The Accuracy Paradox in RLHF: When Better Reward Models Don’t Yield Better Language Models / What Makes a Reward Model a Good Teacher? An Optimization Perspective
논문 정보
- Date: 2025-08-12
- Reviewer: 준원 장
- Property: Reinforcement Learning, Reward Model
The Accuracy Paradox in RLHF: When Better Reward Models Don’t Yield Better Language Models
1. Introduction
-
우리는 왜 RL을 통해 alignment를 할까?
-
SFT suffers from exposure bias
-
SFT lacks the ability to optimize for sequence-level rewards
-
RQ & Our Common Myth
-
더 Accurate을 줄 수 있는 RM이 더 effectiveness한 RM을 만들 수 있다.
-
논문은 여러 실험을 통해 이를 반박하고자 함.
⇒ moderate한 accuracy를 가진 RM이 the most accuracy를 가진 RM보다 LM performance를 더 향상시킨다.
⇒ RM accuracy랑 LM final performance는 correlation이 없다.
2. Motivation and Problem Setting & Recap RLHF Formula
Motivation
- LM performance를 maximize할 수 있는 reward model의 optimal accuracy range가 존재한다고 가정
RLHF Formula
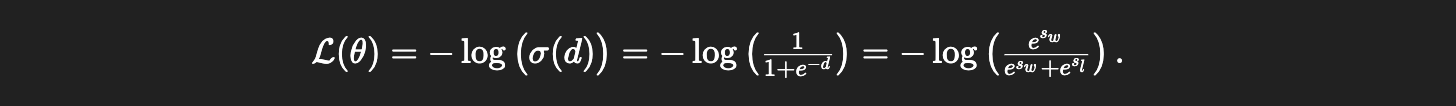
triplet: (x, y_w, y_l)
-
accepted response score:
s_w = r_θ(x, y_w) -
rejected response score:
s_l = r_θ(x, y_l)

Problem Setting
-
RM strength가 LM performance에 미치는 영향을 탐색
- metric
-
factuality
-
relevance
-
completeness
-
P{LM} = f (S{RM}, τ )
-
P_{LM}: LM acc on task
-
S_{LM}: RM acc on RM binary task
-
τ: RL training time
-
3. Experiment and Results
Experimental Setting
-
Models
-
LM: T5 (small, base, large)
-
RM: Longformer-base-4096
-

-
Datasets
- QA-FEEDBACK (3,853/500/948)
(Q, Gold, non-fact, …)가 존재
-
Training
-
PPO
-
RM list
-
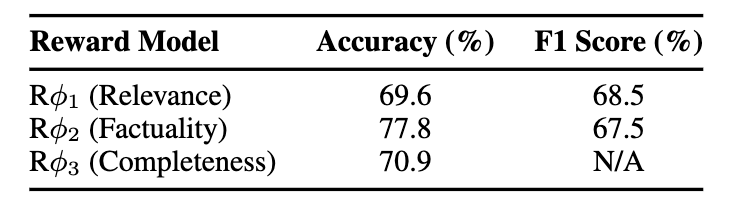
-
Critic LM: T5-base
-
Reward hacking 방지를 위해 KLD(↔ ref LM)가 너무 커지면 training interrupt (약간의 휴리스틱)
Results
Are High-Accuracy and Deeply Trained Reward Models Always the Best?
