Towards a Generalizable Bimanual Foundation Policy via Flow-based Video Prediction
논문 정보
- Date: 2025-06-10
- Reviewer: 전민진
- Property: Robotics
Abstract
-
Generalizable bimaual policy를 만드는 것은 여러 challenge가 존재
-
large action space : 같은 task여도 한 팔로 할 때 보다 양팔로 할 때 더 다양하게 수행할 수 있음
-
the need for coordinated arm movements : 양팔의 task를 조정, 충돌을 피하도록 action이 구성되어야 함
-
-
최근에 pretrained VLA를 기반으로 general bimanual policy를 만드는 연구들이 제안되어 왔으나 효과적이진 않음
- bimanual data가 희소하고, 한 팔과는 근본적인 차이가 존재
-
text-to-video model과 light diffusion policy로 구성된 프레임워크를 구축, 각각의 모델을 FT해서 사용하는 방법론을 제안
-
mitigate ambiguity of language in single-stage text-to-video prediction : text-to-video prediction시 중간에 flow video를 생성, 해당 영상을 기반으로 로봇 영상을 생성하도록 하여 언어의 모호성을 줄임
-
reduce the robot-data requirement : text-to-video prediction의 경우 어느정도 pretrain되어있기 때문에 적은 bimanual dataset으로도 충분히 fitting가능
-
Introduction
-
bimanual manipulation은 embodied agent가 양손이 모두 필요한 복잡한 task를 수행하기 위해서 중요한 분야
-
single-arm manupulation과 달리, bimanual task의 경우 human-like coordination이 필요
-
양팔 움직임에 대한 action space가 상당히 커짐
-
양팔이 충돌 되지 않고, 전체 task에 맞게 각 팔의 역할이 적절히 분배되어야 함
-
-
이전 bimanual policy는 다음과 같은 방법으로 학습
-
simulation을 사용해서 학습
-
small scale real-world data를 활용해 FT
-
human-objective primitives
-
RL with policy tranfer to learn a bimanual policy
-
-
하지만 이전 방법론은 다음과 같은 한계가 존재
-
high-quality bimanual data가 희소해, generalization capabilities가 제한적
-
sim-to-real gap 존재 + (민진 경험) simulator속도가 개느림
-
-
VLA을 기반으로 한 방법론은 일반화가 가능하지만..
-
cross-embodied data를 섞어서 하나의 모델을 학습 ⇒ RDT, OpenVLA등 대부분의 VLA모델
-
unified action space를 정의, 한팔, 양팔 다 같이 pretraining ⇒ RDT
-
latent action space 사용, shared codebook 형태 ⇒ GROOT N1 & GO-1
-
⇒ unified action space로 표현하기 때문에, scratch부터 학습 필요
⇒ bimnaual의 multi-modality를 고려했을 때 data coverage가 낮음
-
본 논문의 저자들은 heterogenous action을 직접적으로 다루지 않고, foundation model을 써서 bimanual policy를 구축해보고자 함
- 이전에 영상을 통해서 trajectory를 uniformly하게 표현할 수 있다는 연구 결과가 존재
⇒ 자연어 기반 영상 처리 framework로 bimanual foundation모델을 가능하게 해보자!
