 그래프에 지식을 삽입하고 최적화 방향을 안내하는 데 활용됩니다. 예를 들어, “system prompt”나 “language model의 최종 출력”과 같은 설명이 될 수 있습니다.
-
그래디언트 (Gradients): 역전파 과정에서 LLM이 제공하는 자연어 기반 피드백입니다. 변수의 값을 어떻게 바꾸면 downstream loss를 줄일 수 있을지를 설명합니다.
-
선행 변수 (Predecessors): 해당 변수를 생성하는 데 사용된 변수들의 집합입니다. 예: LLM 호출에서 instruction과 question을 입력으로 넣고 response를 얻었다면, instruction과 question은 response의 선행 변수입니다.
-
requires_grad: PyTorch와 유사하게, 해당 변수에 대해 그래디언트를 계산할지 여부를 나타냅니다. 예를 들어, question 변수에 대해 그래디언트를 계산하고 싶지 않다면
Variable(value=question, requires_grad=False, ...)로 설정하면 됩니다.
Appendix A.2: Backpropagation
TEXTGRAD의 역전파는 각 노드가 사용된 모든 맥락으로부터 피드백을 수집하고, 이 피드백을 선행 노드로 전파하는 구조를 따릅니다. 즉, 어떤 변수에 대한 그래디언트는 그것이 어떤 결과를 만들었고 그 결과가 얼마나 좋았는지에 대한 LLM의 피드백으로 표현됩니다. 이 피드백은 후속 노드로부터 역방향으로 전파되어 최종적으로 최적화하고자 하는 변수에 도달합니다.

Appendix A.3: Functions
TEXTGRAD는 forward와 backward 양방향 연산이 정의된 여러 종류의 연산을 지원합니다. 이들은 PyTorch 스타일의 추상 클래스 textgrad.autograd.Function을 상속하며, forward와 backward 메서드를 정의합니다.
가장 핵심적인 함수는 LLMCall Function입니다:
-
Forward 모드: LLM에 API 호출을 하며, 호출에 사용된 모든 입력 변수들은 출력(response)의 선행 변수로 등록됩니다. 예를 들어 instruction + question → response의 경우, response의 선행 변수는 [instruction, question]입니다.
-
Backward 모드: 응답(response)에 대한 그래디언트를 instruction 및 question으로 전파합니다. 이때 system prompt에 다음과 같은 glossary 태그를 추가하여 LLM이 어떤 역할의 변수에 피드백을 줘야 하는지 명확히 합니다:

- prompt
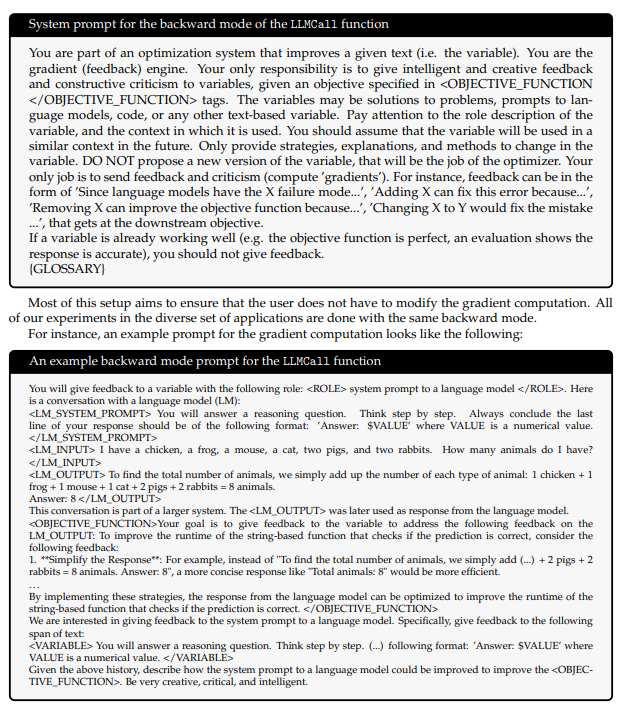

Appendix A.4: Textual Gradient Descent Implementation
역전파와 마찬가지로, TEXTGRAD의 최적화 단계도 일반성을 유지하도록 구현되어 있습니다. optimizer에 glossary를 포함하여, 각 변수의 역할, 목표, 현재 값 등을 포함한 정보를 시스템 프롬프트에 넣고, 피드백을 바탕으로 값을 업데이트합니다.
