TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
논문 정보
- Date: 2025-01-02
- Reviewer: 전민진
- Property: Robotics, Evaluation Metric
Abstract
-
기존 VLA 모델들은 로봇 분야의 policy generalization에 큰 영향을 끼쳤으나, 여러 가지 보완해야할 부분들이 있음
-
본 논문에서는 보완해야할 점 중에 하나로 Spatial-temporal dynamics을 지적
- 기존 모델들이 이전 trajectory history를 고려하기 위해, 직전 T개 혹은 1개의 프레임을 입력으로 받음
⇒ 로봇이 어떤 방향으로 움직이고 있는지 포착하기 어렵고, 포착할 수 있다 하더라도 불필요한 연산이 많이 소요 (observation이미지의 대부분 - 배경 은 바뀌지 않음)
-
state-action trajectories를 인코딩해서 action prediction을 위한 spatial-temporal awareness를 향상시키는 visual trace prompting을 제안
- 로봇의 과거 움직임 궤적을 이미지에 표현하고, 그 이미지를 prompt로 넣는 방법
-
OpenVLA를 finetuning해서 TraceVLA를 제작, visual trace prompting학습을 위한 150K robot manipulation trajectories를 수집
-
실험 결과, SimpleEnv의 137 config에서 우수한 성능을 보임, WidowX robot을 활용한 real experiment에서도 높은 성능을 보임
Preliminaries
-
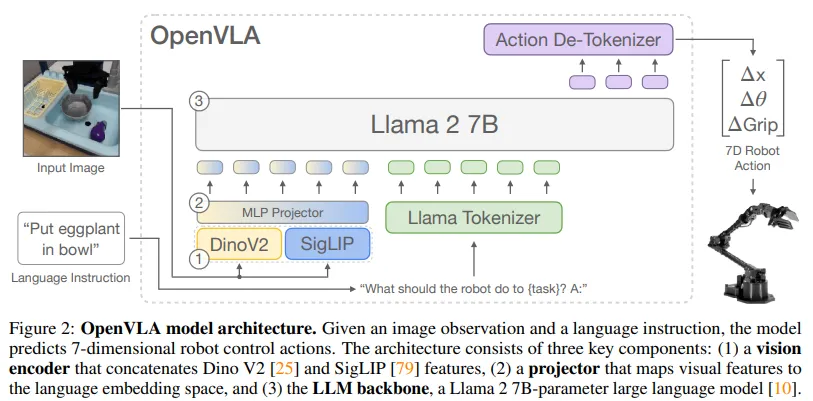
OpenVLA
-
최초로 공개된 LLM기반의 VLA모델
-
image는 2가지 visual encoder를, text는 tokenizer를 통해서 토큰화, embedding을 거쳐서 LLM에 입력으로 넣음 ⇒ output으로는 action token을 생성, De-Tokenizer를 통해서 로봇의 구체적인 좌표를 출력
-
장점
-
curation한 Open-X dataset 150K를 사용해서 VLA를 finetuning, 다양한 환경에서도 성능이 어느정도 유지되는 general policy를 제안
-
VLA 모델을 학습할 때, 어떠한 방식으로 해야하는지 개괄적인 베이스라인을 제공한 느낌
-
-
단점
-
Only supports single-frame input
- 현재 state를 표현하기 위한 수단으로 직전 frame만 image로 제공
-
Only supports single-frame input and single-step action output
-
because large model → low training/inference speed with more inputs/outputs
-
Q: How would performance change with additional inputs/outputs (e.g., robot proprio states, observation history, action chunking)?
-
-
Lack of support for high-frequency control / bi-manual manipulation robots
-
e.g., ALOHA
-
(Difficult to run OpenVLA at >7Hz control without special tricks - e.g. if we are using local GPUs or even remote H100 servers)
-
Q: CanVLM inference speed-up tricks enable high-frequency VLA control?