(기존 text-to-video모델은 instruction following, generation 능력이 훌륭하다고 함 + motion semantic을 포착할 수 있고, 내재적으로 temporal dependency도 포착 가능)
-
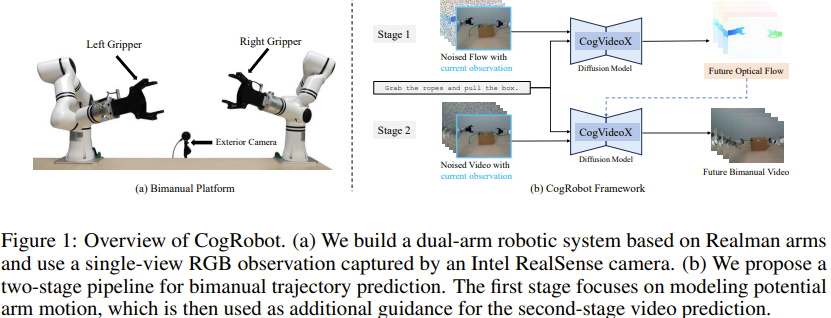
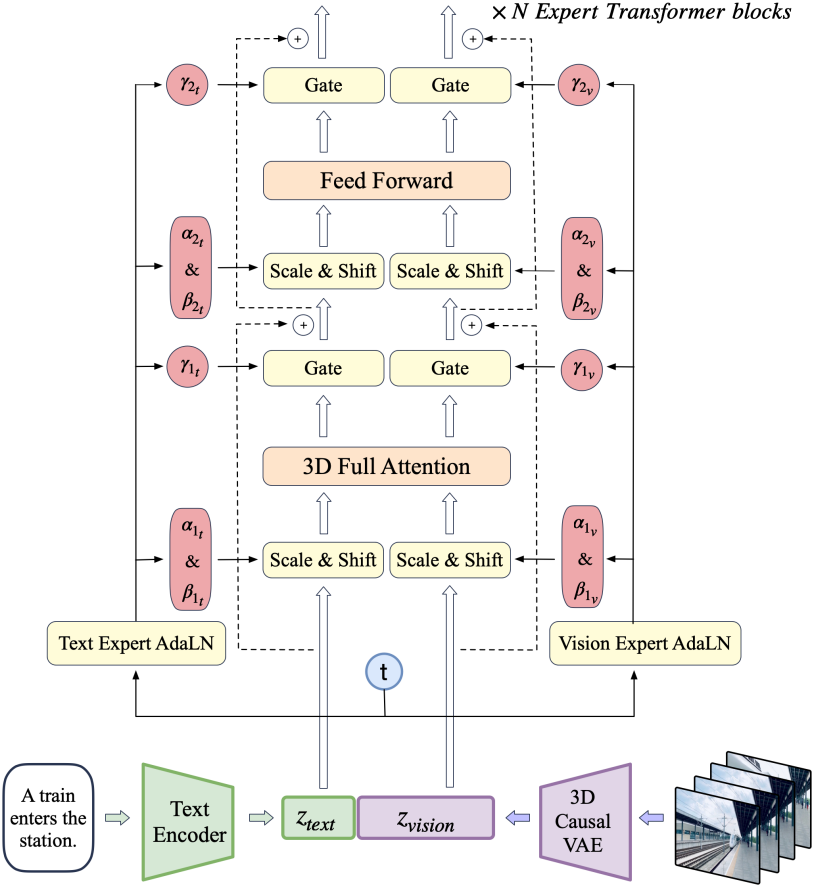
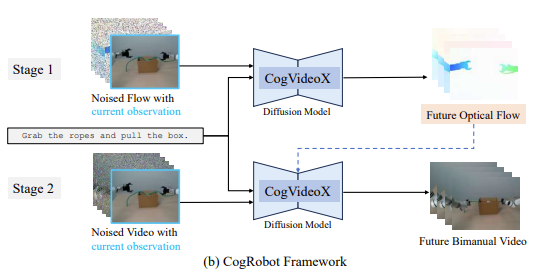
본 논문에서는 CogRobot를 소개, 기존 SOTA T2V model CogVideoX를 활용해서 bimanual policy를 구축
-
T2V모델에 초기 이미지와 task instruction을 넣어서 로봇 움직임에 대한 영상을 생성, 해당 영상의 프레임 goal state로 주고 diffusion policy로 구체적인 action space를 생성하는 구조
-
CogVideoX를 작은 bimanual dataset에 바로 FT할 경우 suboptimal한 결과가 나올 수 있음
-
⇒ 이를 위해서 중간에 optical flow를 생성, 이를 기반으로 최종 영상을 생성하도록 하는 구조를 사용
- text-to-flow : kinematic behavior과 로봇과 물체 사이의 interaction에 집중하여 optical flow를 생성
- flow-to-video : flow video, instruction를 기반으로 detailed video를 생성
⇒ language instruction에서의 모호함을 줄이고(?), FT에 필요한 데이터의 양을 효과적으로 줄임
-
본 논문의 contribution은 다음과 같음
-
T2V model을 활용한 bimanual foundation policy를 학습하는 프레임워크를 제안
-
T2V시, optical flow를 concise video representation으로 활용하여 적은 데이터로 FT이 가능한 two-stage paradigm 소개
-
high-quality bimanual manipulation dataset을 구축, simulation과 real robot에서 우리 방법론을 평가할 수 있는 dual-arm platorm을 구축
-
Preliminaries