- The current system prompt to the optimizer call is the following:


Objective functions
수치 최적화나 자동 미분에서는, 목적 함수(objective function)는 일반적으로 mean squared error나 cross entropy처럼 미분 가능한 함수입니다. 하지만 TEXTGRAD에서는 목적 함수가 더 복잡하거나 미분 불가능한 함수일 수 있으며, 함수의 정의역(domain)과 공역(codomain)이 비구조적인 데이터일 수도 있습니다.
a simple loss function for a code snippet can be the following: Loss(code, target goal) =LLM(Here is a code snippet:{code}.
Instance vs Prompt Optimization
이 논문에서 다루는 최적화 문제는 크게 두 가지 범주로 나뉩니다:
-
인스턴스 최적화: 특정 문제의 해답—예: 코드 조각, 문제 풀이, 분자 구조 등을 직접 최적화 변수로 간주합니다. 예컨대 앞서 언급한 코드 예시에서는, 테스트 시점에서 특정 코드 인스턴스를 개선하는 것이 목표입니다. 프레임워크는 이에 대해 그래디언트를 생성하고, 해당 코드를 직접 최적화합니다.
-
프롬프트 최적화: 특정 작업에 대해 다수의 쿼리에 대해 성능을 높이는 프롬프트를 찾는 것이 목표입니다. 예를 들어, 수학적 추론 문제에 대해 LLM의 성능을 향상시키는 시스템 프롬프트를 찾는 것이 될 수 있습니다 (§3.3 참조). 여기서는 단일 쿼리에 대한 성능 향상보다는, 다양한 쿼리에 일반화될 수 있는 프롬프트를 만드는 것이 목적입니다.
두 가지 문제 유형 모두 TEXTGRAD 프레임워크를 별도로 손대지 않고 동일하게 해결할 수 있습니다.
Optimization Techniques
TEXTGRAD는 자동 미분의 개념을 기반으로 하고 있으며, 이 개념은 프레임워크에 포함된 여러 최적화 기법들을 이론적으로 뒷받침합니다. 아래는 구현된 예시들입니다:
-
Batch Optimization: 프롬프트 최적화를 위해 stochastic minibatch gradient descent를 구현했습니다. 각 반복마다 여러 인스턴스를 배치로 forward pass한 후 개별 loss 항목을 계산하고,
tg.sum함수를 통해 총 loss를 합산합니다 (torch.sum과 유사). backward pass에서는 개별 loss 항목을 통해 얻은 그래디언트를 각 변수에 대해 합칩니다. -
Constrained Optimization: 제약 조건이 있는 최적화(constrained optimization) 개념을 차용하여, 자연어 기반 제약 조건을 사용합니다. 예: “응답의 마지막 줄은 반드시 ‘Answer: $LETTER’ 형식이어야 하며, LETTER는 ABCD 중 하나여야 한다.” LLM은 instruction-tuning 덕분에 이러한 간단한 제약 조건을 잘 따르며, 단 제약 조건이 너무 많아질 경우 신뢰도가 낮아질 수 있습니다.
-
모멘텀 (Momentum): 변수 업데이트 시, TGD 옵티마이저는 해당 변수의 이전 iteration들 또한 참고할 수 있습니다.