-
-
VLM fine-tuned only on robot action data (not co-fine-tuned on robot data + VQA data, as done in RT-2/RT-2-X)
-
potential catastropic forgetting of Internet-pretraining concepts that do not appear in robot interaction data
-
현재는 1개의 visual input으로 1개의 action이 출력되는 세팅
-
-
-
Introduction
-
Robotic manipulation policies는 보통 specific task demonstration에 학습되기 때문에 학습 데이터를 넘는 generalization 능력은 매우 부족
- novel object, environment, instruction, embodiment
-
VLM 모델은 높은 일반화 성능을 보임
- 하지만 바로 이를 embodiment configuration에 이를 적용하기엔 kinematics를 이해하는 거라던가.. 여러 어려움이 존재
⇒ VLM을 robotics dataset를 기반으로 FT한 여러 VLA 모델들이 소개됨
-
하지만 VLA모델의 경우 과거의 움직임을 고려하지 않고, 과거 spatial-history 정보보다 현재 상태에 더 반응해서 결정을 내리는 경향이 있음
-
저자들은 이 현상의 원인이 로봇을 컨트롤 하기 위해 현재의 input을 state에 단순히 mapping하는 방식으로는 충분하지 않기 때문이라고 지적
- 기존 vla는 현재 상태의 image + text instruction ⇒ 액션 좌표를 생성하게 하도록 하는 방식
-
spatial과 temporal rationale을 효과적으로 제공하는게 manipulation task를 향상시키는 key일거라 가정
-
-
본 논문에서는 위와 같은 문제를 해소하기 위해서, 로봇의 과거 움직임 trajectory를 트래킹하는 multi-point visual input을 추가적으로 사용
-
multi-point trajectories를 visual trace라고 지칭, 이는 기존 사진에 여러 포인트의 trajectory를 표시한 형태
-