- 본 논문에서는 7 DoF realman robotic arm과 external camera를 사용해 dual-arm system을 구축
- bimanual manipulation task T를 goal-conditined Partially Observable Markoc Decision Process(POMDP)로 formulate

-
VR device를 통해서 expert data를 수집 (Open-Television을 활용)
-
수집된 데이터셋은 episodic data를 포함
- video v, action sequence a, lanague description l
Proposed Methods
-
CogRobot에서, instruction-conditioned bimanual policy의 학습을 두 가지 스텝으로 분해
-
future obsercation trajectories를 예측 : o{t+1:t+N}=o{t+1},…,o_{t+N}
- current observation o_t를 기반으로 specified goal l을 달성하기 위한 로봇 움직임 영상
-
predicted observation sequence(o{t+1:t+N}=o{t+1},…,o_{t+N})를 기반으로 executable low-level action을 생성
-
-
최근 T2V model은 고품질의 realistic video를 생성하는 능력이 아주 굿 ⇒ 하지만 바로 bimanual에 FT하기엔 한계가 존재
-
dual-arm system은 coordination이 고려되어야 함
-
데이터가 너무 적음 (부정확한 영상 생성 확률이 높음)
-
⇒ T2f, f2V로 나눠서 FT
-
T2f: pixel-level motion encode, future optical flow 예측
-
f2V : future flow로 video생성
-
양팔 학습 데이터로는 RDT, ROBOMIND사용
Text-to-Flow Generation
-
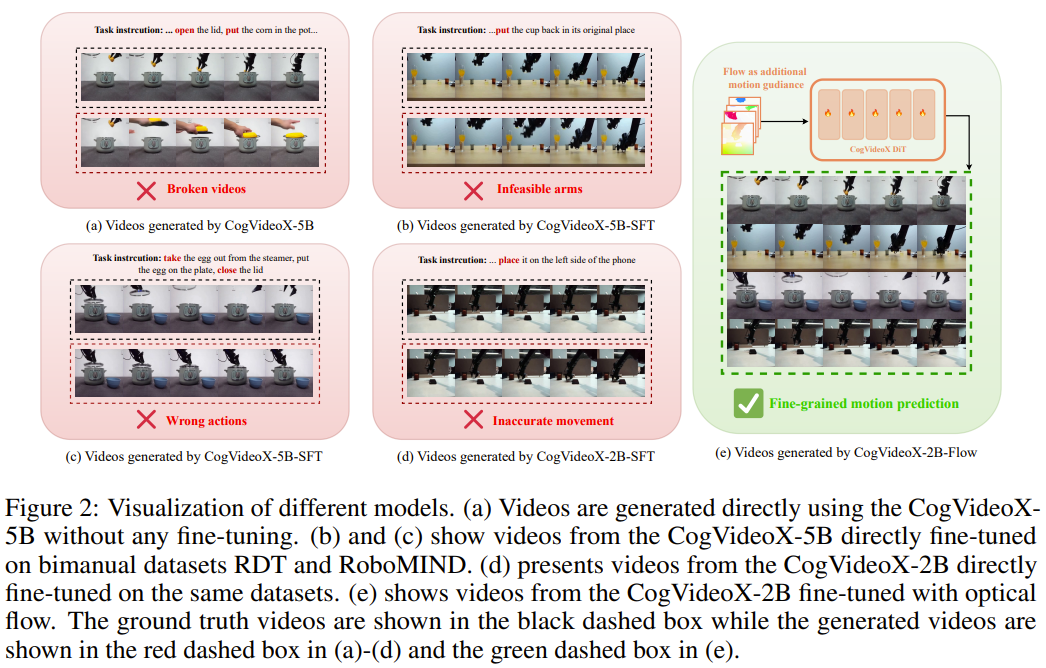
vanilla CogVideoX로 로봇팔 초기 이미지 넣고 생성해달라고 하면 사람 손을 생성함
- 초기 이미지보다 자연어 prompt에 더 집중하는 경향 존재
-