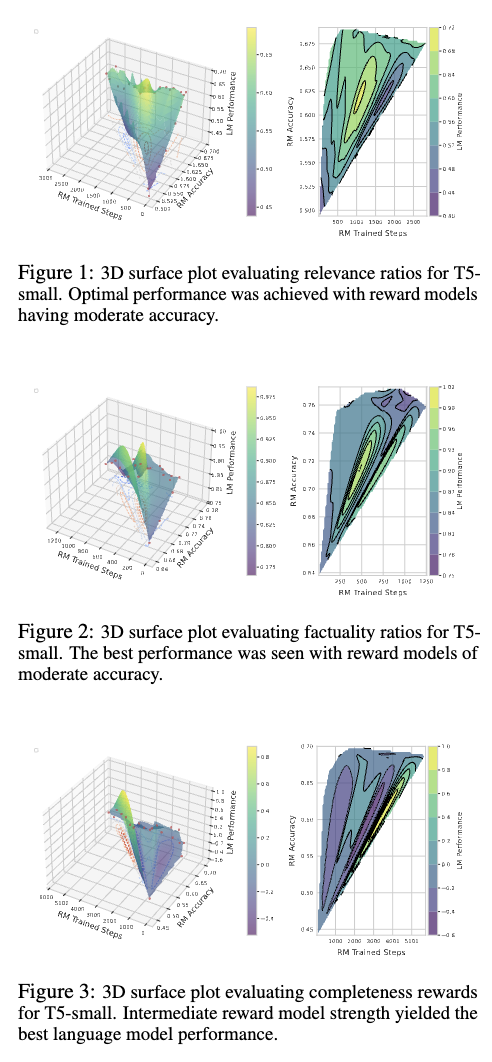
-
moderate accuracy와 appropriate number of trained steps로 학습된 RM이 높은 LM performance로 이어진다.
-
relevance: mitigating the risk of overfitting
-
factuality: prevent overfitting and ensure reliable outcomes
-
consistent across the T5-base and T5-large models
How Do Best and Most Accurate Reward Models Differ?
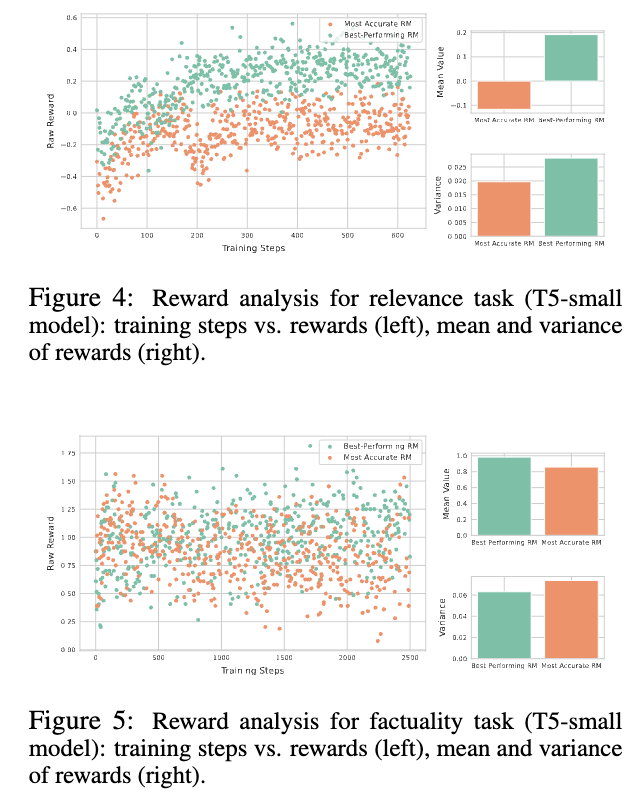
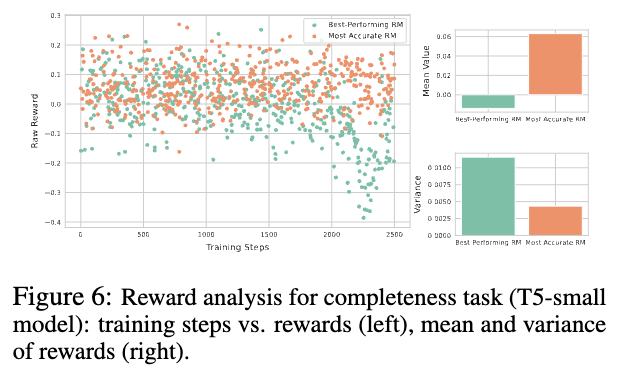
- Relevance
→ high-score, high-variance
- Factuality
→ high-score, less-variance
- Completeness
→ low-score, high-variance
⇒ 공통적으로 모든 task에 대해서 best-performance RM은 variance가 높음.