결론적으로는 2d input image를 하나 추가한 셈이지만, 훨신 더 향상된 spatial-temporal awareness를 보임
-
-
visual trace prompting을 사용하는 TraceVLA를 제안
-
OpenVLA를 모델을 저자들이 제작한 visual trace prompting dataset에 finetuning한 모델
- Phi3-vision을 백본으로 쓴 4b 크기의 VLA도 공개
-
실험 결과, 다양한 variance를 기반으로 하는 실험에서 높은 성능을 보임
-
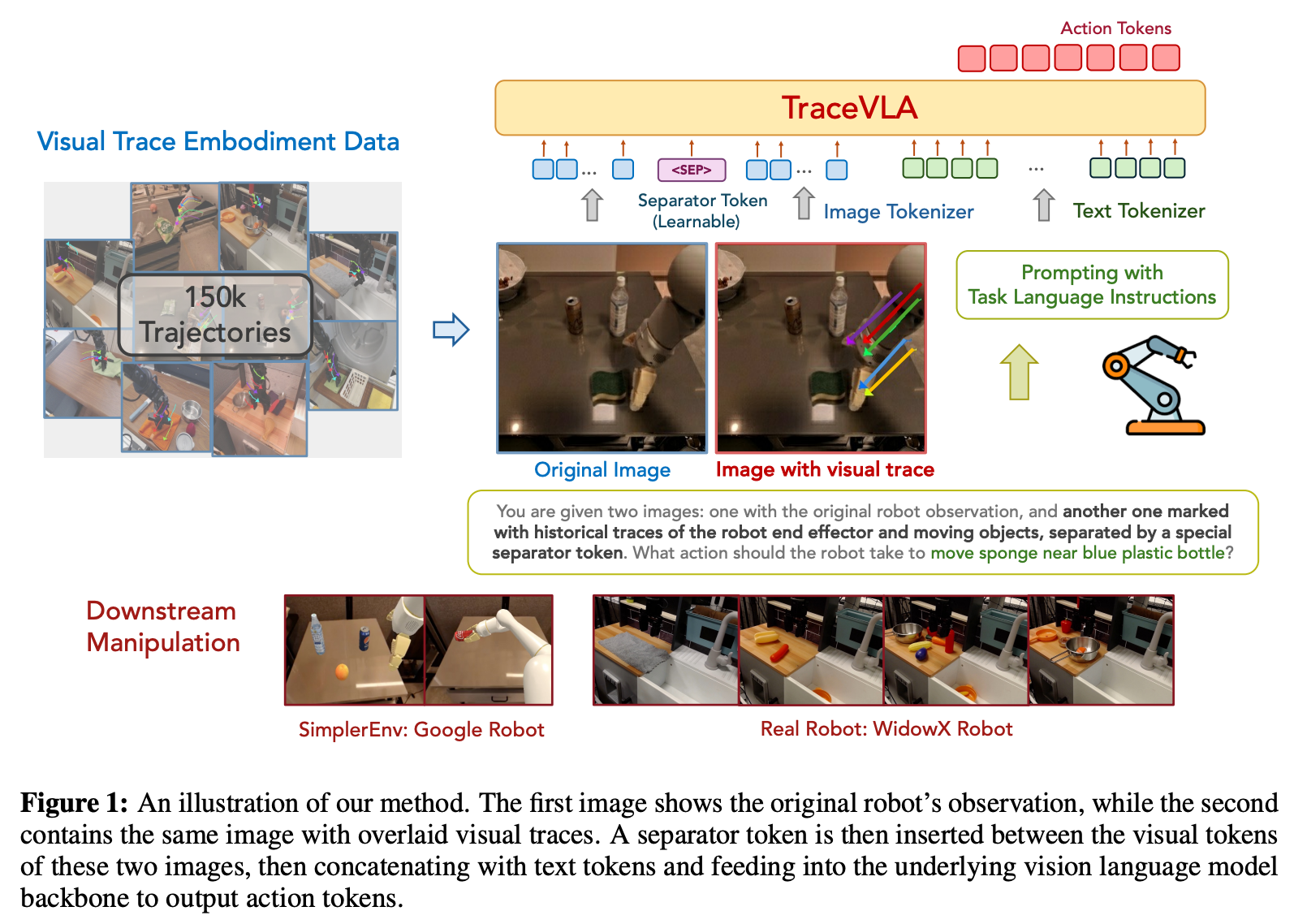
TraceVLA
Visual Trace Prompting
-
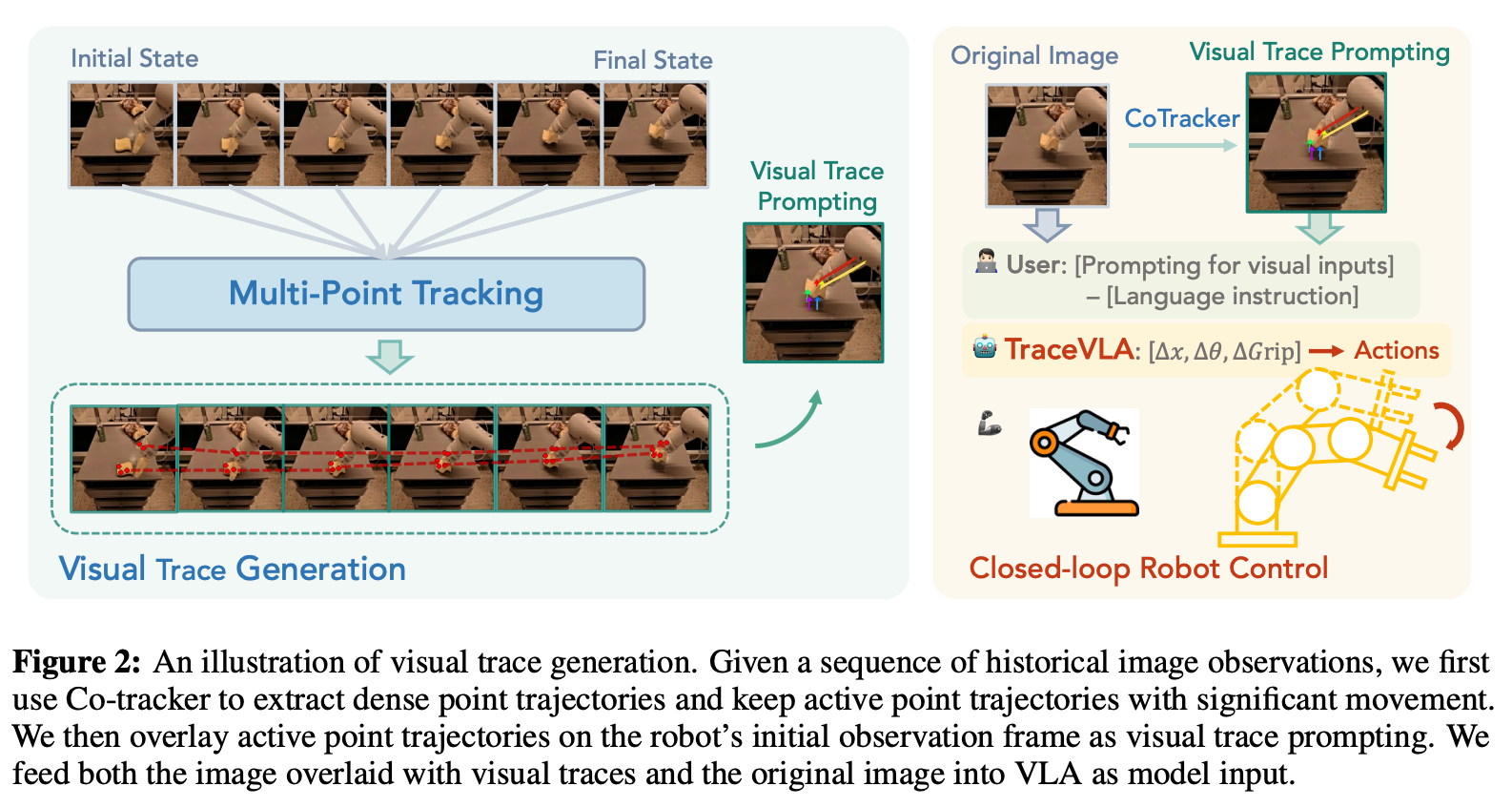
visual trace prompting을 위해서, 과거 프레임을 단순하게 concat하는 것이 아니라, key point의 trace를 생성하기 위해서 off-the-shelf point tracking algorithm을 사용
- 이러한 visual trace는 original observation 위에 표시되어, historical action의 spatial memory를 모델한데 제공하는 visual prompt의 역할을 수행
[Visual trace를 생성하는 방법]
-
timestep t, time window budget N이 주어질 때, 우선 historical image observations ht = (o{t-N},…,o_t)에서 dense point trajectories 집합을 추출
-
dense point tracking 모델로는 Co-Tracker를 사용
-
Co-Tracker는 starting frame o_t 를 K x K grid로 나눠서, 각 그리디 셀을 N개의 frame동안 point trajectories를 구축해 tracking하는 방법론
-
-
K x K개의 tracking point가 만들어진 후, 그 중에서 active point만 식별하기 위해서 pixel location에서의 change를 계산
-
\Delta p*{t’} = p*{t’+1}-p_{t’} _1 - active point trajectories
-
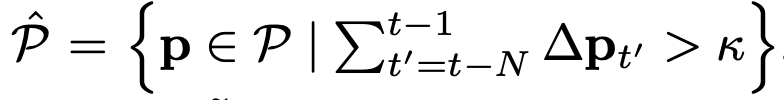
-