본 논문에서 CogVideoX 2B, 5B를 단순하게 SFT하는 버전 혹은 2 stage(T2f, f2V)로 나눠서 학습하는 버전 두 가지 모두 실험
-
vanilla 모델을 그대로 쓰거나 단순 SFT만 할 경우엔 다음과 같은 문제 발생
-
physical hallucination : 로봇 팔을 사람 손으로 바꿔버림
-
task confusion : long-horizon task일 때(A-B-C), 다음 task가 B인지 C인지 헷갈려 함
-
vague instruction : 현실적으로 로봇팔이 작동할 수 없는 agressive traejctory를 생성(precision부족)
-
-
이러한 문제를 해결하기 위해서 optical flow를 활용하는 방법론을 제안
- RGB observation pair가 있을 때, 그 둘의 optical flow를 pixel단위의 displacement field로 계산

-
즉, f는 각 픽셀별로 (u,v) 2차원의 벡터로 표현됨
-
보통 로봇에서 두 obsercation의 차이는 robot arm의 움직임에서 기인하기 때문에, 해당 정보를 활용하면 kinematics, interaction with arm and object등에 대해 모델링이 가능

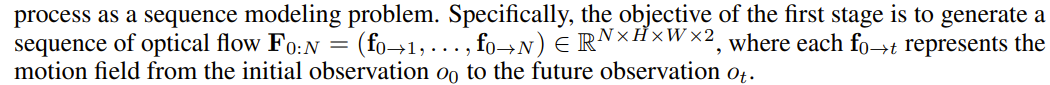
-
하지만 2-optical flow와 3-channel RGB image사이의 modality차이 때문에, t2v모델로 raw optical flow를 바로 예측하게 학습하는건 어려움
- 이전 논문에서는 추가적인 flow VAE를 scatch부터 학습하는 방법론이 필요했지만, 현재 세팅에서는 데이터 자체가 적기 때문에 적합하지 않음
-
optical flow를 flow video format으로 변환해 사용

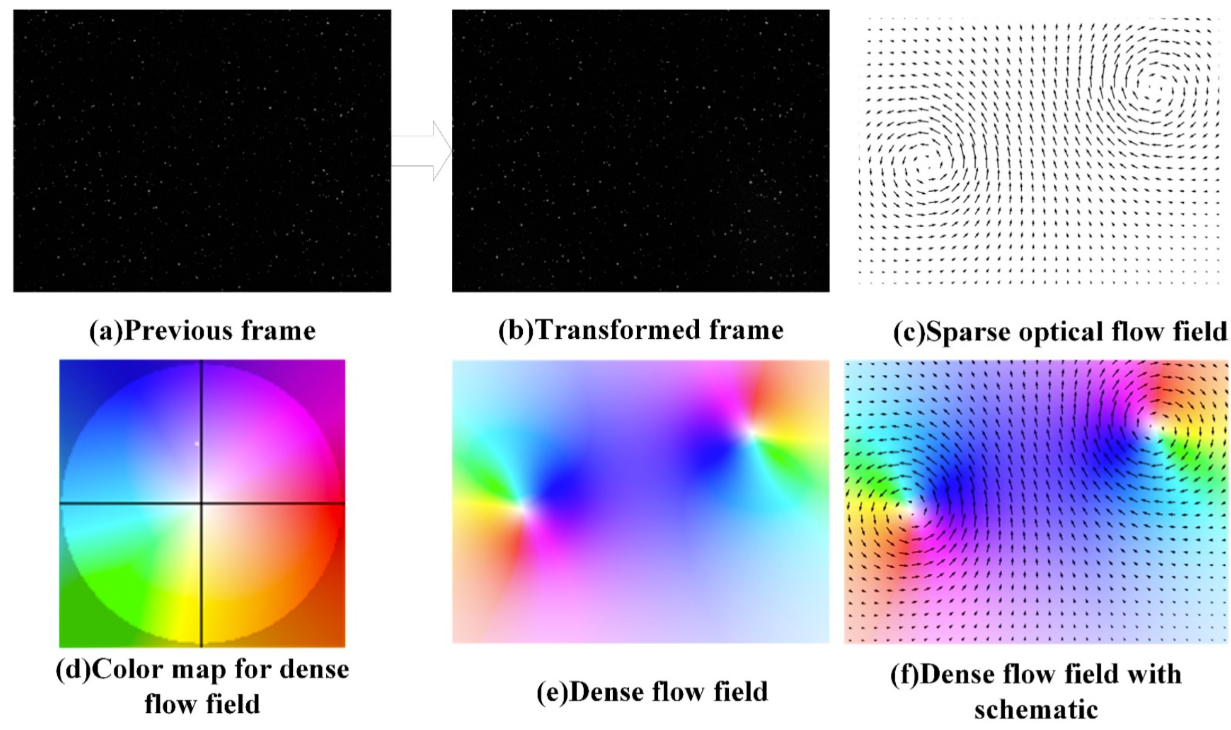
-
위의 transformation을 통해, flow generation task는 flow video에 대한 distribution을 학습하는 것으로 reformulated될 수 있음
-
pretrained CogVideoX를 사용, 학습 시 flow video를 latent z로 encode하는 VAE를 freeze
-