직관적으로 생각해보면, 이 말은 곧 RM이 broader range of responses에 대한 평가를 가능하게 함 := exploration ⇒ improving the quality of the generated text
(개인적으로, variance가 클수 밖에 없는 verifiable reward가 이래서 LM performance가 좋았나..라는 생각이 들음)
How Do Best and Most Accurate Rewards Impact Models? (i.e., Role of KLD)
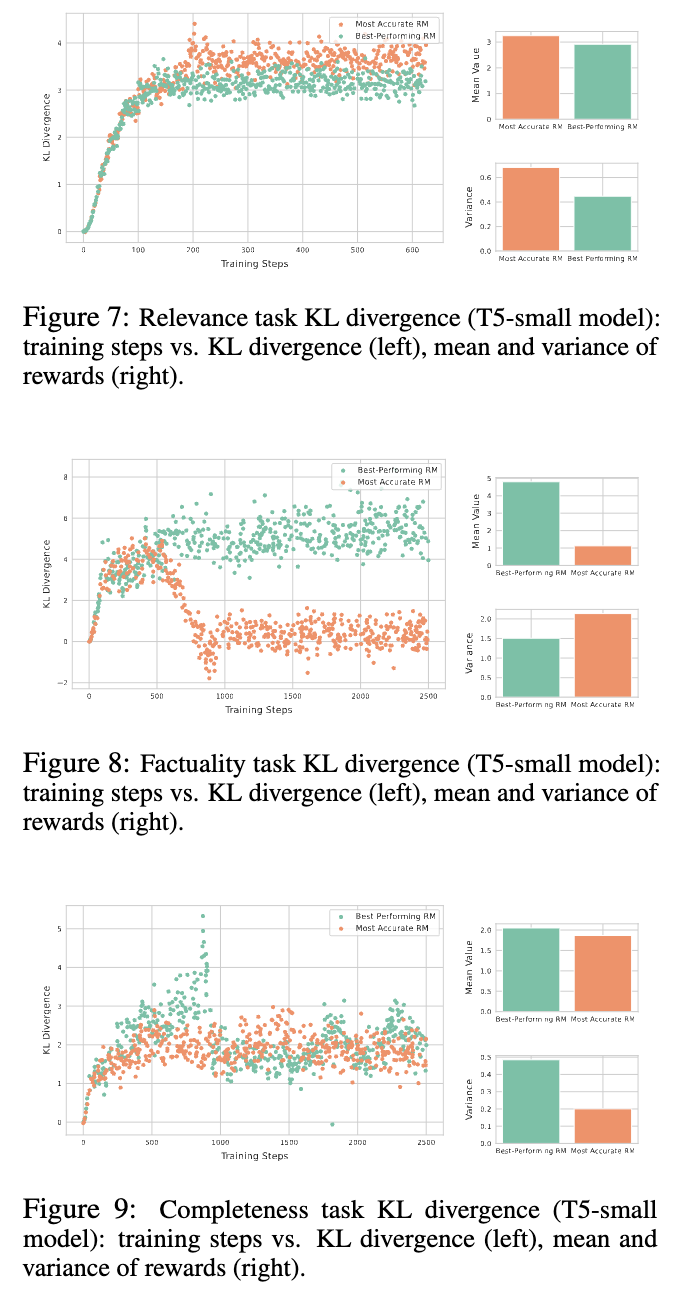
- Relevance
→ low-score, low-variance
relevance측면에서 stable alignment
- Factuality
→ high-score, low-variance
factuality 측면에서 consistent yet varied alignment (ref가 틀린 사실을 말하고 있다면)
- Completeness
→ high-score,high-variance
flexible approach suitable for evaluating complex texts (이건 해석이 좀..)
4. Conclusion
- RM을 평가할때 accuracy 자체로만 평가하는 것의 한계를 실험적으로 명확히 보여준 논문
What Makes a Reward Model a Good Teacher? An Optimization Perspective
1. Introduction
-
이전 논문에서 RL 관점에서 RM의 성능을 평가할 때 accuracy만으로 판단하는 것의 한계를 지적하며, variance이 높은 RM이 오히려 더 나은 policy model performance으로 이어질 수 있음을 보여주었다.
-
이 논문은 이 논의를 확장해 다음의 질문에 대한 대답을 하고자 함.