\hat P에서 M개의 active point trajectories를 sampling, 이를 visual prompting에 사용
-
sampled active point trajectories를 robot의 original observation frame에 그림, 이를 visual prompt으로 최종적으로 사용
Model Architecture Design
-
위에서 만든 visual prompt와 original observation을 모델의 input으로 사용
-
spatial-temporal 정보만 제공할 경우, 오히려 방해가 될 수 있다고 판단
- trajectory가 로봇의 End-effecor나 key object를 방해할 수 있기 때문
-
visual prompt와 original observation사이에 special sperator token([SEP])를 넣어 분리
-
-
test시 visual trace를 사용하지 못하는 상황이 발생할 수 있으므로, 학습 동안에 dropout mechanism을 구현
-
Co-Tracker가 나쁜 조도 환경에서는 성능이 몹시 안좋음
-
\alpha의 확률로, visual trace prompt image를 original image로 교체, text prompt에서도 이에 대한 말은 삭제
- Co-Tracker model이 visual trace를 추출하지 못하는 상황에서도 VLA모델이 정상적으로 작동하도록 함
Implementation Details
-
학습시 visual trace generation pipeline에 대해서, grid size K=40, sample M=5, time window N=6을 사용
-
computational overhead를 줄이기 위해서, dense point tracking은 N step마다 2N step에 대해서 실행
- demo trajectories를 겹치게 2N 크기의 segment로 나누고([0,2N],[N,3N]…), Co-Tracker를 각 segment마다 한번씩 실행
-
토탈 150K tracjectories를 annotate, TraceVLA를 finetuning 하기 위한 학습 데이터를 구축