latent는 점점 noise를 더하면서 perturb됨
-
각 denoising step k에서 모델은 noisy latent z를 받아서 상응하는 noise eps를 예측하도록 함
-
-
- **CogVideoX architecture**
Flow-to-Video Generation
-
text-to-flow model을 기반으로, flow-to-video model을 구축
- 이전엔 low-level action input에 의존했다면, 해당 방법은 high-level semantic 정보를 받기 때문에, 로봇팔과 물체 식별에 도움이 됨
-
해당 방식의 우수성을 보이기 위해서, instruction의 특정 단어를 선택, 해당 단어에 대한 cross-attention map을 추출해서 영상과 잘 mapping이 되는지를 봄
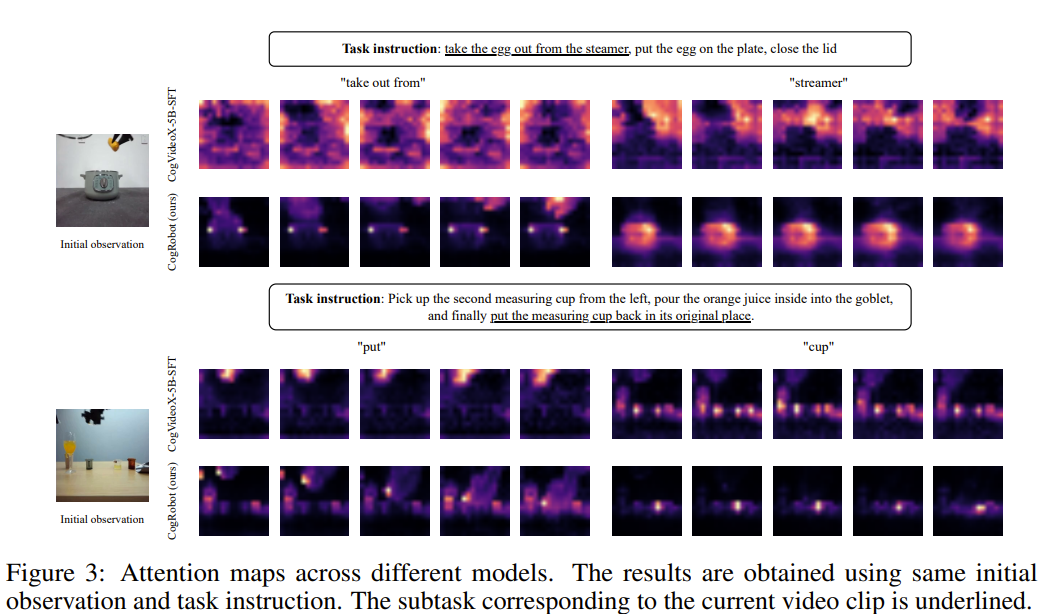
-
해당 그림을 보면, language-only model의 경우(그냥 SFT) meaningful region을 식별하는데 실패하는 것을 볼 수 있음
-
flow video를 중간에 생성, 이를 기반으로 detailed vidoe를 생성함으로써, intruction과 visual input사이의 더 나은 alignment를 달성
-
첫번째 단계에서 생성한 flow video를 잘 활용하여 detailed video를 생성할 수 있도록, flow video와 RGB vidoe를 channel dimension에 따라서 concat하는 방법론을 제안
-
학습 동안, flow video v_F과 dual-arm trajectory video v는 VAE에 각각 encoding되고, z_f, z_v^0으로 나옴
-
flow generation의 절차와 동일하게, video latent z_v^0은 noise로 perturb되고(z_v^k), noisy latent는 flow latent와 content되어서 z^k=[z_v^k,z_f] 모델로 들어감
-
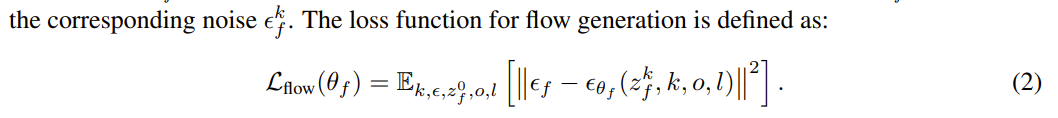
Diffusion policy from Videos
-
predicted video의 각 프레임을 target observation으로 사용해서 excutable low-level action을 생성
