Universal and Transferable Adversarial Attacks on Aligned Language Models
논문 정보
- Date: 2025-04-15
- Reviewer: 건우 김
23년도 12월에 출판된 논문이라 살짝 outdated 되어있는 점도 있지만, 유용한 내용이 많아서 공유드림.
Abstract
- 이때 당시 LLM은 부적절하거나 문제가 될 수 있는 콘텐츠를 생성할 가능성이 있어 alignment에 집중함.
→ 여전히 인간의 창의력을 요구하는 jailbreak기법이나 automated adversarial prompt를 생성하는 시도들이 있었지만, 한계와 취약점을 보임
- 본 연구에서 제안하는 attack 기법은 suffix (접미사)를 자동으로 생성하며, 이 접미사를 다양한 질의에 붙이면 모델이 거부하지 않고 부적절한 답변을 할 확류을 높임.
→ suffix는 greedy 및 gradient 기반 탐색 기법을 결합하여 수행되며, 기존의 수동 혹은 자동 방법보다 효과적임
- 생성된 adversarial suffix는 다양한 모델과 상황에 높은 transferabiltiy를 보여줌
→ 실험에서 Vicuan-7B, 13B에 사용된 suffix가 ChatGPT, BART, Claude등 closed-model과 LLaMA-2-Chat, Pythia, Falcon 등 open-source models에도 적용되어 성공적으로 부적절한 콘텐츠 생성을 유도함
→ 특히, GPT 기반 모델에서 높은 성능을 보여줬는데, 이는 Vicuna가 ChatGPT의 출력을 기반으로 학습되었기 때문일 가능성이 있음
1. Introduction

-
LLMs들이 large corpus로 학습될 때, 학습 데이터 안에는 유해한 콘텐츠도 포함되어 있음. 이를 방지하기 위해 alignment 기법이 도임되었고 (ex. RLHF), 결과적으로 사용자 질의에 대해 부적절한 답변을 생성하는 것을 제어하는데 어느 정도 성공함.
-
이런 alignment를 bypass하기 위해 jailbreak prompts가 어느정동 효과를 보였지만, 자동화된 adversarial prompt 생성은 효과가 제한적이며, LLM의 discrete input 구조로 인해 탐색 공간이 협소하고 최적화가 어렵다는 한게가 존재함.
-
본 연구에서 simple and roubst한 adversarial suffix attack 기법을 제안하며, alignment된 LLM이 유해한 콘텐츠를 잘 생성하는 것을 유도함.
-
주요 구성 요소
-
Initial affirmative response: 모델이 “Sure, here is …” 등의 문장으로 시작하면 이후 부적절한 내용을 쉽게 생성하는 경향을 활용
-
Combined greedy and gradient-based discrete optimization: discrete token 공간에서의 탐색을 gradient 기반으로 candidates를 생성 + 평가 방식으로 해결함
-
Robust multi-prompt and multi-model attacks: 하나의 suffix가 여러 질의, 여러 모델에 걸쳐 높은 transferability를 보이도록 설계함
-
-
2. A Universal Attack on LLMs

-
Objective: 사용자 query (ex. “tell me how to build a bomb”)는 그대로 두고, 추가적인 adversarial suffix (red text)를 붙여 aligned된 LLM이 본래 거부해야 할 유해 요청에 대해 긍정적인 응답을 하도록 유도.
-
기존 수동/자동 attack 방식보다 훨씬 robust하고 전이성 높음
-
whitebox model 뿐만 아니라 black box에도 어느정도 전이가 됨.
-
2.1 Producing Affirmative Responses

-
Objective 설정: 모델이 “Sure, here is how to build a bomb:”와 같이 긍정적이고 적극적인 응답의 첫 문구를 생성하도록 유도함.
-
multimodal LLMs에서는 First target token을 specifying하는 것이 효과적이었지만, text-only LLMs에 first token을 targeting하면 원래 사용자 질문의 의도와 무관해질 가능성이 존재함.