- bridgeData-v2, Google RT1 Robot dataset, 120 demonstrations collected from 4 multipulation task on our WidowX-250 Robot setup에 visual trace generation 파이프라인을 적용
-
inference시 real-time visual trace를 위해, 매 타임스텝마다 densely querying이 아닌 M active point를 tracking를 함
- t=0일 때만 dense KxK point tracking해서 active tracker를 식별하고, t>0일 때는 active point에 대해서만 Co-Tracker를 query, M개의 trace를 생성, 업데이트
-
OpenVLA 7B모델을 기반으로 학습, 추가적으로 Phi3-Vision를 백본으로 사용
-
Phi3-Vision의 경우 OpenVLA와 같은 레시피로, Open-X-Embodiment로 pretrain하고 FT
-
둘다 5 epoch만큼 FT
-
Experiment
- 3 task를 137개의 configuration으로 simulation에서 실험, real robot으로 4 task에 대해 실험
Baselines
-
OpenVLA : Open-X-Embodiment로 학습한 7B VLA
-
OpenVLA-Phi3 : Phi-3-Vision을 backbone으로 Open-X-Embodiment로 학습한 4.5B VLA
-
Octo-Base : Open-X-Embodiement에서 800k trajectories로 학습한 transformer기반의 Policy(93M)
-
RT1-X : Octo와 같은 데이터셋으로 학습한 35M parameter의 모델
-
TraceVLA, TraceVLA-Phi3 : OpenVLA, OpenVLA-Phi3을 visual trace prompting으로 FT한 모델
Simulation Evaluation
-
SimplerEnv를 사용해서 평가, visual matching, visual aggregation이라는 setting을 사용
-
visual matching은 real environment와 Raw simulation사이의 visual appearance gap을 최소화하는게 목표인 세팅
-
visual aggregation은 넓은 범주의 Environment variation을 커버하는 세팅