“what makes a reward model a good teacher for RLHF?”
(수학적으로 많은 증명들이 있지만, 차치하고 논문에서 이야기하고 싶은 바는 아래와 같다.)
-
\pi_{\theta} (policy)에서 충분히 높은 확률로 rollout한 output에 대해서 얼만큼 잘 구분하는가 = reward variance
-
r_G (ground truth reward: 우리가 올려야하는 reward)
-
r_{rm} (proxy reward: policy model에 의해 학습되는 reward)
⇒ low reward variance는 policy gradient로 학습시 r_{rm}뿐만 아니라 r_G도 굉장히 느리게 update하게 만든다.
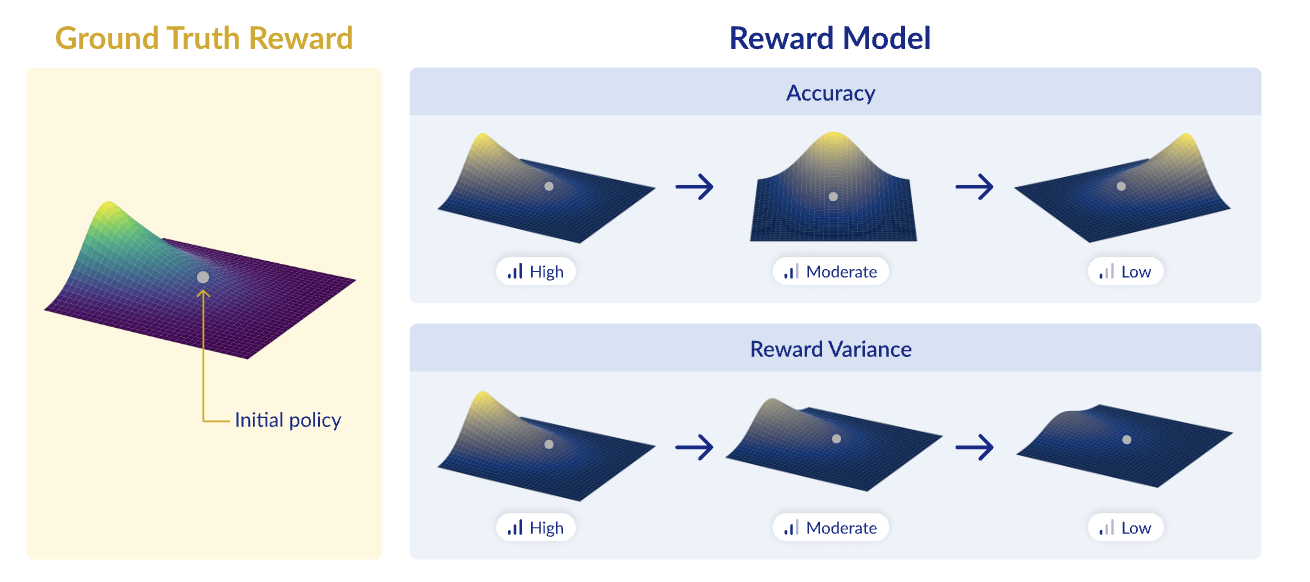
2. Preliminaries
Reward model training or selection
-
우리의 목표: E{y∼πθ (· x)}[r_G(x, y)]
maximize the exp. ground truth reward
- Proxy 목표: r_{RM} : X × Y → [−1, 1]
Reward maximization via policy gradient
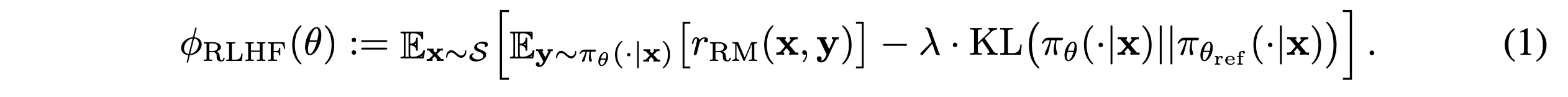
Accuracy in RM
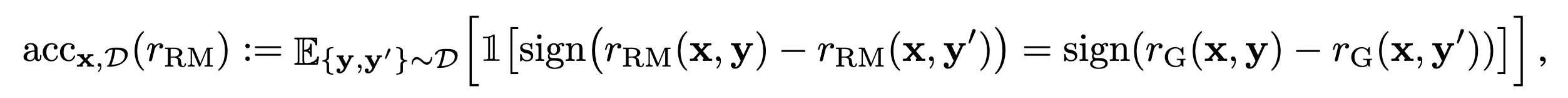
-
RM에서의 accuracy란 rG랑 r{rm} 이 같은 ranking으로 예측하고 있냐?이다.