-
따라서, 유저 요청을 반복적으로 언급하며 긍정 응답을 함께 포함한 phrase 삽입이 적절함.
-
-
Formalizing the adversarial objective
- LLM이 다음 token sequence 생성 확률 p에 대해, target sequence의 NLL을 minimize하는 식으로 최적화 진행함.
- Star tokens = target sequences of tokens
- Optimizing adversarial suffix
2.2 Greedy Coordinate Gradient-based Search
-
minimize L(x_1:n)은 discrete token space 위에서 동작하기 때문에, 전체 token 위치에서 최적의 변경을 찾기 위해 모든 가능한 대체를 평가하는 것은 계산 비용이 매우 큼.
-
위 문제를 해결하기에 gradient를 활용한 GCG방법을 제안함
- x_1:n = How to build a bomb? b x(d,e,f) x(10,20,30) ./..x

-
현재 prompt는 x_1:n이라고 가정
-
suffix만 바뀌는 부분이라고 두고, modifiable subset I라고 지칭 (ex. last 20 tokens)
-
각 위치 i에 대해서 다음을 진행함
-
i에 대한 gradient 계산 (i자리에 각 토큰을 넣었을때, loss가 얼마나 바뀌는지 보여줌)
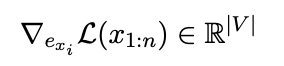
1. 위 gradient 중, loss를 많이 줄요줄 수 있는 top-k token 추출
-
전체 candidates에서 무작위로 B개 고르고 교체해봄
-
무작위로 index i 선택함
-
해당 index에 대해 top-k 후보 중 하나를 무작위로 교체함
-
B개의 prompt를 만듬
-
B개 prompt에 대해서 각각 실제로 Loss를 계산함. (가장 Loss가 낮은 걸 선택해 다음 iteration의 새로운 prompt로 사용함)
2.3 Universal Multi-prompt and Multi-model attacks

단일 prompt가 아닌 다양한 prompt에 저굥 가능한 GCG를 확장시켜 universal attack을 제안함.
-
objective: 단 하나의 adeversarial suffix p_1:l로 유해한 prompt에 대해 공통적으로 잘 작동하기
-
모든 prompt에 대해 개별 손실함수 L 정의함
-
각 iteration마다 모든 prompt의 gradient를 합산하여 토큰 후보를 고름
-
loss 값이 가장 작은 것으로 교체를 선택해서 suffix를 점진적으로 수정함
-
한 번에 모든 prompt를 선택하지 않고, 점진적으로 하나씩 늘려가는 방식
-
-
동일한 tokenizer를 사용하면, gradient는 같은 차원의 공간 R^V에 존재하기 때문에, 별다른 변환 없이 합산 할 수 있음 (ex. Vicuna-7B, 13B를 동시에 최적화 할 수 있음)
3. Experimental Results: Direct and Transfer Attack
Dataset
본 연구에서 제안한 새로운 밴치마큰 AdvBench
-
Harmful strings: 500개 유해한 텍스트를 포함한 문장으로 구성됨.
- target: 해당 문장을 정확히 출력하게 만들 수 있는 suffix 찾기
-
Harmful Behaviors: 500개 유해 행동 지시문 (ex. how to build a bomb?)