- background from different room, lighter and darker lightning condition, varying number of distractors, solid color and complex table textures, different robot camera poses
-
-
Overall performance
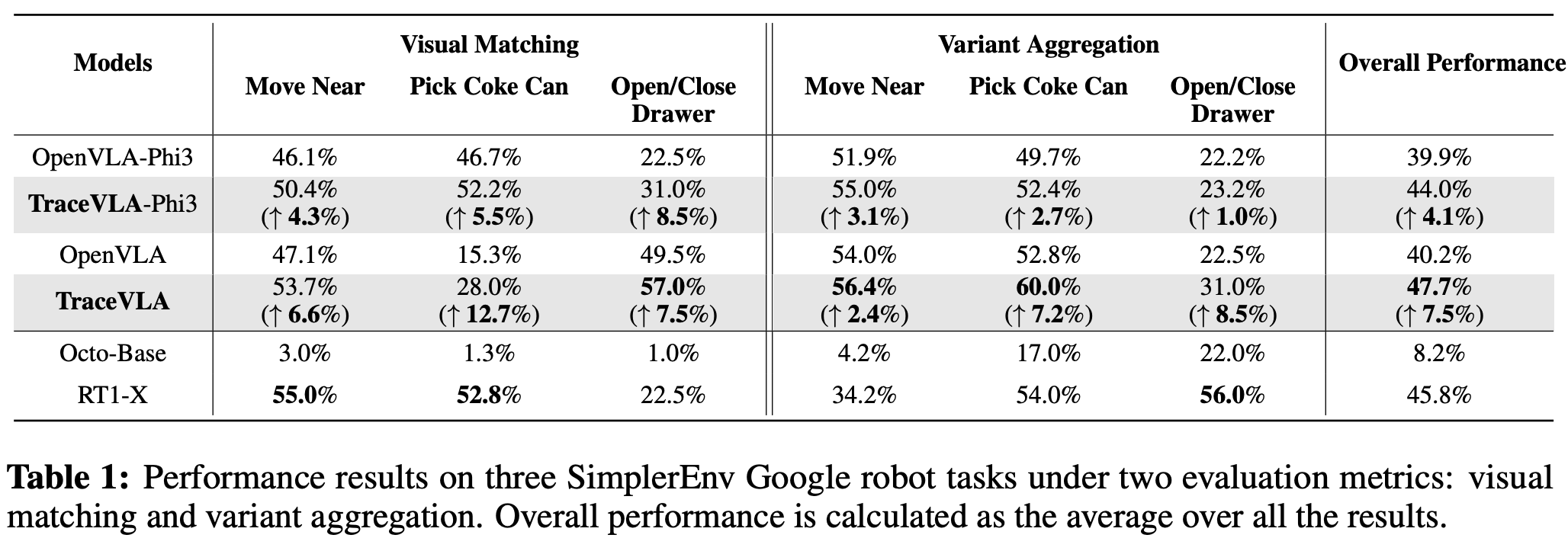
-
실험 결과, 기존 OpenVLA모델보다 TraceVLA가 모든 세팅에서 더 높은 성능을 보임
-
visual trace prompting이 모델의 일반화 성능을 강화시킴
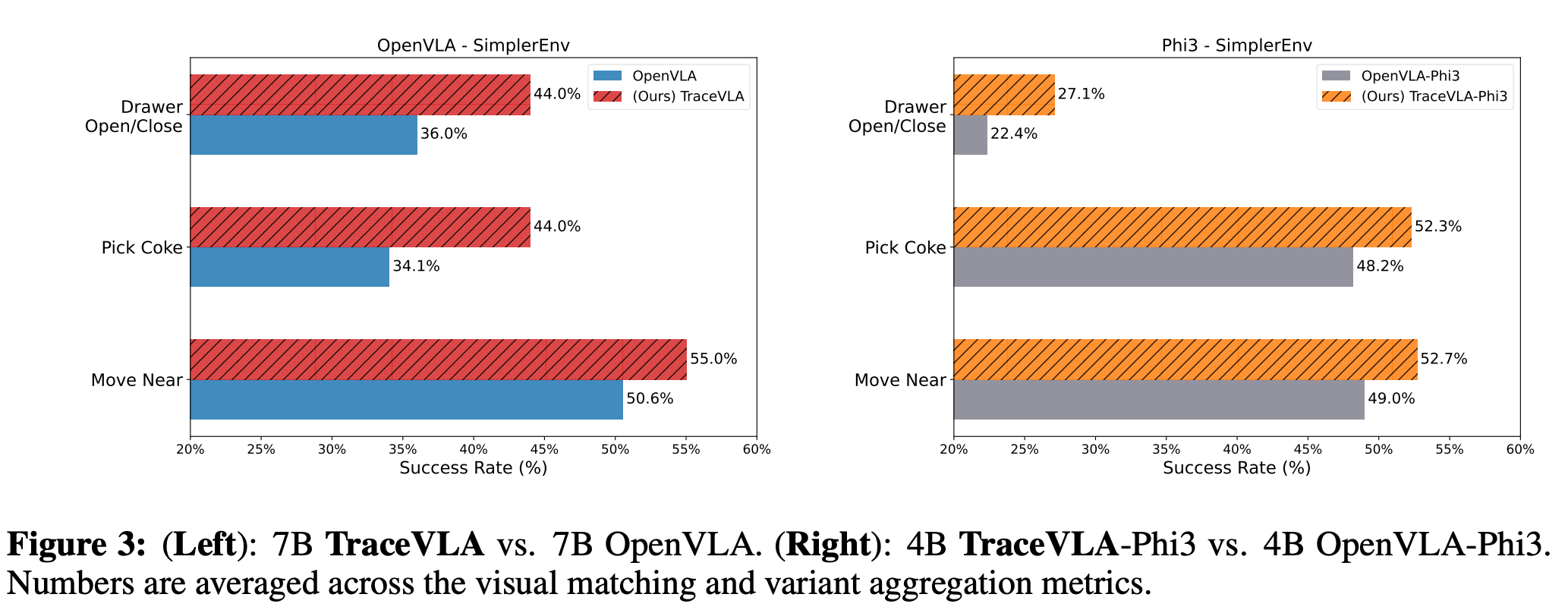
- Environmental Variant Aggregation
-
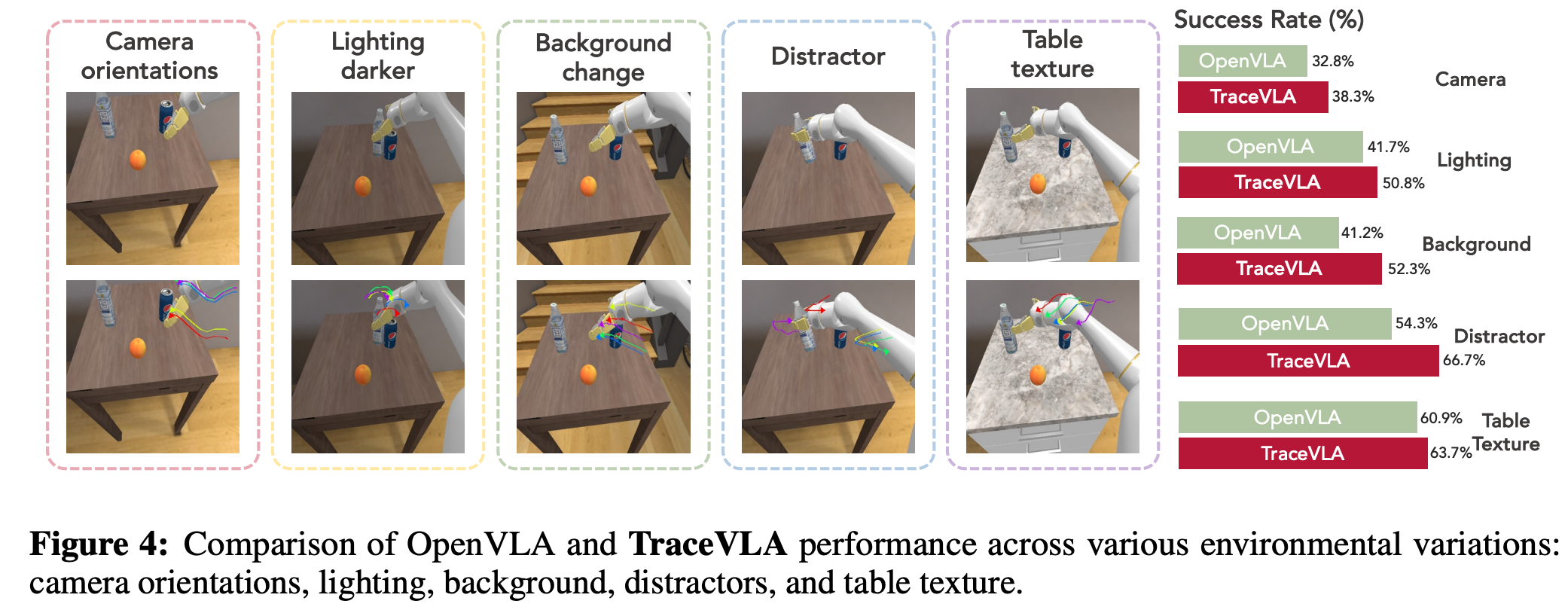
여러 환경변수를 바꿨을 때의 성능을 측정
-
측정 결과, 모든 세팅에서 TraceVLA가 보다 높은 성능을 보임
-
visual trace prompting이 카메라 앵글이 바뀔 때에도, 유의미한 spatial trajectory 정보를 제공하기 때문인 것으로 보임
-
카메라 앵글 외에, 배경이 바뀌거나, table texture, lighting alteration과 같은 environmental background에 대해서도 영향을 덜 받고, stable하도록 함
-
Real Robot Experiments
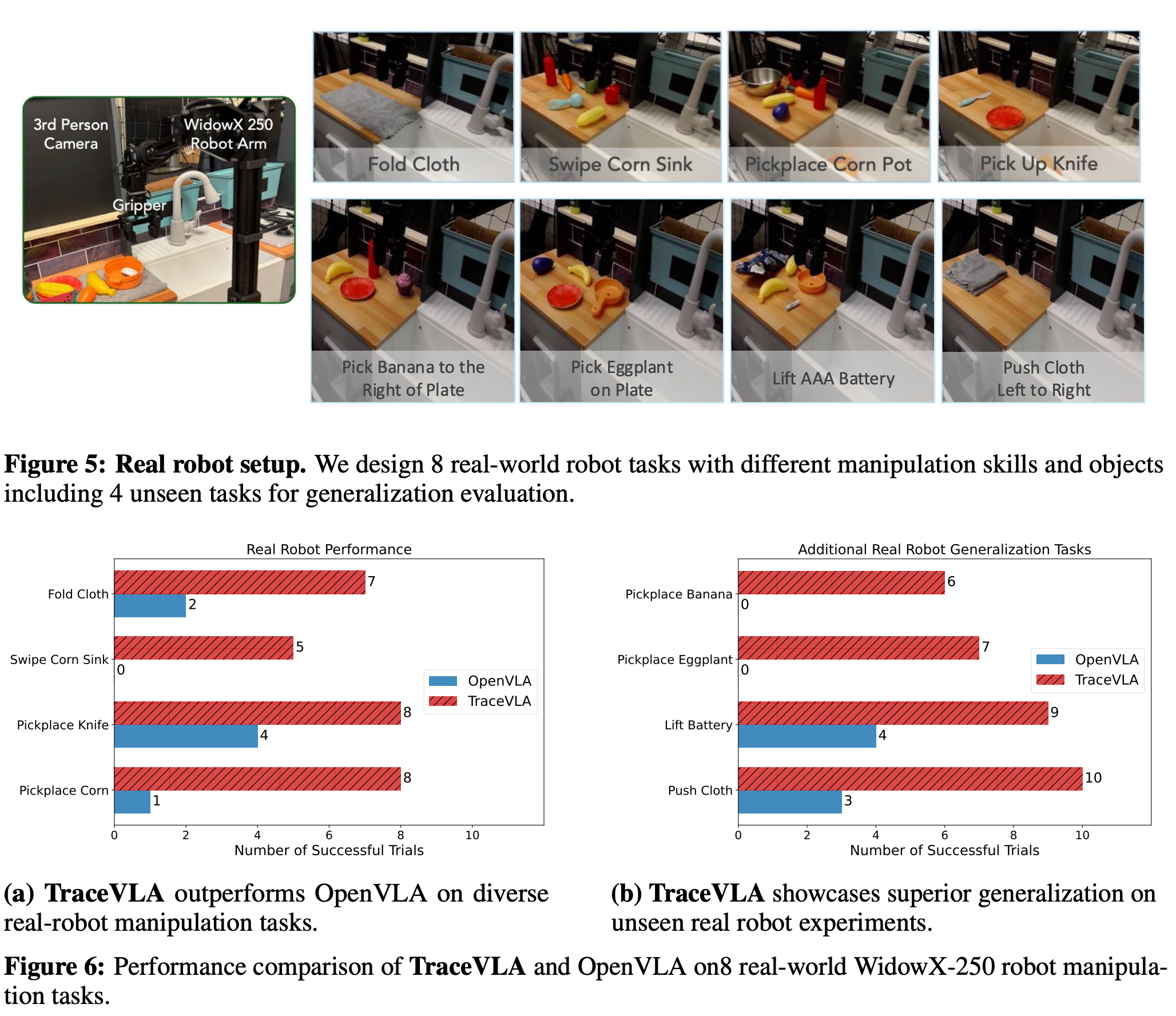
-
TraceVLA를 WidoxX-250에 fixed-mounted third-person view camera capturing 256 X 256 RGB image를 사용하는 세팅에서 평가
-
BridgeData-v2와 같은 로봇 세팅이지만, setup, lighting, camera angle등의 차이를 위해 각 Task별로 30개의 trajectories를 수집, finetuning에 사용
-
실험 결과, 다양한 task에서 높은 성능을 보였고, 특히 pick-place corn task는 training data에 없었음에도 높은 성능(8/10)을 보임
-