-
즉,
-
r_{G}: 0.9 (x1) > 0.5 (x2) > 0.2 (x3)
-
r_{rm}: 0.54 (x1) > 0.51 (x2) > 0.49 (x3)
이면 r_{rm}의 acc는 1.0이다.
- 일반적으로 RM의 acc는 off-policy bencmark (e.g., HH test set)에서 이루어짐. 그러나 RM이 적용되는 시점은 on-policy 시점 ⇒ 논문은 이를 모두 고려해서 분석을 진행.
Reward Variance in RM
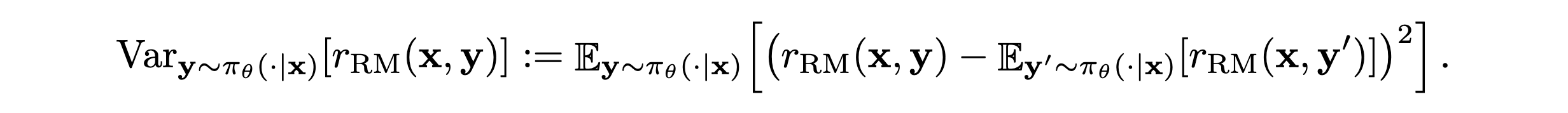
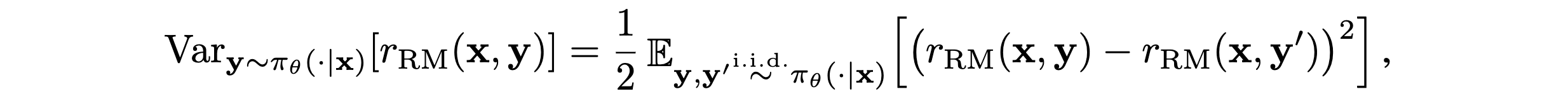
- \pi_{\theta} (policy)하에서 발생하는 rollout을 RM이 얼만큼 잘 구분하는가?
3. Theory: Optimization Perspective on What Makes a Good Reward Model
Technical Setting
- 논문에서 증명을 위해 정의한 policy의 generation 식
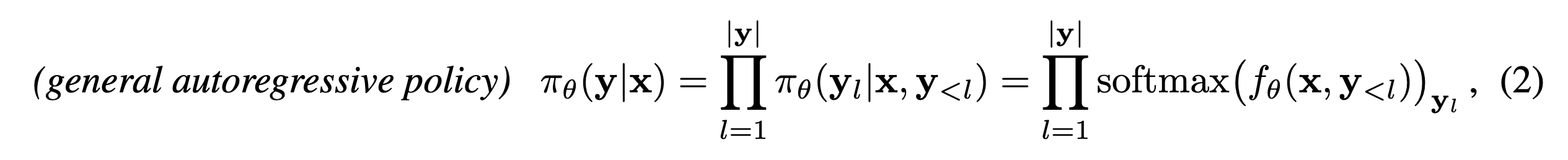

Low Reward Variance Implies Slow Reward Maximization

- 초기 reward 대비 \gamma만큼 기대보상을 올리는데 걸리는 시간 t는 reward variance의 -1/3 제곱에 비례한다.
(논문에 증명있습니다!)