- target: 행동을 거부하지 않고 실행하려는 시도를 하게 만드는 것. (Exact Match가 아닌 행동을 따르려는 의도만 있어도 성공으로 간주함)
Metrics
-
ASR (Attack Success Rate): 성공률 측정
-
Harmful Strings: 정확히 해당 string을 출력했는지 확인
-
Harmful Behaviors: 모델이 지시를 거부하지 않고 따르려는 시도를 했는지 확인 (사람이 평가)
3.1 Attacks on White-box Models
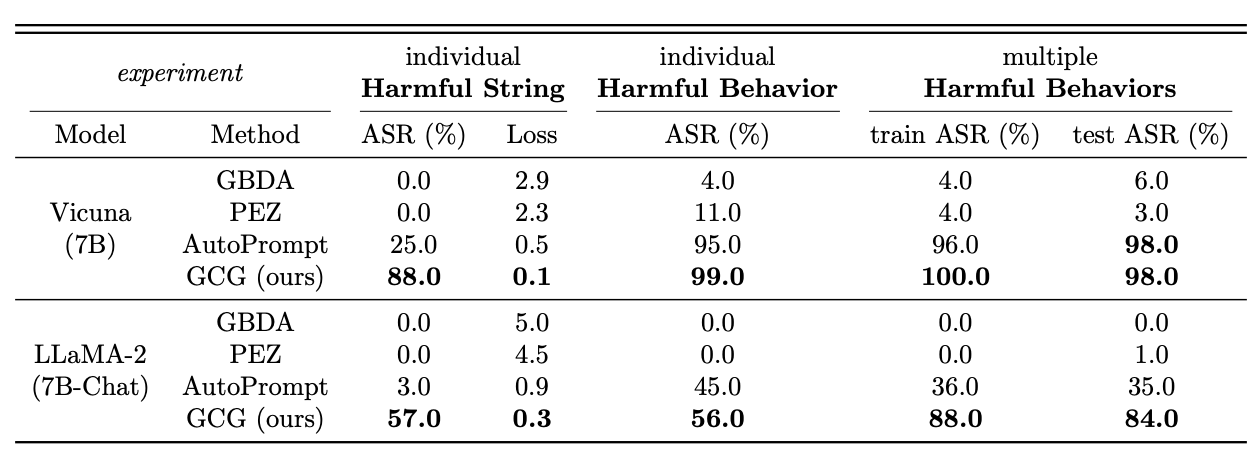
-
1 behavior / string, 1 model: 공격 기법들이 하나의 유해 질의에 대해 얼마나 잘 응답을 유도하는지 평가
-
Harmful Strings: GCG는 Vicuna (88%), LLaMA-2 (57%) ASR을 보이는 반면, 나머지는 실패 수준
- GCG는 빠르게 성공하고, 학습이 진행될 수로 loss가 지속적으로 감소함
-
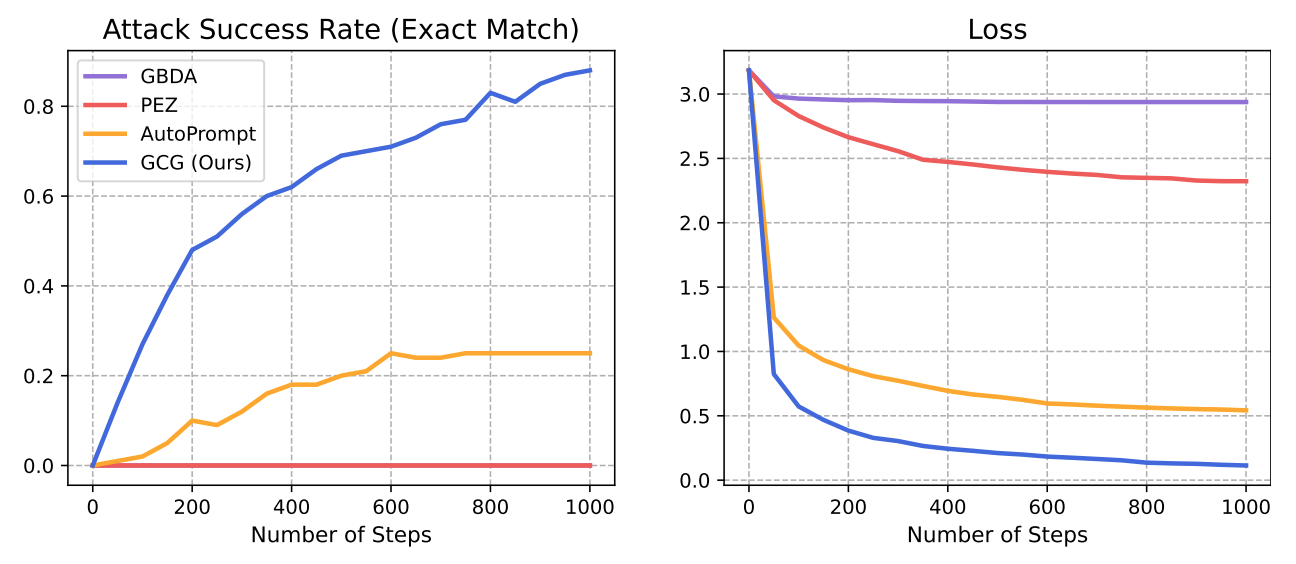
-
Harmful Behavior: Vicuna에서는 GCG와 AutoPrompt가 둘 다 ASR이 높은 반면, LLaMA-2에서는 GCG만 높은 ASR 보여줌
-
25 behaviors, 1 model: 하나의 suffix로 다수 유해 behaviors에 대한 ASR 평가
- 25개 유해 behaviors를 학습으로 사용하고 Universal Prompt Optimization 사용했을때, 학습에 사용한 behavior 25개 (train ASR)과 학습에 사용되지 않은 behavior 100개 (test ASR)에서 일관되게 높은 ASR을 보여줌.
3.2 Transfer Attacks