generalization capabilities를 평가하기 위해서, 4개의 unseen task에 대해서 추가 실험 진행
- pushing cloth외의 task에서 각 트라이는 2-3개의 distracting object를 포함함
-
generalization 실험 결과, OpenVLA보다 압도적인 성능을 냄
-
특히, 바나나 잡아서 옮기기 태스크에서 TraceVLA가 실패한 트라이는 바나나를 못 잡어서라고 함
-
하지만 OpenVLA의 경우 바나나를 잘 잡아도 instruction을 잘 follow하지 못해서 실패함
-
⇒ TraceVLA는 language grounding capability가 향상됨, spurious correlation에 강건함
Ablation Study
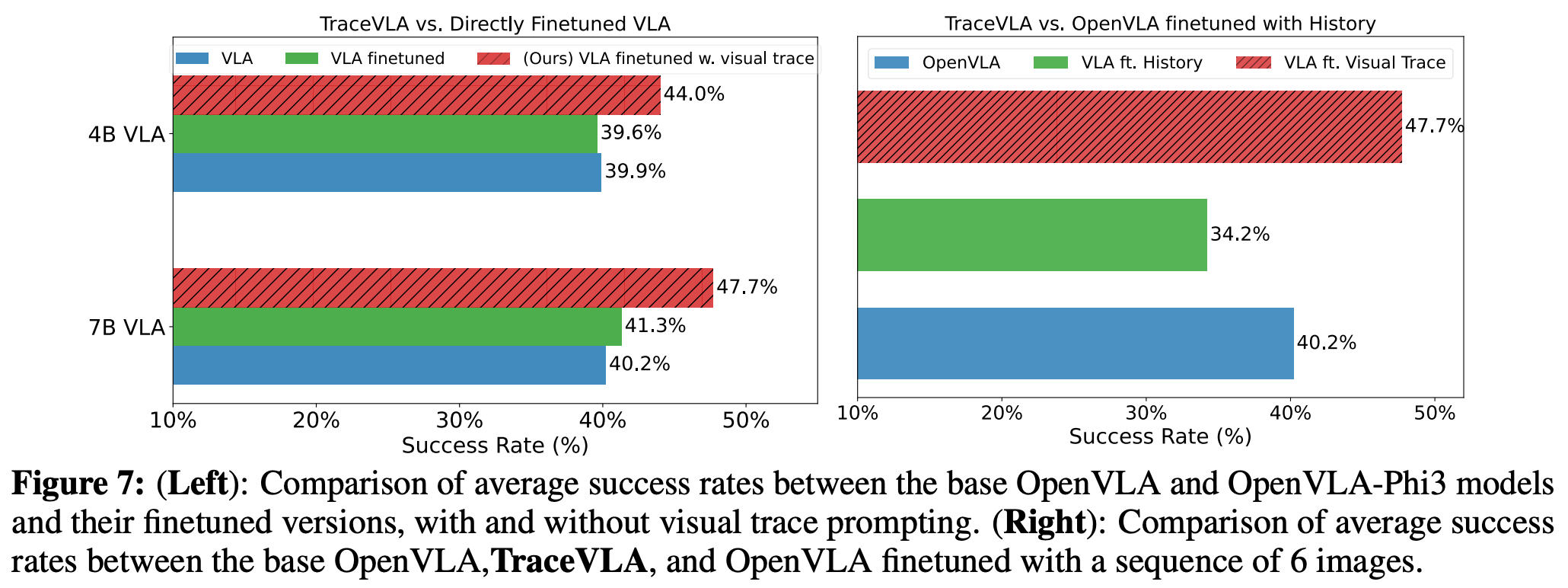
Q. Open X-embodiment dataset의 smaller subset으로 further finetuning을 해서 TraceVLA의 성능이 오른게 아닐까?
- Figure 7의 왼쪽 그림을 보면 VLA further FT의 경우 VLA와 성능이 거의 비슷, 하지만 VLA w visual trace는 성능이 크게 상승
⇒ visual trace의 역할이 중요!
Q. historical image observation을 appending하면 TraceVLA처럼 성능이 향상될까?
-
N=6, 과거 frame을 input으로 제공(frame사이에 sep token 넣어줌), 학습
-
Figure 7의 올느쪽 그림에서 VLA.ft History성능을 보면 더 낮아지는 것을 확인할 수 있음. 이 이유는 다른 timestep의 visual token사이의 redundant information 때문으로 추정

Q. visual trace prompting이 text trace prompting보다 더 좋은 성능을 보이나요?
-
visual trace를 orignal image에 얹어서 가이드 하는 방식 외에, 포인터의 움직임을 2D 좌표를 텍스트로 표현해서 input으로 넣을 수도 있음
-
실험 결과, text보단 visual prompting이 효과가 더 좋았으며, text prompting의 경우 visual prompting에 비해서 토큰수가 증가(~150 token), GPU cost가 더 많이 듦