TEXTGRAD에 구현된 최적화 기법들의 더 자세한 내용은 부록 B에서 확인할 수 있습니다:
Appendix B


3. Results
해당 섹션에서는 TEXTGRAD을 다양한 응용 분야에서 사용해봅니다. §3.1에서는 어려운 코딩 문제에 대한 코드 스니펫을 최적화하고, §3.2에서는 과학 문제 해결을 위한 솔루션을 개선하며, §3.3에서는 프롬프트를 최적화하여 LLM의 추론 능력을 향상시킵니다. §3.4에서는 분자 구조를 최적화하여 약물 특성을 향상시키고, §3.5에서는 전립선암 환자를 위한 방사선 치료 계획을 최적화합니다.
3.1 Code optimization
코드 최적화는 인스턴스 최적화의 대표적인 사례. 여기서 목표는 코드의 정확성과 실행 복잡도를 개선하는 것입니다. 일반적인 계산 그래프는 다음과 같습니다:
```plain text Code-Refinement Objective = LLM(Problem + **Code **+ Test-time Instruction + Local Test Results)
Test-time Instruction = critique or investigate the current iteration
예시: "정수 배열 nums와 정수 k가 주어졌을 때, 중앙값이 k인 비어있지 않은 subarrays 수를 반환하시오."
GPT-4o가 생성한 첫 번째 해답은 테스트를 통과하지 못했고, TEXTGRAD는 edge case를 식별하고 개선 방안을 제안. 최종 최적화된 구현은 모든 테스트를 통과함.
- **Task:** LeetCode Hard 데이터셋을 사용. 이 데이터셋은 매우 어려운 문제로 구성되어 있으며 GPT-4조차도 7% 성공률을 보이는 것으로 알려져 있음. 테스트 데이터가 public하지 않기 때문에, 만들고 하나하나 LeetCode platform에 제출되었음. (unseen task)
- **Baseline:**
- Reflexion, GPT-4o , one-shot
- zero-shot GPT-4o
- **결과:**
- 기존 결과에서는 GPT-4 zero-shot이 7%, Reflexion이 15%였던 반면,
- 이번에는 GPT-4o zero-shot이 26%, Reflexion이 31%, TEXTGRAD가 36%의 성공률을 달성
<figure
>
<picture>
<!-- Auto scaling with imagemagick -->
<!--
See https://www.debugbear.com/blog/responsive-images#w-descriptors-and-the-sizes-attribute and
https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images for info on defining 'sizes' for responsive images
-->
<img
src="/assets/img/posts/2025-06-03-textgrad-automatic-differentiation-via-text/image_011.png"
class="img-fluid rounded z-depth-1"
width="100%"
height="auto"
loading="eager"
onerror="this.onerror=null; $('.responsive-img-srcset').remove();"
>
</picture>
</figure>
## 3.2 Solution optimization by test-time training to improve problem solving
solution optimization의 목표는 quantum mechanics이나 organic chemistry과 같은 복잡한 문제에 대한 답을 만들어내는 것입니다. 계산 그래프는 다음과 같습니다:
```plain text
Solution Refinement Objective = LLM(Question + ***Solution ***+ Test-time Instruction)
매 iteration 마다, LLM은 question, current solution, test-time instruction asking to critique or investigate the current iteration을 입력으로 받습니다. 최적화 과정동안 solution은 이 test-time self-evaluation을 통해 개선됩니다. 이는 일반적으로 test-time training이라고 불리어 왔던 개념과 동일합니다.


-
Task: GPQA (Google-Proof QA)는 물리, 생물, 화학 등에서 전문가가 만든 어려운 문제들을 포함 전문가와 비전문가의 성능 차이가 큼(81% and 22% accuracy respectively). 또한 MMLU의 하위셋인 Machine Learning, College Physics도 포함 (expert human accuracy on average is around 90%).
-
Method: GPT-4o에 대해 3번의 TEXTGRAD 기반 test-time 업데이트를 수행하고, 각 업데이트에 대해 다수결 투표로 최종 답을 정함.