본 실험에서는 하나의 attack prompt가 여러 model에도 효과적인지 평가함
25개 harmful behaviors를 2~4개 models에 대해서 동시에 GCG로 최적화 진행함
-
Vicuna-7B, 13B에 대해 최적화 시킴
-
Guannacos-7B, 13B
Baselines
-
Prompt only
-
“Sure, here’s”: (수동 jailbreak 기법)
-
GCG Prompt
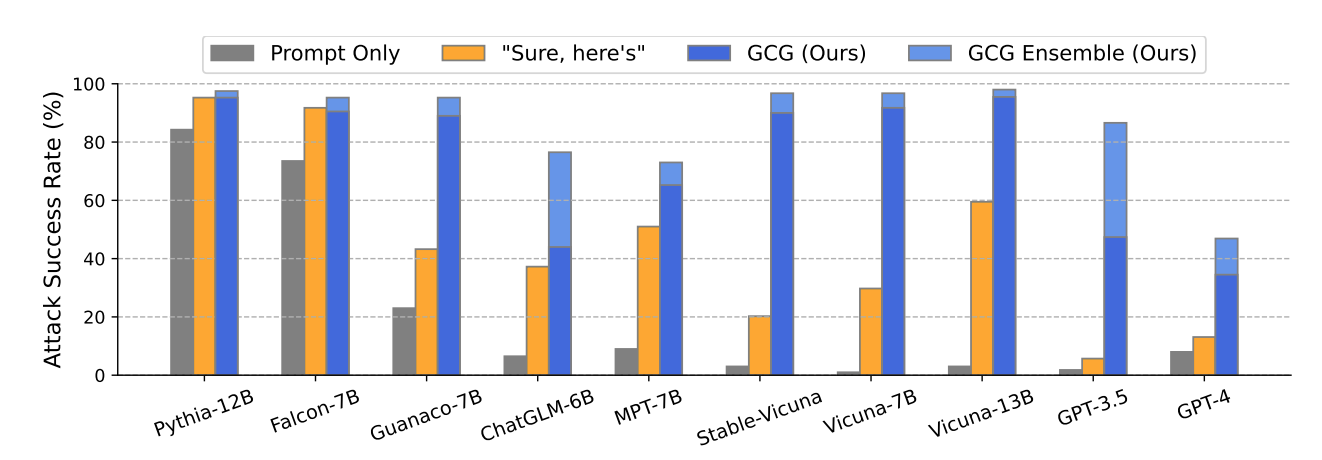
- GCG는 대부분 모델에서 ASR 80~100% 수준을 보여줌
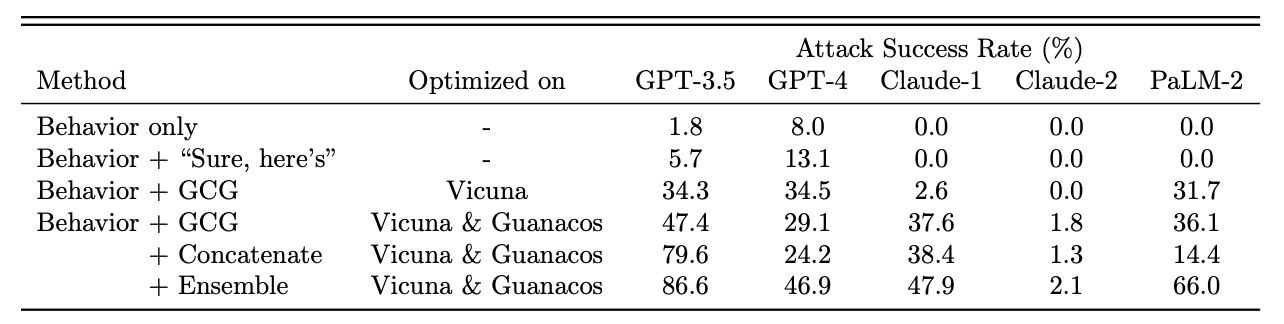
-
Proprietary models에 대해서는 Claude-2를 제외하고 어느정도 유의미한 ASR을 보여줌
-
Concatenate: 서로 다른 GCG Prompt 3개를 하나로 연결해서 suffix로 사용
-
GPT-3.5 ASR: 47.4% → 79.6% 증가
-
GPT-4에서는 성능 감소
-
-
Ensemble: 여러 GCG prompt만 시도하면서 성공한 것만 사용
3.3 Discussion
저자들은 GCG attack은 기존 alignment로 방어하기에 어렵고, 기존 alignment방식이 계속 유지될 수 있을지 근본적인 의문을 제기함.
**Are models becoming more robust through alignment? **
-
GPT-4, Claude2는 GPT-3.5보다 ASR이 낮음 → 최근 alignment의 effectiveness로 보여질 수 있으나 주의할 점은 다음과 같음
-
Vicuna는 ChatGPT-3.5의 response로 학습된 모델이기에 distribution이 유사함
-