-
학습 동안, goal step을 랜덤하게 추출, 노이즈를 활용해서 progressively perturb

Related works
-
Bimnaual의 challenge
-
data scarcity
-
expanded action space
-
diverse collaboration modality
-
simulation fidelity한계
-
가격이 괜찮은 realj-world interface부재
-
-
이전에 나온 연구
-
저비용 teleoperation system(mobile aloha)
-
data augmentation(dexmimicgen)
-
human-object interaction primitive(YOTO)
-
key point를 통해 geometric constraint추출
-
attention으로 dual-arm mechanism 모델림
-
-
이전 video generation 활용 연구
-
VidMan : OpenSORA를 OXE에 학습
-
다른 애들은 robot action을 기반으로 world model를 구축
-
** optical flow를 썼다는게 본 논문의 핵심 차별점
Experiments
Experiment setup
-
Simulation setup
- RoboTwin으로 평가
-
Real-world setup and data collection
-
양팔을 책상 사이드에 마운트, front-facing camera만 사용해서 세팅
-
Vision Pro로 tele-operation
-
-
Architecthre Detail
-
text-to-flow, flow-to-video mdoel은 pretrained CogVideoX-2B로 초기화
-
먼저 bimanual dataset 2개(RDT, RoboMIND)로 초벌 FT, 이후 각 평가 task의 demonstration에 대해서 추가 FT
-
모든 비디오는 256x256, 17프레임으로 구성됨
-
text-to-flow model의 경우 FlowFormer++를 사용해서 각 비디오 클립에서 ground-truth optical flow를 추출
-
-
Baseline
-