-
결과: GPQA에서 GPT-4o는 53.6%였지만 TEXTGRAD로 55%까지 향상(sota). MMLU의 Machine Learning에서는 85.7% → 88.4%, College Physics는 91.2% → 95.1%로 상승했습니다.
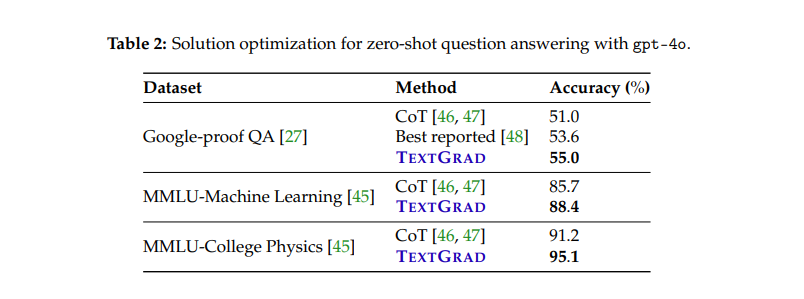
3.3 Prompt optimization for reasoning
LLM은 프롬프트에 민감하며, 적절한 프롬프트는 성능 향상에 큰 도움이 됩니다.
Answer = LLM(***Prompt***, Question)
Evaluation Metric = Evaluator(Answer, Ground Truth)
이 실험에서는 GPT-3.5-turbo의 프롬프트를 개선하여 GPT-4 수준에 가까운 성능을 도달하는 것이 목표.
TEXTGRAD tries to optimize each individual solution였던 instance optimization과 달리, 여기서의 목표는 전체 질문들에 대해서 잘 동작하나는 하나의 프롬프트를 만드는 것이 목적입니다.
-
Task: BigBench Hard (Object Counting, Word Sorting), GSM8k
-
Method: a minibatch stochastic gradient descent setting . GPT-3.5가 forward pass를 담당하고, GPT-4o가 feedback을 제공 batch size는 3이며 총 12번 iteration을 돌며 학습. 36 training examples in total, sampled randomly with replacement
-
Baseline:
-
Zero-shot CoT
-
DSPy (Bootstrapped FewShot RandomSearch)
-
optimizer with 10 candidate programs and 8 few-shot example
-
This optimizer identifies demonstrations to include in the prompt as few-shot examples. This is done through generating traces of LLM inputs and outputs that individually pass the metric (in this case, accuracy) and includes CoT reasoning. It then applies random search over subsets of up to size eight shots with these demonstrations.
-
-
결과: TEXTGRAD는 모든 task에서 zero-shot CoT 대비 성능이 크게 향상되었고, DSPy와 비슷하거나 더 좋은 결과. Object Counting에서는 7%p 우위. 또한 TEXTGRAD와 DSPy를 조합하면 더 높은 성능(예: GSM8k에서 81.1%)을 달성.
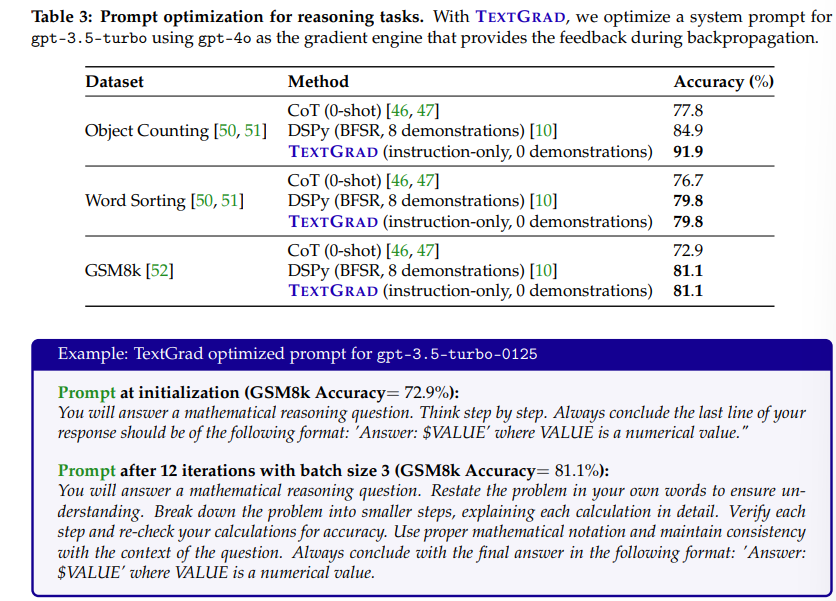
3.4 Molecule optimization
TEXTGRAD는 multi-objective optimization tasks에도 적용됩니다. 예를 들어, drug discovery에서 synthesizability, efficacy, safety를 동시에 보장해야 합니다. 이번 실험에서는 binding affinity and druglikeness를 동시에 높이는 작업을 수행합니다.