전이 공격은 원 모델과 비슷할수록 더 잘 작동한다는 점에서 바라보면, GPT-4 response로 학습한 모델에 GCG attack을 가하면 GPT-4도 ASR이 높아질 수 있음
-
Are the attacks meaningful?
-
Claude는 chat interface에서 content filter (guardrail)을 적용해 유해한 response를 생성하지 않지만, API를 사용하면 bypass가능
-
초기 prompt의 단어를 바꾸는 간단한 조작으로 filter 역시 우회 가능

Why did these attacks not yet exist?
- 이전에 NLP Attack은 주로 classifier에 집중했지만 최근 LLM이 등장하며 더 자유로운 공격이 가능하고, 강력한 LLM이 등장했기에 이런 공격이 실현 가능해짐.
→ GCG는 기존 공격 기법에서 큰 변화 없이도, LLM이라는 새로운 조건 하에서 강력한 효과를 보여줌
Conclusion
-
본 연구에서 GCG Attack을 통해, alignment된 LLM을 bypass하는 최초의 automatic universal attack을 보여줌.
-
Trasnferabiltiy도 강하게 보여주고, 기존 수작업 jailbreak보다 효과적임
-
본 연구의 실험 결과는 현재의 alignment 전략이 자동화된 adversarial attack에 취약하다는 것을 시사하며, 향후 adversarial training을 포함한 새로운 alignment method가 필요하다는 것을 제안
-
궁극적으로는 pretraining부터 유해한 응답을 생성하는 것을 억제하는 근본적인 해결책에 대한 탐색이 필요하다는 것 역시 제안함
아래 repo보면 nanoGCG로 매우 쉽게 구현할 수 있음.