DP(diffusion policy)(86M) : conditional denoising diffusion모델로 action을 생성하는 방식
-
RDT(2B) : 양팔 데이터셋으로 pretrain된 VLA모델
-
DP3 : point cloud기반 표현을 활용한 3d 기반 방법론
-
text-to-flow model, flow-to-video model, RDT는 mixed multi-task dataset에 학습되지만, downstream goal-conditioned policy와 다른 baseline은 single-task dataset에만 학습
-
각 태스크는 100개의 demonstration으로 구성
-
RDT에서는 카메라로 D435사용(default), 나머지는 L515 사용
-
-
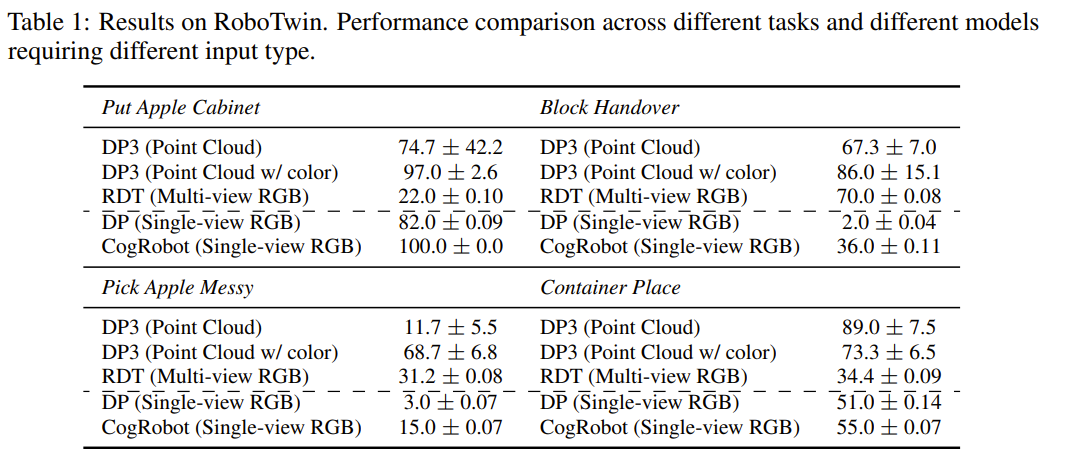
Main result in simulation setup
- 각 태스크 별로 10개의 random seed를 활용해서 평가, 각 시드마다 10번 돌리고 평균냄
-
single camera를 사용하기 때문에 vanilla DP는 다른 추가적인 visual input(3d representation이나 multi-view images)을 사용하는 baseline보다 낮게 나옴
-
하지만 future state를 예상하는 능력이 추가된 CogRobot의 경우 제한적인 image input으로도 높은 성능을 보임
Real-World experiments
-
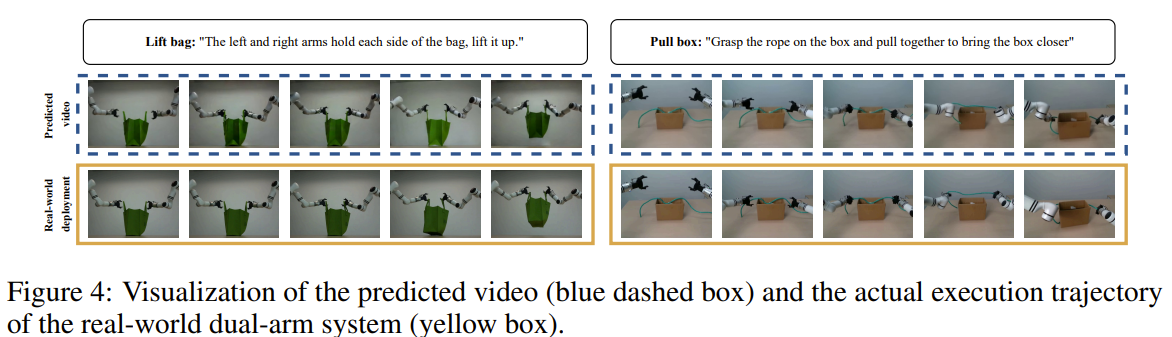
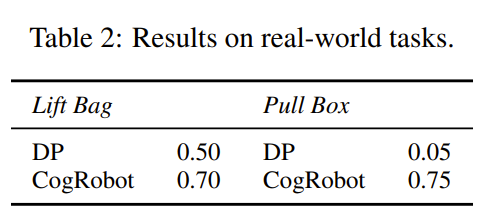
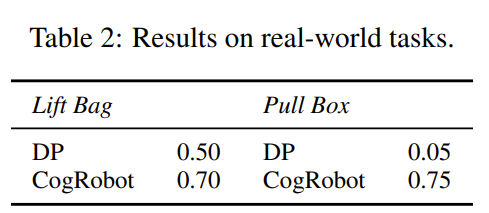
2가지 task로 평가
-
Lift bag : 양팔로 가방 드는 task
-
Pull box : 박스 안의 밧줄을 들어서 그걸로 박스를 가까이 가져오는 task(multi-stage task)
-
-
각 task마다 사람이 100개의 demonstration을 직접 수집
-
우리 방법론의 view adaptabilites를 평가하기 위해 각 태스크는 다양한 camera viewpoint에서 기록됨
-
이 demonstration을 활용해서 RDT와 RoboMIND에 1차로 FT된 CogVideoX-2B모델을 추가로 FT