- reward variance 🔽 → RLHF loss 고차미분 🔽 = hessian 🔽 → gradient norm이 커지는거 방지 → 학습 방해
More Accurate Reward Models Are Not Necessarily Better Teachers
-
어떤 초기 policy \pi_{\theta(0)}에 대해서도,
-
acc =1인 완벽한 보상 모델 r_{\mathrm{RM}} 존재
-
acc ≤2/∣Y∣ 인 매우 부정확한 보상 모델 r’_{\mathrm{RM}} 존재
-
-
그런데 r{\mathrm{RM}}을 쓰면 t\gamma가 무한히 커질 수 있음 (학습이 극도로 느림)
-
반면 r’{\mathrm{RM}}을 쓰면 t\gamma = O(\pi_{\theta(0)}(y^\gamma x)^{-1})로 훨씬 짧을 수 있음
(전재 조건은 그래도 r’{\mathrm{RM}}(x,y^\gamma) > r’{\mathrm{RM}}(x,y))
4. Experiments
-
Ground truth reward.
-
ArmoRM라는 모델이 주는 reward가 gt reward라고 가정
-
Data.
-
UltraFeedback (80: RM tr / 20: policy gradient)
-
Ref.
-
Pythia2.8B → AlpacaFarm SFT
-
Reward model
-
On-Policy Data: 100%, 75%, 50%, 25%, 0% on-policy data sampling해서 ArmoRM로 labeling.
-
Off-Policy Data: UltraFeedback
-
Policy Gradient
-
RLOO
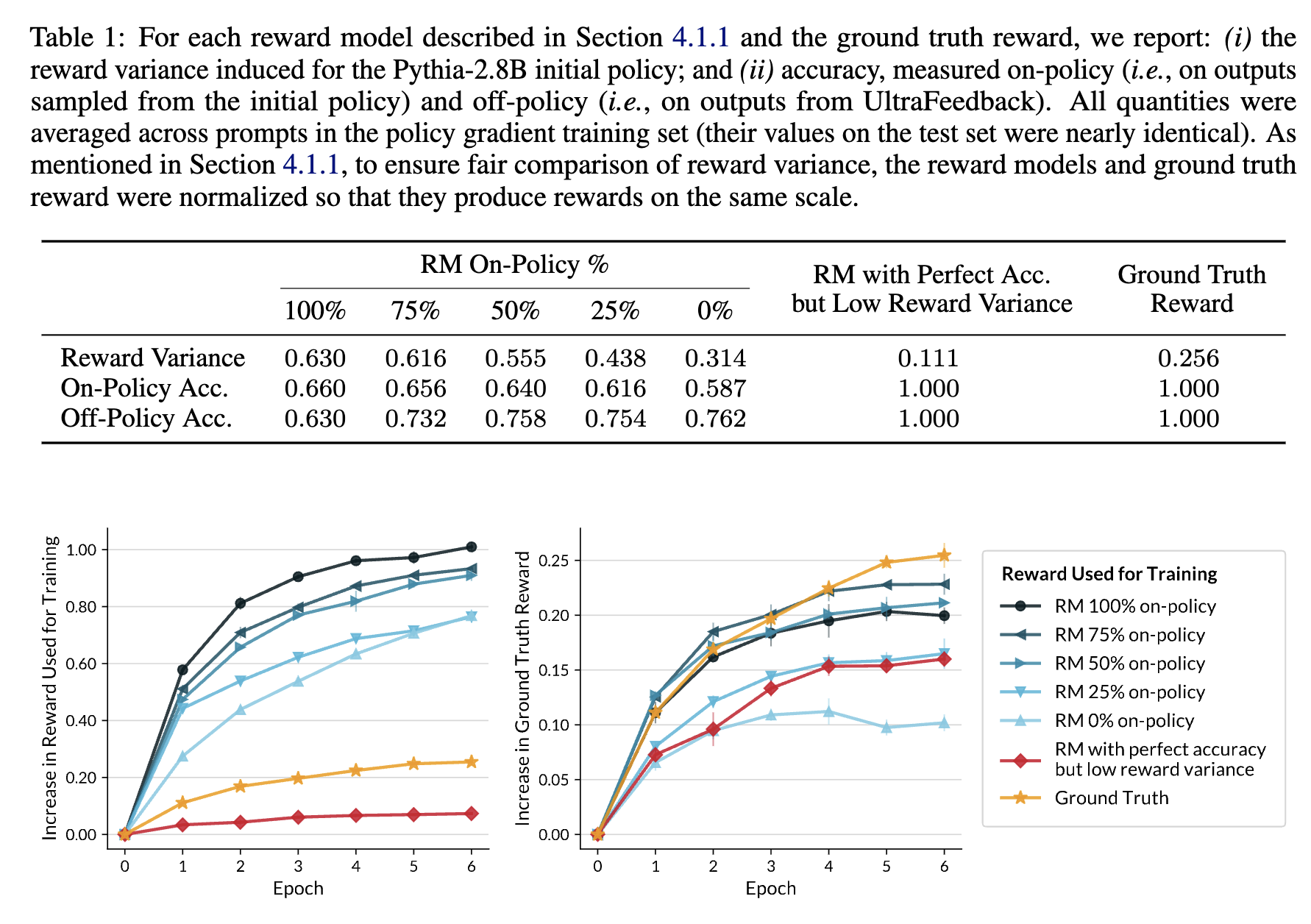
- Reward variance가 높을수록 proxy reward는 빠르게 증가함.