-
Task:
-
binding affinity,
- 약물 분자의 결합 친화도는 해당 분자가 표적 단백질에 얼마나 강하게 결합하는지를 나타내며, Vina score를 사용해 측정합니다. Vina 점수는 낮을수록 (더 음수일수록) 결합 친화도가 높다는 것을 의미
-
druglikeness
- Druglikeness는 분자의 체내 흡수, 대사 안정성, 용해도 등과 관련된 특성으로, QED 점수를 통해 측정합니다. QED는 0~1 범위의 값으로, 1에 가까울수록 이상적인 약물 특성을 가진 것으로 간주
-
즉, 이 실험에서는 Vina 점수(결합력)와 QED 점수(약물 적합도)를 기반으로 loss를 구성
- 보통, 둘은 trade off 관계여서 최적화가 어려움 - docking scores: prefer larger molecules with many functional groupsdruglikeness: encourages lighter, simpler molecules
-
-
Method:
- SMILES 문자열로 표현된 분자를 TEXTGRAD의 인스턴스 최적화 대상으로 설정.
```plain text Evaluation = LLM((Affinity(SMILES_i, target), Druglikeness(SMILES_i))) SMILES_{i+1} = TGD.step(SMILES_i, ∂Evaluation/∂SMILES_i)
- 각 분자에 대해 Vina 점수와 QED 점수를 조합한 multi-objective loss를 정의하고, 그에 대한 텍스트 기반 그래디언트를 생성해 분자를 업데이트.
- 초기 분자는 작은 기능성 화합물 조각에서 시작하며, DOCKSTRING 벤치마크에 포함된 58개 표적 단백질에 대해 각각 10회 최적화를 수행. .
- **결과:** 모든 58개 표적에 대해 결합력과 druglikeness가 향상된 분자를 생성
- 실제 임상 승인 약물을 포함하는 29개 표적의 경우, TEXTGRAD가 생성한 분자들은 유사한 in silico 점수를 보였고 (appendix 자세히), 기존 약물과는 구조적으로 다른 새로운 형태를 가짐.
- 또한 생성된 분자들은 기존 약물들과 비교해도 독성이나 약리학적 특성에서 유사한 안전성을 보임
<figure
>
<picture>
<!-- Auto scaling with imagemagick -->
<!--
See https://www.debugbear.com/blog/responsive-images#w-descriptors-and-the-sizes-attribute and
https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images for info on defining 'sizes' for responsive images
-->
<img
src="/assets/img/posts/2025-06-03-textgrad-automatic-differentiation-via-text/image_016.png"
class="img-fluid rounded z-depth-1"
width="100%"
height="auto"
loading="eager"
onerror="this.onerror=null; $('.responsive-img-srcset').remove();"
>
</picture>
</figure>
- The textual gradients for the first three iterations are shown in (a)
- TextGrad successfully designs molecules with similar vina scores and greater QED scores than clinically approved molecules (b)
- the performance of all ten iterations compared to clinically approved molecules targetting PPARA in (c).