-
baseline으로는 DP만 활용
-
실험 결과, 확실히 어려운 task(pull box)에서 CogRobot의 성능이 높게 나옴
-
video prediction model 을 high-level planner로 사용하는 것에 대한 장점을 보임
-
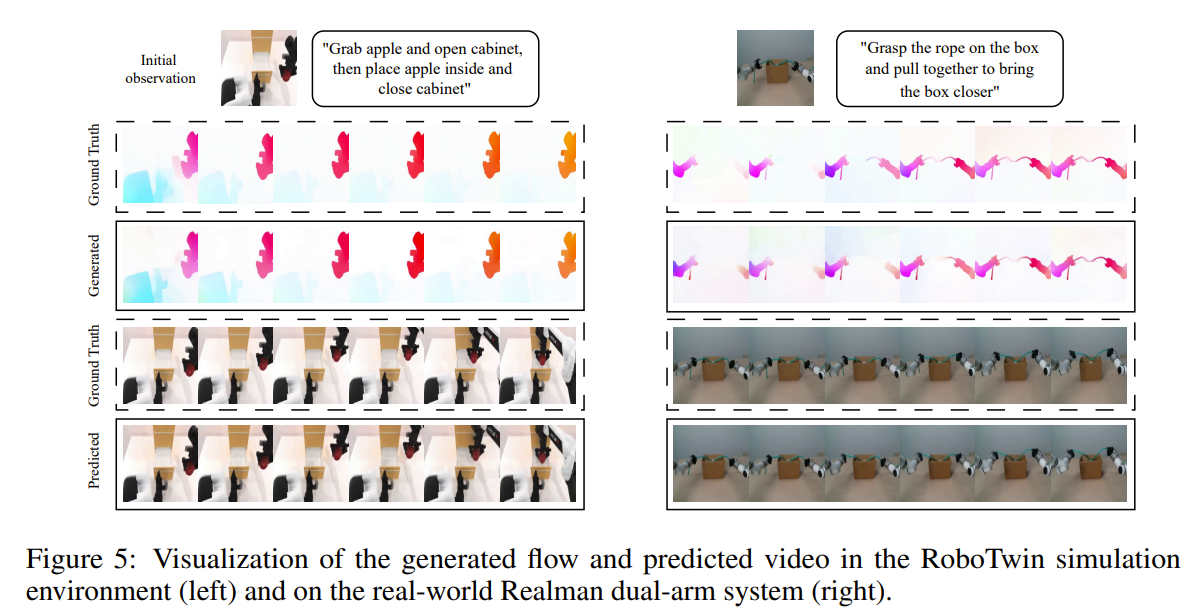
위의 그림을 봤을 때, 실제 teleopration한 영상과 predicted video가 큰 차이가 나지 않음
-
Visualization and Ablation
-
Visualization
-
optical flow와 manipulation video를 시각화
-
우리 모델 optical flow 잘 예측하더라!
-
-
Ablation
-
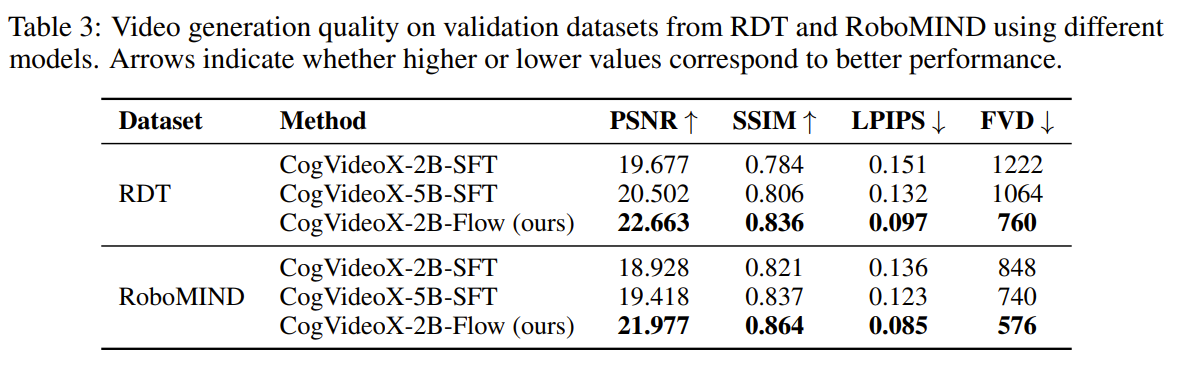
flow-guided video prediction과 그냥 SFT의 영상 생성 능력을 평가
-
CogVideoX-2B,5B를 같은 해상도, 비디오 길이를 사용해서 RDT와 RoboMIND를 합쳐서 학습
-
평가시에는 RoboMIND validation set 5346개, RDT validation set 1757개로 평가
-
4가지 metric을 사용
-
PSNR : 재생성된 이미지/영상이 얼마나 원본에 가깝게 복원되었는지를 픽셀 단위에서 측정
-
SSIM : 두 이미지간의 구조적 유사성을 측정(밝기, 대비, 구조) - patch단위로 비교
-
LPIPS : 두 이미지 간의 지각적 유사성을 딥러닝 feature space에서 측정(사전 학습된 CNN의 여러 레이어에서 feature 추출, 둘의 차이를 L2 norm으로 계산)
-
FVD : 영상 전체 시퀀스의 품질을 측정 - 영상 시퀀스를 feature space에 mapping, 분포간 거리를 측정
- I3D등의 video model에서 feature추출, 실제와 생성 비디오의 gaussian 분포 간의 FVD계산
-
-
Conclusion
-
bimanual policy를 구축할 때 T2V 모델을 활용
-
적은 데이터에서 효과적으로 T2V를 FT하기 위해 flow-guided framework를 제안
-
방법론은 신박한데 평가가 아쉽다