하지만, reward variance가 높은 RM이라고 하더라도 해당 RM의 본질적인 불안정성 (GT의 acc를 정확하게 반영하지는 못함 = Reward Hacking)이 있기에 Ground Truth reward만큼을 True Reward를 못올림
⇒ Epoch3가 Reward Hacking 지점
-
Accuracy가 높고 Reward variance가 낮은 RM은 학습도 느리며 실제 Ground Truth reward도 그렇게 많이 올리지는 못함
-
우리가 ‘Ground Truth reward’를 100%로 반영하는 RM을 반영할 수 없으니 실제로는 reward variance가 높은 RM으로 on-policy training하고 끊어주는건 좋은 RL optimization이다.
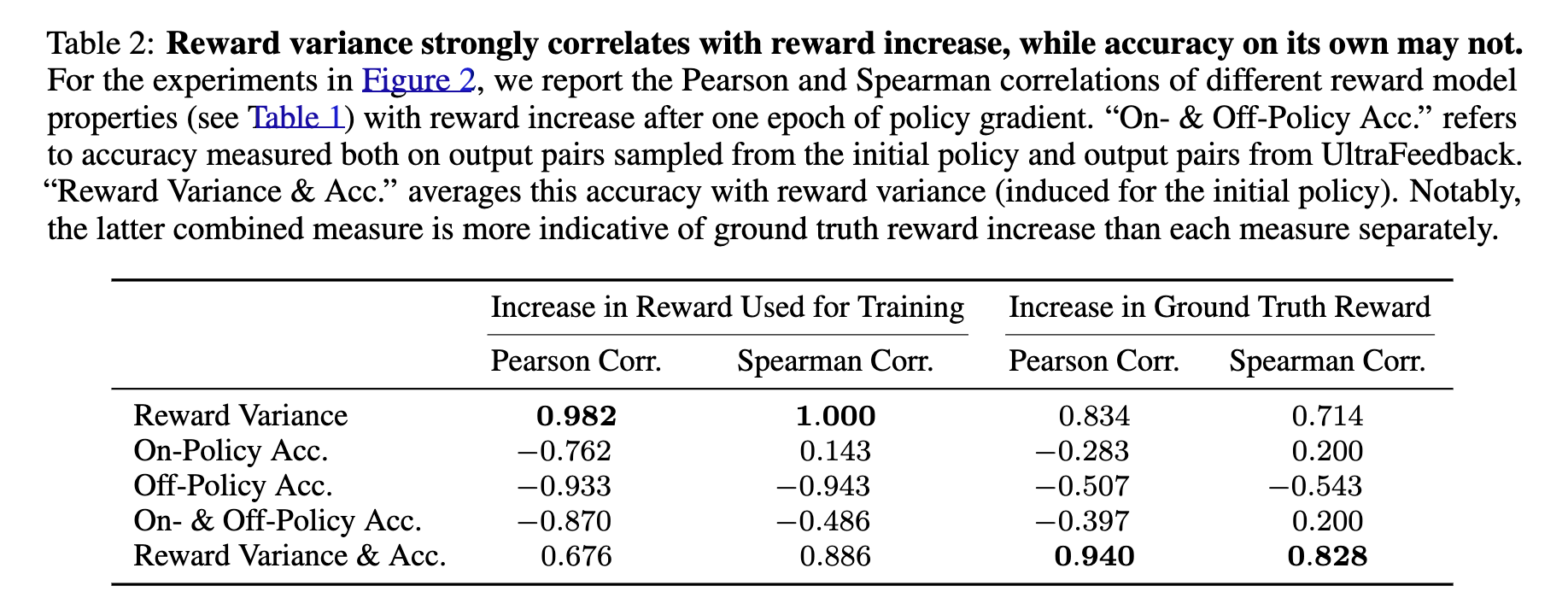
-
Corr을 보면, reward variance는 학습하고자 하는 proxy말고 ground truth를 target하기에도 좋은 feature