- The molecule at the final iteration has low structural similarity with its most similar clinically approved counterpart, and better QED and Vina scores (d)
- with a highly plausible pose geometry shown in (e).
## 3.5 Radiotherapy treatment plan optimization
방사선 치료(Radiotherapy)는 고강도 에너지를 이용해 종양 세포를 제거하는 의료 행위입니다 (such as X-rays, to kill cancer cells). 이를 위한 계획은 방사선량을 필요한 부위에 집중시키는 동시에 주변 정상 조직에는 최대한 적은 양이 도달하도록 구성됩니다.
- **문제 정의:** 전형적인 방사선 치료 계획 최적화는 다음과 같은 2중 루프 구조로 되어 있습니다.
- **내부 루프 (inverse planning):**
- 수치 최적화기→ 여러 상충하는 목표를 균형 있게 반영한 가중합 비용 함수를 최소화하는 것을 목표로 합니다.
- 이때의 목표는 종양과 주변의 여유 마진을 포함한 PTV(planning target volume)에 처방된 선량을 충분히 전달하고, 위험 장기(OARs)에 과도한 선량이 도달하지 않도록 보호하는 것입니다.
- **외부 루프:** 임상 목표를 달성하도록 하이퍼파라미터(조직별 가중치)를 반복적으로 수정
- 위의 내부 루르 임상적으로 수용 가능해질 때까지 반복.
- 실제 임상에서는 사람 계획자가 시행착오 방식으로 하이퍼파라미터를 조정해가며 원하는 계획이 나올 때까지 반복합니다.
- 이 하이퍼파라미터는 PTV, 장기, 기타 조직에 대한 가중치 등으로 구성되며, 경험, 시간 등에 따라 주관적인 판단이 많이 개입되고 계산 비용이 큰 최적화를 반복적으로 수행하게 됩니다.
- 따라서 이 과정은 비효율적이고 시간이 오래 걸리며 비용도 큽니다.
- **Method:**
우리는 TEXTGRAD를 외부 루프 최적화에 적용하여, 내부 수치 최적화기(예: matRad)를 위한 하이퍼파라미터 최적화를 수행합니다. 하이퍼파라미터는 다음과 같이 문자열로 표현됩니다:
```plain text
θ = "weight for PTV: [PTV WEIGHT], weight for bladder: [BLADDER WEIGHT], weight for rectum: [RECTUM WEIGHT], weight for femoral heads: [FH WEIGHT], weight for body: [BODY WEIGHT]"
하이퍼파라미터가 주어지면, 우리는 다음의 수식과 같이 matRad를 사용해 해당 치료 계획을 생성하고,
```plain text P(θ) = matRad(θ)
임상 목표 g와 현재 계획 P(θ) 간의 차이를 이용해 LLM으로부터 loss를 평가받습니다:
```plain text
L = LLM(P(θ), g)
그 후, TEXTGRAD는 다음의 업데이트 규칙에 따라 하이퍼파라미터를 갱신합니다:
```plain text θ_new = TGD.step(θ, ∂L/∂θ)
LLM이 하이퍼파라미터 θ와 matRad로부터 얻은 치료 계획 P 간의 관계를 더 잘 이해하도록 하기 위해, 이전에 생성된 치료 계획과 해당 하이퍼파라미터 쌍 {(Pᵢ, θᵢ)}를 컨텍스트로 함께 제공합니다. 따라서 전체적으로는 다음과 같은 형태로 업데이트됩니다:
```plain text
θ_new = TGD.step(θ, ∂L/∂θ, {(Pᵢ, θᵢ)}_i=1^N)
평가 지표: 치료 계획의 성능은 단일 지표로 평가할 수 없으므로 여러 표준 선량 지표를 함께 사용. 예를 들어, 특정 조직 또는 표적 부위에 전달된 평균 선량(mean dose), 그리고 해당 부위의 q% 이상이 받는 최소 선량 Dq 등을 사용합니다.