-
text에 의존하는건 VLM 모델의 multimodal grounding 역량을 풀로 사용하기 어렵다고 함
Q. TraceVLM가 visual-trace의 길이에 따라 어떻게 영향을 받나요?
-
N이 커지면 visul context가 지저분하게 되고, key object나 robot end-effector를 방해할 수 있고, N이 작아지면 historical information을 덜 갖게 됨
-
실험 결과, N=6일 때의 성능이 가장 높았음
- 3일때는 너무 간결해서 성능 향상 폭이 적으며, 12일때는 key scene element를 이전 motion trace가 가려서 희미하게 함
Limitation analysis
-
TraceVLA는 CoTracker가 필요하다보니, 이에 따른 추가적인 cost를 H100 GPU 1대로 분석해봄
-
inference시, TraceVLA에 필요한 추가적인 computation은 대략 300장의 추가 이미지와 text 토큰 + 각 스텝마다 5-point CoTracker와 20 스텝마다 KxK(K=40) dense point tracking이 필요
- 20 step마다 실행하는 dense point tracking은 20으로 나눠서 1step 평균 소요 시간으로 계산
-
실험 결과, OpenVLA와 0.036초 차이로 큰 차이 없는 Inference time을 보여줌
- text, image토큰 추가는 0.0002초 차이, 5 point cotracker를 추가하면 0.03초가 더 걸림, dense poink tracking을 추가하면 평균적으로 1 step당 0.004초 정도 추가

Related works
-
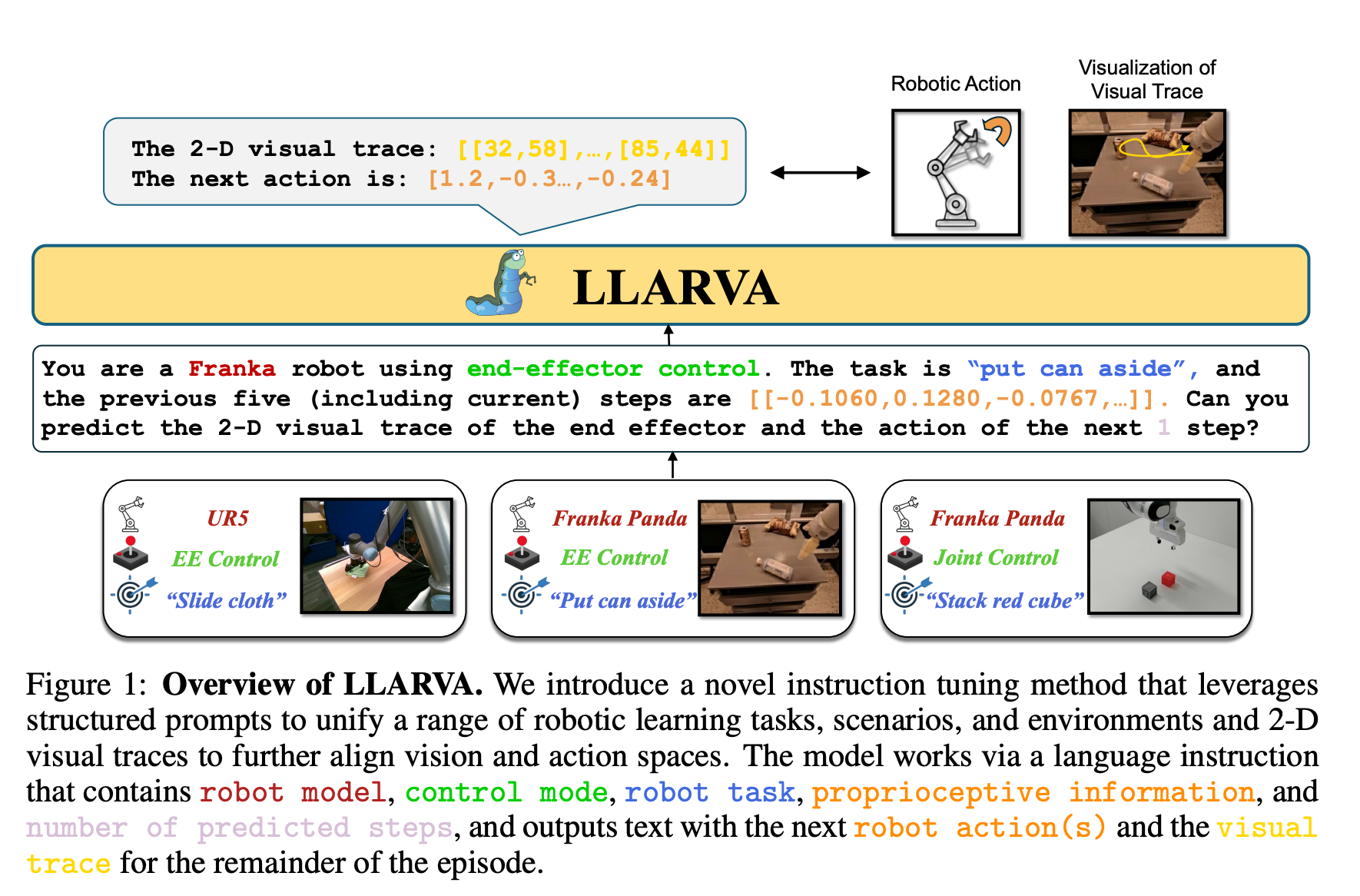
LLARVA
- image좌표에서의 2d visual trace와 상응하는 textual action을 생성하도록 함
Conclusion
-
VLA 모델이 temporal-spatial information을 잘 활용하지 못한다는 점을 해소하기 위해 visual trace prompting하는 방법론을 제안
-
7B, 4B backbone VLA 모델을 FT해서 다양한 환경에서 높은 성능을 보임