-
우리가 자주 봐왔던 off-policy acc (e.g., HH-test set)은 RL시 RM이 도움되는가?에 대한 대답이 되지 못함
-
마지막 지표는 ‘initial policy에 대한 accuracy와 off-policy dataset에 대한 accuracy를 reward variance로 평균낸거’라는데 해석은 잘 못했습니다…
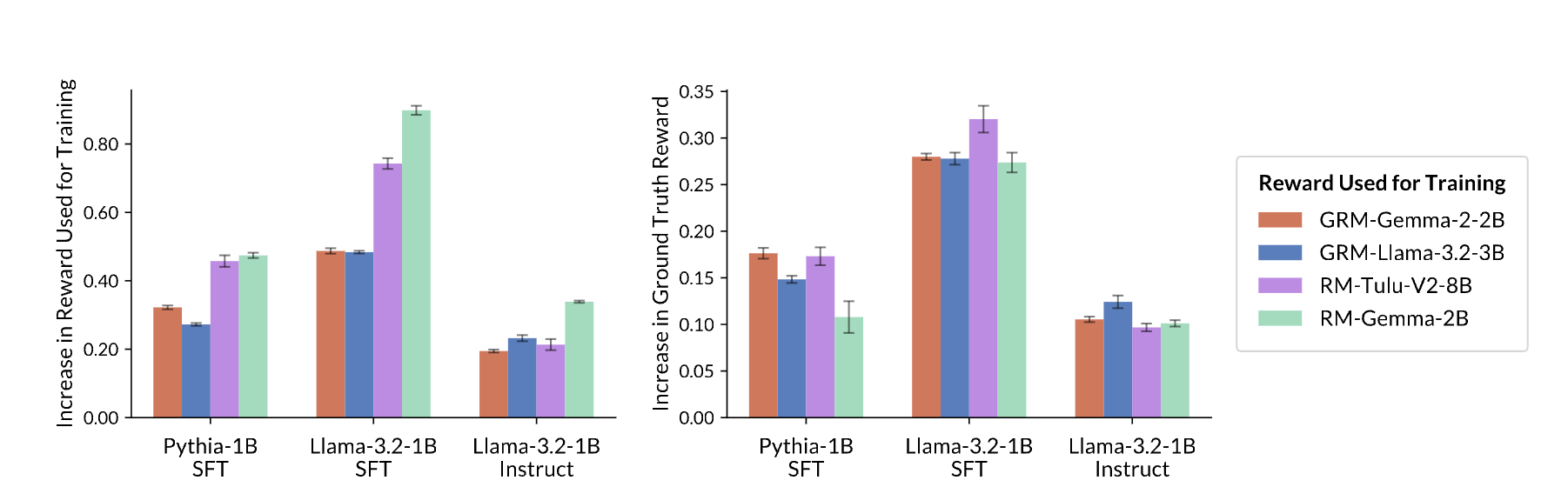
- initial policy의 output에 대한 reward variance를 충분히 크게 하는 RM을 사용해야 한다.
5. Conclusion
-
on-policy training 상황에서 off-policy accuracy만으로 RM의 effectiveness를 평가하면 optimization에 악영향을 끼침을 보임
-
reward variance는 RM의 optimization를 미리 가늠해볼 수 있는 좋은 지표
→ ground truth reward를 보장해주지는 않음.