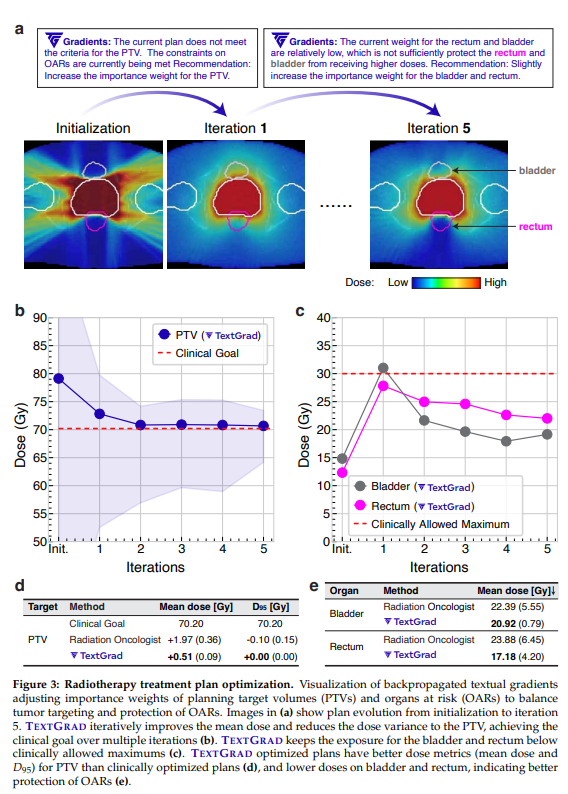
-
결과:
-
Figure 3에서 PTV 외부로 선량이 넘치는 경우, TEXTGRAD는 PTV 가중치를 높이라고 제안합니다. 이에 따라 PTV 영역에 선량이 더 균일하게 집중됩니다. 그러나 이 조정은 상대적으로 방광이나 직장 보호가 약해질 수 있으므로, 다음 단계에서 이들에 대한 가중치를 소폭 증가시키도록 피드백을 줍니다.
-
TEXTGRAD로 최적화된 방사선 치료 계획을 실제 전립선암 환자 5명의 임상 계획과 비교했습니다.
-
In Figure 3 (c), we assess TextGrad’s capabilities in_ achieving clinical goals_ for the PTV region. TextGrad outperforms the clinical plans across all metrics, achieving a higher mean dose, and a D95 that exactly matches the prescribed dose.
-
In Figure 3 (d), we focus on the sparing of healthy organs. TextGradoptimized plans achieve lower mean doses for these healthy organs, suggesting better organ sparing than the human-optimized plans. We report the averages across five plans and with standard deviation included in the bracket.
-
-
5. Discussion
TEXTGRAD는 세 가지 핵심 원칙 위에 구축되었음:
-
특정 응용 도메인에 맞춰 설계되지 않고 일반적이며 성능이 우수한 프레임워크일 것,
-
PyTorch 스타일의 추상화를 차용하여 사용하기 쉬울 것,
-
오픈소스로 제공되어 누구나 활용할 수 있을 것.
본 논문에서 텍스트 피드백의 역전파 가능성을 보여주긴 했지만, TEXTGRAD를 확장할 수 있는 다양한 응용 분야가 여전히 존재. 예를 들어, 도구 사용(tool use)이나 검색 기반 생성(RAG: Retrieval-Augmented Generation) 시스템 등 실제 LLM 활용에서 자주 사용되는 구성 요소들을 계산 그래프의 연산 노드로 포함시키는 것이 필요.
둘째, 자동 미분이라는 은유를 바탕으로 다양한 기법들 적용 가능. 예를 들어, 최적화의 안정성을 높이기 위해 분산 감소 기법(variance reduction), 적응형 그래디언트(adaptive gradients), LLM을 통한 self-verification 등의 방향성과 TEXTGRAD를 연결 지을 수 있음. 더 나아가, TEXTGRAD 자체를 TEXTGRAD로 최적화하는 meta-learning 기반 방법도 가능할 것